♬ doe: a deer, a female deer
♬ ray: a drop of golden sun
♬ me: a name, I call myself
♬ far: a long long way to run…
? ? ? ? ? ? ?
♬ doe: a deer, a female deer
♬ ray: a drop of golden sun
♬ me: a name, I call myself
♬ far: a long long way to run…
? ? ? ? ? ? ?

Ça dépend de la police de chacun. En gros ya juste celleux sous Mac ou qui ont personnalisé leur police par défaut, qui le voit. Non ?


@rastapopoulos sudo apt-get install ttf-ancient-fonts


@nicolasm impec, il manquait juste le mot de passe :)

#? #?
EDIT: ça ne marche pas en tag
EDIT2: ni en recherche
j’ai ouvert un ticket ►https://github.com/seenthis/seenthis_squelettes/issues/96 ?

soit tu as un clavier virtuel qui te permet de les parcourir et sélectionner, soit tu les trouves sur internet ; je trouve la liste de ►http://unicode-table.com/fr assez pratique (menu à droite pour parcourir les diverses classes)

Un nouveau moteur de recherche pour seenthis
Nous avons travaillé ces deux dernières semaines, avec @marcimat et @rastapopoulos, à la programmation d’un #moteur_de_recherche générique pour #SPIP, basé sur #Sphinx, et très adaptable à différents types de sites. En l’appliquant à #seenthis, on obtient un outil dont les caractéristiques sont assez intéressantes :
– opérateurs logiques (et, ou, non)
– recherche de mots parmi une liste
– #proximité
– des #facettes permettent par ailleurs d’affiner la recherche, en proposant des #hashtags et des @people liés aux mots demandés
– une facette de date permet de filtrer par année (2014, 2013, etc).
– enfin, on propose plusieurs tris (par pertinence, date, ou en mettant en tête de liste les messages les plus partagés)
Je vous laisse découvrir tout cela :
– le moteur lui-même : ▻http://seenthis.net/recherche
– la documentation : ►http://seenthis.net/fran%C3%A7ais/article/moteur-de-recherche
– le code d’#indexer, le plugin générique pour SPIP : ▻http://zone.spip.org/trac/spip-zone/browser/_plugins_/indexer/trunk
– le code du plugin qui l’adapte à seenthis : ▻https://github.com/seenthis/seenthis_sphinx
Commentaires et relevés de bugs sont très bienvenus.
Super bonne nouvelle : j’ai vraiment un mal de chien à retrouver d’anciens articles archivés. Merci pour votre travail.
Je viens de tester, c’est de la balle!
La recherche est sur le message ou sur le fil ?
Ça peut être intéressant de chercher des messages qui contiennent une image ou une vidéo ou qui a reçu des commentaires (dans le cas où on cherche un de nos messages et que ce sont des infos qui se retiennent bien).
Sinon une recherche sur le fil entier pour des messages qu’on recherche sur un sujet, par exemple si on cherche sur poutine et ukraine, ça peut rapporter pas mal de sujets en plus (surtout que souvent les billets sont taggés a posteriori par les autres membres)
Rechercher des fils dans lesquels des membres de seenthis ont participé ?
Bon c’est des idées en l’air, je sais pas s’il y a un réel besoin pour ça ?
La colonne de droite « follow » elle se base sur la recherche / les résultats ? Ça me met des comptes que je suis déjà en tout cas
Edit : ha non ça permet d’affiner la recherche en spécifiant un auteur, mais si j’ai fais ma recherche avec déjà un auteur, ça va sortir aucun résultat


Pas compris. J’ai essayé les # et je ne sais pas si je dois affiner les recherches parce que je me suis retrouvée dans un flux sans queue ni tête...bigre ! Je crois que je suis complètement crevée !

Je n’ai fait que quelques essais de recherche. Sans problème. L’interface est super claire et les affinages très bien venus.
Mais surtout, je vois des comptages. Alors, je n’ai pas pu m’empêcher…
Sur une entrée vide, on compte tout. Du coup, ça fait une super façon d’entrer dans les stats…
On a des unités statistiques différentes :
– pour les années, apparemment, il s’agit des billets (messages initiaux). Si tu implémentes un dépliement hiérarchique par mois, outre que ça permet de préciser le filtre chronologique (surtout utile pour l’année en cours), ça permettrait d’avoir l’activité mensuelle.
– pour les comptes (follow) et les tags, il me semble qu’il s’agit de toute l’activité (billet, commentaire, étoile)
Là aussi, peut-être un niveau hiérarchique inférieur permettrait de ventiler entre ces 3 types d’activités (ce qui permettrait de préciser quand on cherche une réponse dans une discussion)
Du coup, les totaux n’ont pas de raison de coïncider. Si mon interprétation est bonne, il y a eu (et il subsiste après effacement des comptes) 120000 billets (ça change tout le temps…) et comme le numéro du dernier est autour de 260400, cela fait de l’ordre de 1,2 « activité complémentaire » (commentaire ou étoile) par billet.
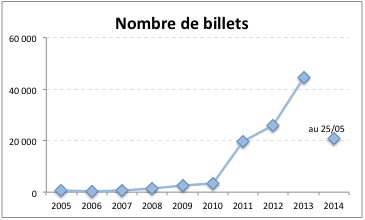
Juste pour voir, j’ai fait le suivi du nombre de billets par année.
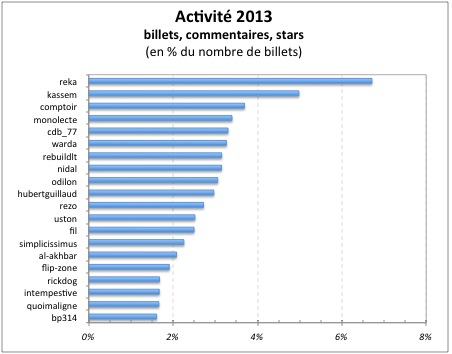
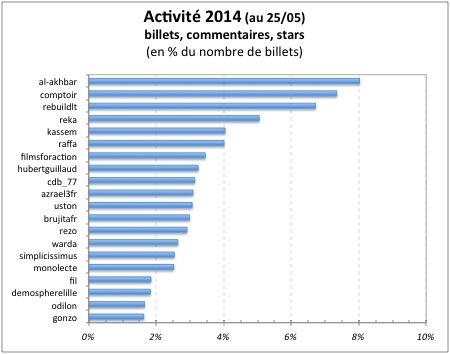
Et l’activité des top 20 (en % du nombre de billets)
(pour 2010, la somme des 20 follows fait 3548, alors que le nombre de billets est de 3520)
2013
2014
Éventuellement, un nouveau bloc par nombre « d’activité complémentaire » pour classer les billets par intensité de la discussion ou des étoiles (souhait qui a été exprimé, me semble-t-il).
Encore merci. Et bravo pour l’interface « naturelle » ou « invisible ».
Jolies déductions :)
La facette « follow » est établie sur la base de l’attribut multivalué {auteur initial + partageurs}. Les intervenants dans la discussion ne sont donc pas comptés en tant que tels (ils sont indexés dans un autre attribut, mais pas utilisés dans l’interface : l’idée est que si je ne partage pas un billet, mes suiveurs n’ont pas forcément vocation à être alertés que je suis en train d’y discuter).
Chacune des facettes, comme tu l’as constaté, est limitée aux 20 éléments ayant le plus fort effectif, et à condition qu’il soit > 1.
Le système recense à cet instant 156548 billets publiés. Il existe des billets effacés (11197 dont une trace reste dans le système, sans compter ceux de quelques tests, ou du compte machin, qui ont carrément été supprimés).
Pour ce qui est de fouiller plus avant dans les données, je pense qu’il sera plus efficace de créer des requêtes ad hoc. Le langage d’interrogation, très proche du SQL, est assez parlant.
Par exemple pour avoir le nombre de billets publiés mois par mois :SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
La même chose pour les billets qui répondent à un critère fulltext :SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where MATCH('spip') AND properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
etc.
Concernant la suggestion de trier selon l’intensité des discussions : il n’y aurait aucun obstacle technique, sachant que les éléments nécessaires (liste des participants à chaque discussion) sont déjà indexés. En revanche, il me semble qu’il s’agit d’une fausse bonne idée : j’ai comme un doute en effet sur l’intérêt de mettre en valeur des discussions qui impliqueraient de nombreuses personnes, mais qu’aucune ne souhaiterait partager…
La vocation du moteur de recherche est de permettre de trouver aussi rapidement que possible une information précise, les décisions doivent se baser uniquement là-dessus, pour cette page en tout cas. Mais l’outil permet d’imaginer d’autres « vues » sur les données, qui pourront servir à l’administration du serveur, à créer des pages annexes, à repérer des « corrélations » entre les sujets, des proximités entre auteurs, une analyse du « dictionnaire » global, et que sais-je encore. Tout un champ à explorer !
PS : la doc de SphinxQL : ▻http://sphinxsearch.com/docs/current.html#expressions
Tu sais que l’utilisateur est d’abord et avant tout pervers : il utilise les outils qu’on lui donne pour faire tout autre chose avec… Et, donc, oui je sais qu’il s’agit de recherche, pas de stats. Tavaikapa mettre des comptages.
Blague à part, en fait, je ne sais pas comment faire pour rentrer dans les tables de ST à des fins statistiques. À l’occasion (R ?), je jetterais bien un œil…

Oui @fil, pour la mise en avant des discussions « chaudes » (celles ayant le plus de participants et/ou celles ayant le plus de messages), je ne voyais pas ça spécialement dans la page de recherche. Mais dans une autre vue à part ce serait bien oui.
(Dans le même thème, un truc qui pourrait être bien, hors interface, ce serait aussi un flux Atom des commentaires postés par les gens qu’on suit.)
(une loi qui porte mon nom la classe .. ah mince c’est moi qui l’ai créée...)
Le menu pour affiner la recherche par facette semble avoir des bugs :
▻http://seenthis.net/recherche?recherche=%23permaculture+%40nicolasm+%23agriculture
– le tag agriculture n’est pas déjà coché dans le menu
– si je clique sur le tag alimentation ça me met cette url = ▻http://seenthis.net/recherche?recherche=%23agriculture&tag=%23alimentation (ça vire mon pseudo et le tag permaculture) alors que j’imaginais que ça rajoutais le tag alimentation en contrainte supplémentaire ? Même souci avec les facettes par auteur pour ▻http://seenthis.net/recherche?recherche=%23agriculture+

Ah, cool ! C’est possible d’obtenir les résultats sous forme de RSS ?

@homlett le moteur est accessible en RSS et en JSON :
▻http://seenthis.net/?page=sphinx.rss&recherche=sphinx
▻http://seenthis.net/?page=sphinx.json&recherche=sphinx
Attention c’est de la version alpha, je changerai probablement les URLs une fois que ce sera testé et stabilisé.
À noter les deux flux proposent des données complémentaires : uri, title, date, @login de l’auteur, tags et « snippet », c’est-à-dire l’extrait du contenu avec les mots repérés mis entre <b> (à styler comme tu veux, le gras rendant assez moche).
Ce qui manque je pense, à ce stade, c’est de pouvoir personnaliser (faire « mes messages » ou « messages de mon réseau » plutôt que « Tous les messages »).
En fait, j’ai beaucoup utilisé le moteur hier pour écrire mon dernier papier et je suis ravie de la facilité avec laquelle j’ai pu retrouver toutes les sources dont j’avais besoin. Souvent, j’associe deux termes pour mieux cibler ma recherche, et sans avoir besoin de me prendre la tête avec les opérateurs booléens, j’exhume très rapidement ce que je mettais des heures à chercher jusque là (et que je ne retrouvais généralement pas !). J’aime beaucoup le surlignage des termes recherchés et la possibilité de trier les résultats par date ou pertinence, de limiter par année, auteur, me ravit littéralement.
Je n’ai pas eu de bugs, pas de problème et mes requêtes ont toutes abouti.
Donc désolée de ne pas aider plus que cela, mais je suis juste la ravie de la crèche qui pensait depuis un bon moment que le gros défaut de Seenthis, c’était de ne jamais rien y retrouver !

@fil OK, c’est noté. Merci en tout cas, c’est top et ça manquait vraiment ! Par contre c’est vrai que <b> c’est moyen. Pourquoi pas un <span> ou même <em> ? Mais c’est pas très important.
En tout cas ça va permettre de faire de la veille sur #seenthis, @seenthis et seenthis ! ;-) ( ▻http://seenthis.net/messages/256466 )
Peut-être puis-je émettre un bidule qui serait bien pratique mais je ne sais pas si c’est le sujet de cette discussion. Serait-il imaginable de mettre une étoile à côté d’une réponse. Car parfois, il y a des réponses qui mériteraient d’être mentionnées dans les recherches. Voir des possibilités d’y répondre....
je ne vois pas le lien entre étoile et réponse de recherche ?
en effet c’est hors-sujet :)
pour gérer le développement de seenthis, on vient tout juste de mettre en place un compte github où vous pouvez envoyer des issues (problèmes ou demandes de fonctionnalités) et des pull-requests (des modifications du code source).
►https://github.com/seenthis

Est-ce qu’une migration vers SPIP 3 est prévue ?

Une petite amélioration du moteur : la recherche se fait désormais à partir de la racine des mots (lemmatisation) ; ainsi le moteur trouvera les messages contenant aussi bien le pluriel que le singulier, ou bien diverses formes des verbes conjugués (c’est censé fonctionner pour l’anglais et pour le français).
Si, à l’occasion, vous souhaitez rechercher la forme exacte d’un mot, utilisez l’opérateur = ; par exemple, une recherche de =terres évitera les messages contenant le mot terre au singulier seulement.
(Et pour répondre à @nhoizey : il me semble probable que les plugins seenthis fonctionnent déjà pour la plupart avec SPIP 3, je n’ai pas essayé mais je ne vois pas ce qui pourrait bloquer. Si dans tes tests tu vois des bugs, n’hésite pas à les signaler ou à envoyer une pull-request sur ►https://github.com/seenthis )


Bonjour
On m’a dit de m’adresser ici si je ne comprenais pas quelque chose.
Comme par exemple : comment faire pour afficher sur sa page personnelle un billet d’un autre utilisateur ? Il faut le mettre en favori, c’est tout ?
Je n’ai pas trouvé le bookmarklet en page d’accueil qui, paraît-il (dixit la page « le minimum à savoir »), transforme complètement le confort d’utilisation.
Merci d’avance !

Bonjour @bruno2, bienvenue !
Oui, c’est ça, pour afficher sur sa page le billet d’un autre, il suffit de le mettre en favori. C’est une fonction « repartage ».
Pour le bookmarklet, il est sur la page d’accueil ►http://seenthis.net, dans la colonne de droite, juste après À lire.
Autre question, tant que j’y suis :
Y aurait-il quelque part un badge seenthis que je pourrais coller sur mes sites perso pour guider mes visiteurs vers ma page ?
Non, on se le fabrique soi-même... #DIY
Bon, OK.
Autre question :
Pour suivre un thème, je n’ai pas trouvé d’autre moyen qu’utiliser le moteur de recherche, chercher le thème avec le # dans la page et cliquer dessus, puis ensuite faire « suivre le thème ».
Il n’y a pas moyen de faire plus simple ?
Fondamentalement plus simple, je vois pas comment. Mais il y a un lien « thèmes » dans le bandeau du haut, vers ►http://seenthis.net/tags avec la liste des thèmes/tags suivis.
Tu peux aussi directement taper l’url http://seenthis.net/tag/THEME_EN_QUESTION
À savoir : si par exemple tu suis le thème #seenthis, tu suis avec ses sous-thèmes : #seenthis_doc, #seenthis_todo, etc. Mais bien sûr, pas l’inverse.
Autre chose : devant chaque liens partagés, il y a un triangle. S’il est blanc, l’url n’a été partagée qu’une fois. S’il est noir, l’url a été partagée plusieurs fois. Et un clic sur le triangle renvoi vers la liste de tous les posts où elle apparait.
Last but not least, la mise en forme :
– du gras en encadrant avec le signe *
– de l’italique avec le signe _
– du code avec le signe `
– des citations avec Shift+Tab
Quand tu es connecté, tu ne vois que ceux auxquels tu es abonné. Sinon, tu vois les posts de tout le monde.
Pour voir les postes de tout le monde quand tu es connecté, c’est ►http://seenthis.net/all
Sauf que cette page « all » n’est liée nulle part, et que donc personne ne peut la deviner, nouveau ou pas (moi-même je ne m’en souvenais plus).

Bonjour et #merci,
J’utilise la recherche avec recherche ?annee=2016&order=stars
J’aimerais pouvoir ajouter quelque chose comme &moisdelannee=2
Y-a-t-il une syntaxe adaptée à ce désir ?
Pour le moment non, et je me demande si ça ne serait pas plutôt quelque chose comme date=2016-02 qu’il faudrait faire. À discuter sur ►https://github.com/seenthis/seenthis_squelettes/issues ?

Quelques #seenthis_nouveautés :
– Modification du critère {follow}
Ceci permet de limiter la recherche (plein texte, dans les tags ou dans les sites) aux messages d’un autre utilisateur :
<►http://seenthis.net/tags/sant%C3%A9?follow=fil>
<►http://seenthis.net/tags/sant%C3%A9?follow=odilon>
A noter : comme toujours, les messages « de quelqu’un » comprennent aussi ceux qu’il a mis en favori.
– Ajout d’un début d’#API de recherche d’URL :
Pour demander à #seenthis s’il connaît une URL donnée, on envoie son md5, par exemple :
<►http://seenthis.net/api/url/1ec6743420344d1c1c6845d23a707033>
On reçoit alors un JSON qui rappelle l’URL (en clair), et donne la liste des identifiants de messages. (A noter : le passage par md5 permet de maintenir la confidentialité des URLs qu’on teste. C’est aussi comme ça que procède delicious.)
– Correction du bug des chevrons
ce qui permet de rentrer dans la norme #RFC 3986, annexe C ; le bug avait été signalé par @stephane :
<►http://seenthis.net/messages/56237>
– Notifications inutiles :
éviter d’envoyer un mail de notification d’une nouvelle réponse à l’auteur de la-dite réponse
– Copier/coller :
les URLs d’images peuvent être récupérées par copier/coller


Gaffe, ça met en frontal des choses qui sont lourdes et hors cache. Un lien hypertexte la-dessus et mon serveur s’effondre. Les « follow » précédents étant liés à la session, il n’y avait pas ce risque. Pour l’accès API hors identification et hors cache, même problème.
Pourquoi est-ce hors du cache ?
En ce qui concerne l’API, il me semble que c’est une brique élémentaire, il faudra en effet qu’elle soit optimisée pour supporter des accès fréquents, avec un index ou un arbre des hash connus. Mais ça ne semble pas bloquant car elle répond encore très très vite.

« Préserver la confidentialité des URL qu’on cherche ? » Vis-à-vis de qui ? Pas vis-à-vis de SeenThis, qui peut garder une liste de tous ses URL avec leur MD5. (Le « ses » est important, cf. réponse @Fil.)
Hmmm, la recherche d’URL qui renvoie du JSON alors que les autres méthodes renvoient du XML... Pas super-cohérent.
J’ai mis en œuvre la fonction de recherche d’URL dans #seenthis-python ►https://github.com/bortzmeyer/seenthis-python Pour les curieux, le commit exact est ►https://github.com/bortzmeyer/seenthis-python/commit/f18d6ea23bcba042a98396e3367a85b2d8ef141f
On peut utiliser la bibliothèque dans ses programmes ou simplement se servir du nouveau script seenthis-test-url.py, par exemple « seenthis-test-url.py URL » pour voir si un URL existe (l’option -n permet de ne voir au contraire que ceux qui n’existent pas dans SeenThis). Pour tester une longue liste (attention, ça rame, plus d’une heure pour tester 4 000 URLs), « seenthis-test-url.py $(cat FICHIER-CONTENANT-LES-URL) ».
Ça m’a permis de savoir que seuls 114 des 4313 URLs cités sur mon blog étaient dans SeenThis :-) La commande était "seenthis-test-url.py $(psql —field-separator ’ ’ —tuples-only —no-align -c « SELECT url FROM Blog.Links ; » blog) | wc -l".

Bordel, les gars, je comprends rien. On commence où pour connaître tous les trucs et astuces ? :-)

@davduf SeenThis, ce n’est pas un rézosocio professionnel qui distribue sa base de mots de passe aux pastebins russes et qui vend les données personnelles de ses membres. C’est un projet individuel dont l’auteur s’occupe quand il a le temps. Question doc’, n’y a pas de point d’entrée unique et à jour.
Après, les questions précises sont les bienvenues :-)
Bien sûr Stéphane ,-) En fait, j’avais souvenir qu’on pouvait retrouver facilement ses #hashtags (genre complétion automatique) mais je ne le retrouve pas...
Merci pour tout !
Non, y’a pas de complétion automatique pour le moment. En revanche, la liste de tes hashtags habituels, elle est en colonne de droite de ta page à toi :
►http://seenthis.net/people/davduf
Au cas où tu n’étais pas dans le coin quand j’ai ajouté le bouton : tout en bas de ta liste de hashtags, tu as un bouton « Wordle ». C’est très mignon pour voir de quoi tu causes ici.
Ah, oui, « Wordle », c’est trés zoli.
Pour les hashtags habituels, hélas, je ne les vois pas quand j’utilise le bookmarklet... C’est le petit problème, je trouve :-)
Je cherche pas mal, suis obligé de modifier, etc.
C’est pas grave hein, mais je crois vraiment que des hashtags plus simples à utiliser serait vraiment un truc top.
Et pour le reste, bravo !
alors qu’on reçoive plus de mail pour notifier qu’on a contribué à un de ses billets c’est parfait. Par contre, je ne reçois plus de mail me notifiant la contribution des autres seenthisiens sur des billets que je partage, ça c’est dommage je trouve