

How we improved #tensorflow Serving #performance by over 70%
▻https://hackernoon.com/how-we-improved-tensorflow-serving-performance-by-over-70-f21b5dad2d98?s
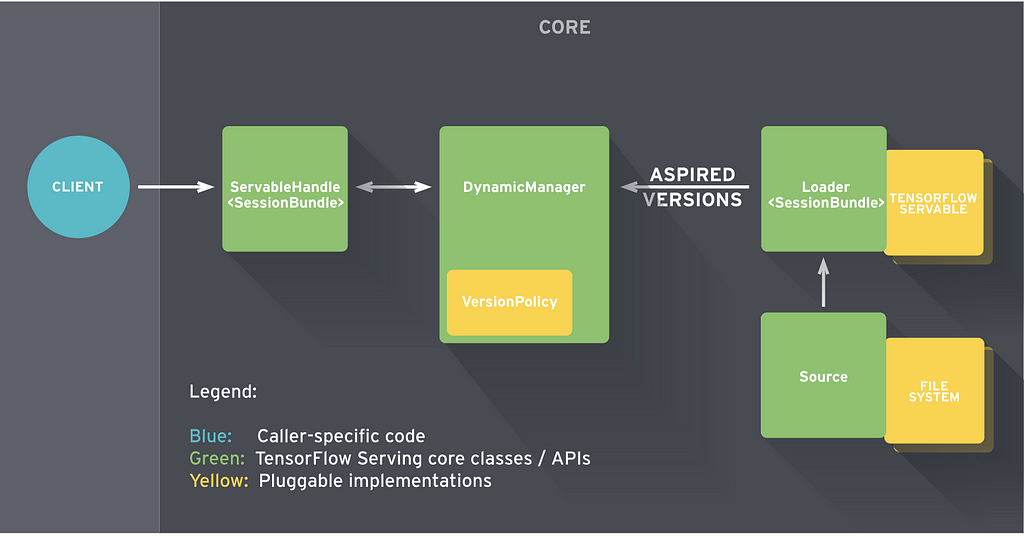
Tensorflow has grown to be the de facto ML platform, popular within both industry and research. The demand and support for Tensorflow has contributed to host of OSS libraries, tools and frameworks around training and serving ML models. The Tensorflow Serving is a project built to focus on the inference aspect for serving ML models in a distributed, production environment.Mux uses Tensorflow Serving in several parts of its infrastructure, and we’ve previously discussed using Tensorflow Serving to power our per-title-encoding feature. Today, we’ll focus on techniques that improve latency by optimizing both the prediction server and client. Model predictions are usually “online” operations (on critical application request path), thus our primary optimization objectives are to handle high (...)