Qui saurait svp m’expliquer comment fonctionne le petit bouton « traduire » qui apparaît sur les messages #seenthis en anglais ?
Qui saurait svp m’expliquer comment fonctionne le petit bouton « traduire » qui apparaît sur les messages #seenthis en anglais ?

Le bouton fait une requête POST vers : http://seenthis.net/index.php?page=translate avec trois paramètres supplémentaires contenu, dest et source, respectivement le contenu à traduire, la langue de destination (par exemple fr) et la langue source (par exemple en).
Quand à savoir comment fonctionne exactement http://seenthis.net/index.php?page=translate il faut chercher dans le code source de #Seenthis disponible sur :
►https://github.com/seenthis
J’ai pas trouvé mais je suppose que c’est un relai vers l’API Google Translate :
▻https://developers.google.com/translate
(Je sais pas si je réponds vraiment à la question)

le filtre se trouve dans ▻https://github.com/seenthis/seenthis_squelettes/blob/master/php/traduire_texte.php
maintenant en plugin séparé sur la zone
▻https://zone.spip.org/trac/spip-zone/browser/_plugins_/traduire_texte

J’ai un bug énorme dans la fonction imageconvolution de PHP en version 5.5.9 et 5.5.10, et qui n’a pas l’air documentée :
▻http://php.net/manual/en/function.imageconvolution.php
la troisième variable de la fonction, le divisor, ne semble plus fonctionner que si sa valeur est 1.
J’ai donc modifié la fonction image_reduire_net de mon #plugin #SPIP image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
– je recalcule la matrice pour que sa somme soit égale à 1 ;
– au passage, la fonction est passée dans un fichier séparé, ce qui permet de l’appeler en dehors du fichier d’action.
Je n’ai rigoureusement rien trouvé à ce sujet, sauf un bug signalé dans un Git, comme quoi son renforcement en 5.5.9 devenait un blur. Chez moi, comme j’ai des valeurs différentes, ça me brûlait mes vignettes.
(Bon, soit c’est mon MAMP qui est bugué, soit c’est le problème classique avec les fonctions graphiques : personne dans le libre ne les utilise jamais.)
Par ailleurs, modif dans image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
J’introduis un script jquery.smartresize.jsdestiné à déclencher « intelligemment » les scripts au redimensionnement de l’écran (le .resize() de jQuery ayant des comportements non constants).
Je ne suis pas certain que ce soit une bonne idée de mettre ça là, peut-être qu’une lib serait plus adaptée, peut-être qu’il y a déjà quelque chose dans SPIP (dans jquery-ui peut-être) ? Bon, en tout cas ça ne change rigoureusement rien au comportement du plugin, sauf si on a déjà par ailleurs un smartresize du même nom.
Mise à jour de mon plugin image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Le plugin est désormais actif dans l’espace privé. Ça ne devient réellement intéressant pour l’instant que si on utilise des modèles d’insertion des images adaptés au responsive (sinon ça ne fait rien dans l’espace privé…)


Un nouveau moteur de recherche pour seenthis
Nous avons travaillé ces deux dernières semaines, avec @marcimat et @rastapopoulos, à la programmation d’un #moteur_de_recherche générique pour #SPIP, basé sur #Sphinx, et très adaptable à différents types de sites. En l’appliquant à #seenthis, on obtient un outil dont les caractéristiques sont assez intéressantes :
– opérateurs logiques (et, ou, non)
– recherche de mots parmi une liste
– #proximité
– des #facettes permettent par ailleurs d’affiner la recherche, en proposant des #hashtags et des @people liés aux mots demandés
– une facette de date permet de filtrer par année (2014, 2013, etc).
– enfin, on propose plusieurs tris (par pertinence, date, ou en mettant en tête de liste les messages les plus partagés)
Je vous laisse découvrir tout cela :
– le moteur lui-même : ▻http://seenthis.net/recherche
– la documentation : ►http://seenthis.net/fran%C3%A7ais/article/moteur-de-recherche
– le code d’#indexer, le plugin générique pour SPIP : ▻http://zone.spip.org/trac/spip-zone/browser/_plugins_/indexer/trunk
– le code du plugin qui l’adapte à seenthis : ▻https://github.com/seenthis/seenthis_sphinx
Commentaires et relevés de bugs sont très bienvenus.

Super bonne nouvelle : j’ai vraiment un mal de chien à retrouver d’anciens articles archivés. Merci pour votre travail.
Je viens de tester, c’est de la balle!

La recherche est sur le message ou sur le fil ?
Ça peut être intéressant de chercher des messages qui contiennent une image ou une vidéo ou qui a reçu des commentaires (dans le cas où on cherche un de nos messages et que ce sont des infos qui se retiennent bien).
Sinon une recherche sur le fil entier pour des messages qu’on recherche sur un sujet, par exemple si on cherche sur poutine et ukraine, ça peut rapporter pas mal de sujets en plus (surtout que souvent les billets sont taggés a posteriori par les autres membres)
Rechercher des fils dans lesquels des membres de seenthis ont participé ?
Bon c’est des idées en l’air, je sais pas s’il y a un réel besoin pour ça ?
La colonne de droite « follow » elle se base sur la recherche / les résultats ? Ça me met des comptes que je suis déjà en tout cas
Edit : ha non ça permet d’affiner la recherche en spécifiant un auteur, mais si j’ai fais ma recherche avec déjà un auteur, ça va sortir aucun résultat


Pas compris. J’ai essayé les # et je ne sais pas si je dois affiner les recherches parce que je me suis retrouvée dans un flux sans queue ni tête...bigre ! Je crois que je suis complètement crevée !


Je n’ai fait que quelques essais de recherche. Sans problème. L’interface est super claire et les affinages très bien venus.
Mais surtout, je vois des comptages. Alors, je n’ai pas pu m’empêcher…
Sur une entrée vide, on compte tout. Du coup, ça fait une super façon d’entrer dans les stats…
On a des unités statistiques différentes :
– pour les années, apparemment, il s’agit des billets (messages initiaux). Si tu implémentes un dépliement hiérarchique par mois, outre que ça permet de préciser le filtre chronologique (surtout utile pour l’année en cours), ça permettrait d’avoir l’activité mensuelle.
– pour les comptes (follow) et les tags, il me semble qu’il s’agit de toute l’activité (billet, commentaire, étoile)
Là aussi, peut-être un niveau hiérarchique inférieur permettrait de ventiler entre ces 3 types d’activités (ce qui permettrait de préciser quand on cherche une réponse dans une discussion)
Du coup, les totaux n’ont pas de raison de coïncider. Si mon interprétation est bonne, il y a eu (et il subsiste après effacement des comptes) 120000 billets (ça change tout le temps…) et comme le numéro du dernier est autour de 260400, cela fait de l’ordre de 1,2 « activité complémentaire » (commentaire ou étoile) par billet.
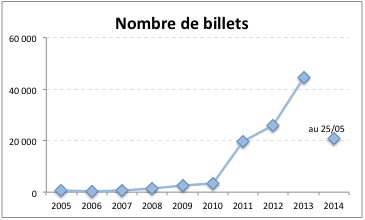
Juste pour voir, j’ai fait le suivi du nombre de billets par année.
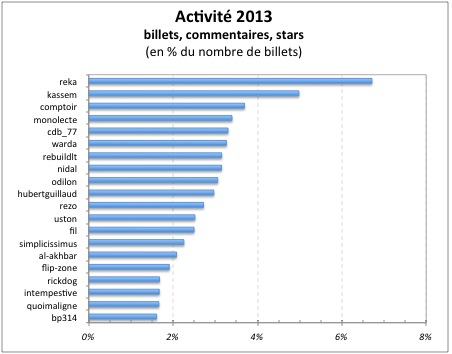
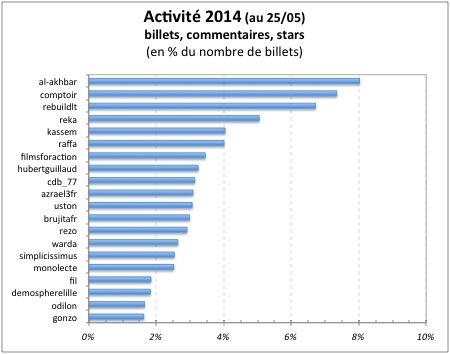
Et l’activité des top 20 (en % du nombre de billets)
(pour 2010, la somme des 20 follows fait 3548, alors que le nombre de billets est de 3520)
2013
2014
Éventuellement, un nouveau bloc par nombre « d’activité complémentaire » pour classer les billets par intensité de la discussion ou des étoiles (souhait qui a été exprimé, me semble-t-il).
Encore merci. Et bravo pour l’interface « naturelle » ou « invisible ».
Jolies déductions :)
La facette « follow » est établie sur la base de l’attribut multivalué {auteur initial + partageurs}. Les intervenants dans la discussion ne sont donc pas comptés en tant que tels (ils sont indexés dans un autre attribut, mais pas utilisés dans l’interface : l’idée est que si je ne partage pas un billet, mes suiveurs n’ont pas forcément vocation à être alertés que je suis en train d’y discuter).
Chacune des facettes, comme tu l’as constaté, est limitée aux 20 éléments ayant le plus fort effectif, et à condition qu’il soit > 1.
Le système recense à cet instant 156548 billets publiés. Il existe des billets effacés (11197 dont une trace reste dans le système, sans compter ceux de quelques tests, ou du compte machin, qui ont carrément été supprimés).
Pour ce qui est de fouiller plus avant dans les données, je pense qu’il sera plus efficace de créer des requêtes ad hoc. Le langage d’interrogation, très proche du SQL, est assez parlant.
Par exemple pour avoir le nombre de billets publiés mois par mois :SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
La même chose pour les billets qui répondent à un critère fulltext :SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where MATCH('spip') AND properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
etc.
Concernant la suggestion de trier selon l’intensité des discussions : il n’y aurait aucun obstacle technique, sachant que les éléments nécessaires (liste des participants à chaque discussion) sont déjà indexés. En revanche, il me semble qu’il s’agit d’une fausse bonne idée : j’ai comme un doute en effet sur l’intérêt de mettre en valeur des discussions qui impliqueraient de nombreuses personnes, mais qu’aucune ne souhaiterait partager…
La vocation du moteur de recherche est de permettre de trouver aussi rapidement que possible une information précise, les décisions doivent se baser uniquement là-dessus, pour cette page en tout cas. Mais l’outil permet d’imaginer d’autres « vues » sur les données, qui pourront servir à l’administration du serveur, à créer des pages annexes, à repérer des « corrélations » entre les sujets, des proximités entre auteurs, une analyse du « dictionnaire » global, et que sais-je encore. Tout un champ à explorer !
PS : la doc de SphinxQL : ▻http://sphinxsearch.com/docs/current.html#expressions
Tu sais que l’utilisateur est d’abord et avant tout pervers : il utilise les outils qu’on lui donne pour faire tout autre chose avec… Et, donc, oui je sais qu’il s’agit de recherche, pas de stats. Tavaikapa mettre des comptages.
Blague à part, en fait, je ne sais pas comment faire pour rentrer dans les tables de ST à des fins statistiques. À l’occasion (R ?), je jetterais bien un œil…


Oui @fil, pour la mise en avant des discussions « chaudes » (celles ayant le plus de participants et/ou celles ayant le plus de messages), je ne voyais pas ça spécialement dans la page de recherche. Mais dans une autre vue à part ce serait bien oui.
(Dans le même thème, un truc qui pourrait être bien, hors interface, ce serait aussi un flux Atom des commentaires postés par les gens qu’on suit.)
(une loi qui porte mon nom la classe .. ah mince c’est moi qui l’ai créée...)
Le menu pour affiner la recherche par facette semble avoir des bugs :
▻http://seenthis.net/recherche?recherche=%23permaculture+%40nicolasm+%23agriculture
– le tag agriculture n’est pas déjà coché dans le menu
– si je clique sur le tag alimentation ça me met cette url = ▻http://seenthis.net/recherche?recherche=%23agriculture&tag=%23alimentation (ça vire mon pseudo et le tag permaculture) alors que j’imaginais que ça rajoutais le tag alimentation en contrainte supplémentaire ? Même souci avec les facettes par auteur pour ▻http://seenthis.net/recherche?recherche=%23agriculture+
Ah, cool ! C’est possible d’obtenir les résultats sous forme de RSS ?

@homlett le moteur est accessible en RSS et en JSON :
▻http://seenthis.net/?page=sphinx.rss&recherche=sphinx
▻http://seenthis.net/?page=sphinx.json&recherche=sphinx
Attention c’est de la version alpha, je changerai probablement les URLs une fois que ce sera testé et stabilisé.
À noter les deux flux proposent des données complémentaires : uri, title, date, @login de l’auteur, tags et « snippet », c’est-à-dire l’extrait du contenu avec les mots repérés mis entre <b> (à styler comme tu veux, le gras rendant assez moche).
Ce qui manque je pense, à ce stade, c’est de pouvoir personnaliser (faire « mes messages » ou « messages de mon réseau » plutôt que « Tous les messages »).
En fait, j’ai beaucoup utilisé le moteur hier pour écrire mon dernier papier et je suis ravie de la facilité avec laquelle j’ai pu retrouver toutes les sources dont j’avais besoin. Souvent, j’associe deux termes pour mieux cibler ma recherche, et sans avoir besoin de me prendre la tête avec les opérateurs booléens, j’exhume très rapidement ce que je mettais des heures à chercher jusque là (et que je ne retrouvais généralement pas !). J’aime beaucoup le surlignage des termes recherchés et la possibilité de trier les résultats par date ou pertinence, de limiter par année, auteur, me ravit littéralement.
Je n’ai pas eu de bugs, pas de problème et mes requêtes ont toutes abouti.
Donc désolée de ne pas aider plus que cela, mais je suis juste la ravie de la crèche qui pensait depuis un bon moment que le gros défaut de Seenthis, c’était de ne jamais rien y retrouver !

@fil OK, c’est noté. Merci en tout cas, c’est top et ça manquait vraiment ! Par contre c’est vrai que <b> c’est moyen. Pourquoi pas un <span> ou même <em> ? Mais c’est pas très important.
En tout cas ça va permettre de faire de la veille sur #seenthis, @seenthis et seenthis ! ;-) ( ▻http://seenthis.net/messages/256466 )
Peut-être puis-je émettre un bidule qui serait bien pratique mais je ne sais pas si c’est le sujet de cette discussion. Serait-il imaginable de mettre une étoile à côté d’une réponse. Car parfois, il y a des réponses qui mériteraient d’être mentionnées dans les recherches. Voir des possibilités d’y répondre....
je ne vois pas le lien entre étoile et réponse de recherche ?
en effet c’est hors-sujet :)
pour gérer le développement de seenthis, on vient tout juste de mettre en place un compte github où vous pouvez envoyer des issues (problèmes ou demandes de fonctionnalités) et des pull-requests (des modifications du code source).
►https://github.com/seenthis

Est-ce qu’une migration vers SPIP 3 est prévue ?

Une petite amélioration du moteur : la recherche se fait désormais à partir de la racine des mots (lemmatisation) ; ainsi le moteur trouvera les messages contenant aussi bien le pluriel que le singulier, ou bien diverses formes des verbes conjugués (c’est censé fonctionner pour l’anglais et pour le français).
Si, à l’occasion, vous souhaitez rechercher la forme exacte d’un mot, utilisez l’opérateur = ; par exemple, une recherche de =terres évitera les messages contenant le mot terre au singulier seulement.
(Et pour répondre à @nhoizey : il me semble probable que les plugins seenthis fonctionnent déjà pour la plupart avec SPIP 3, je n’ai pas essayé mais je ne vois pas ce qui pourrait bloquer. Si dans tes tests tu vois des bugs, n’hésite pas à les signaler ou à envoyer une pull-request sur ►https://github.com/seenthis )


Bonjour
On m’a dit de m’adresser ici si je ne comprenais pas quelque chose.
Comme par exemple : comment faire pour afficher sur sa page personnelle un billet d’un autre utilisateur ? Il faut le mettre en favori, c’est tout ?
Je n’ai pas trouvé le bookmarklet en page d’accueil qui, paraît-il (dixit la page « le minimum à savoir »), transforme complètement le confort d’utilisation.
Merci d’avance !

Bonjour @bruno2, bienvenue !
Oui, c’est ça, pour afficher sur sa page le billet d’un autre, il suffit de le mettre en favori. C’est une fonction « repartage ».
Pour le bookmarklet, il est sur la page d’accueil ►http://seenthis.net, dans la colonne de droite, juste après À lire.
Autre question, tant que j’y suis :
Y aurait-il quelque part un badge seenthis que je pourrais coller sur mes sites perso pour guider mes visiteurs vers ma page ?
Non, on se le fabrique soi-même... #DIY
Bon, OK.
Autre question :
Pour suivre un thème, je n’ai pas trouvé d’autre moyen qu’utiliser le moteur de recherche, chercher le thème avec le # dans la page et cliquer dessus, puis ensuite faire « suivre le thème ».
Il n’y a pas moyen de faire plus simple ?
Fondamentalement plus simple, je vois pas comment. Mais il y a un lien « thèmes » dans le bandeau du haut, vers ►http://seenthis.net/tags avec la liste des thèmes/tags suivis.
Tu peux aussi directement taper l’url http://seenthis.net/tag/THEME_EN_QUESTION
À savoir : si par exemple tu suis le thème #seenthis, tu suis avec ses sous-thèmes : #seenthis_doc, #seenthis_todo, etc. Mais bien sûr, pas l’inverse.
Autre chose : devant chaque liens partagés, il y a un triangle. S’il est blanc, l’url n’a été partagée qu’une fois. S’il est noir, l’url a été partagée plusieurs fois. Et un clic sur le triangle renvoi vers la liste de tous les posts où elle apparait.
Last but not least, la mise en forme :
– du gras en encadrant avec le signe *
– de l’italique avec le signe _
– du code avec le signe `
– des citations avec Shift+Tab
Quand tu es connecté, tu ne vois que ceux auxquels tu es abonné. Sinon, tu vois les posts de tout le monde.
Pour voir les postes de tout le monde quand tu es connecté, c’est ►http://seenthis.net/all
Sauf que cette page « all » n’est liée nulle part, et que donc personne ne peut la deviner, nouveau ou pas (moi-même je ne m’en souvenais plus).

Bonjour et #merci,
J’utilise la recherche avec recherche ?annee=2016&order=stars
J’aimerais pouvoir ajouter quelque chose comme &moisdelannee=2
Y-a-t-il une syntaxe adaptée à ce désir ?
Pour le moment non, et je me demande si ça ne serait pas plutôt quelque chose comme date=2016-02 qu’il faudrait faire. À discuter sur ►https://github.com/seenthis/seenthis_squelettes/issues ?
Nous venons de lancer le nouveau site de l’Adresse, Musée de la Poste réalisé avec Mosquito :
▻http://www.ladressemuseedelaposte.fr
C’est comme toujours du #SPIP, #HTML5, #responsive.
– Le site utilise les nouvelles fonctionnalités que j’ai développées pour le #plugin image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
En particulier la définition de valeurs de largeur prédéfinies, pour éviter de fabriquer quelques centaines d’images. Le site a, à plusieurs endroits, des images qui occupent toute la largeur de l’écran ; donc il faut éviter de fabriquer avec le plugin autant de versions de l’image que de largeurs de la fenêtre d’affichage.
J’avais documenté ça là :
▻http://seenthis.net/messages/223187
– L’une des originalités du site est la possibilité de présenter le contenu d’une rubrique sous forme dite de « longform » ou de parallaxe. C’est-à-dire une de ces longues pages regroupant toute l’information sur page unique, avec un long scroll, tout en essayant graphiquement de rendre la consultation d’une longue page aussi attractive que plusieurs pages normales. Par exemple, les « 10 objects phares du musée » :
▻http://www.ladressemuseedelaposte.fr/Les-10-objets-phares-16
Les grandes images qui rythment la page, avec l’effet de parallaxe, ce sont les logos des articles de cette rubrique.
Les images de la page se chargent au fur et à mesure du scroll, simplement en utilisant l’option « lazy load » du plugin image_responsive. C’est bien pratique…
Pour la gestion du parallaxe, j’utilise le plugin jquery skrollr. J’avais indiqué il y a quelques temps comment rendre skrollr compatible avec le lazy load de image_responsive :
▻http://seenthis.net/messages/204550
– Enfin, comme c’est du SPIP, je peux intégrer facilement dans les pages longform les éléments que j’inclus habituellement dans un tel site. Voir par exemple ici :
▻http://www.ladressemuseedelaposte.fr/La-tete-dans-les-nuages
Il y a donc une colonne principe « à gauche » et une colonne d’informations spécifiques « à droite », on peut intégrer un calendrier, et évidemment un portfolio.
– Sinon, on a fait une présentation plutôt spectaculaire des vidéos embeddées :
▻http://www.ladressemuseedelaposte.fr/Pilatre-du-Rozier
et aussi une grande carte d’accès bien maousse :
▻http://www.ladressemuseedelaposte.fr/Travaux-Acces-Tarifs
– Enfin, j’ai récupéré le contenu d’un Wordpress préexistant pour réaliser la rubrique « Le Blog » (qui se gère désormais dans SPIP) :
▻http://www.ladressemuseedelaposte.fr/Le-Blog-48
J’avais fait un squelette dans SPIP permettant de récupérer le contenu d’un site Wordpress, livré ici :
▻http://seenthis.net/messages/213240

Sympa, tu devrais peut-être désactiver le zoom à la molette sur la page de la carte car comme celle-ci prend toute la largeur, elle « capture » le scroll quand on veut faire défiler la page.
Super,
par contre chez moi à partir de 1001px, je ne vois pas le menu principal en entier, il est toujours coupé. Et pourtant je suis en 1600 de large (la police est très grosse).
À 1001 ça s’arrête à « Programme », et en 1600 ça atteint « Bouti ». :)

Chez moi aussi le menu boutique n’est visible qu’en partie sur la page d’accueil même en écran large. Autrement chapeau, c’est très réussi :-)
Merci pour les explications sur les plugins SPIP utilisés.
(FF 27.0.1 sous Linux)
Ah oui, c’est corrigé. C’était à cause du changement de nom de domaine, alors que les CSS étaient encore calculées depuis l’ancienne URL. Et Firefox n’accepte pas de charger les webfonts depuis un autre domaine.
Amélioration de mon #plugin #SPIP image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Il s’agit ici de limiter l’effet de « redraw » au chargement de la page. Le plugin, en effet, fait que la page se charge et s’affiche une première fois, avant de charger les images. Et pendant ce temps, la page est calculée et affichée en supposant que les images sont carrées. Du coup, après ce premier affichage de la page sans les images responsives, on se retrouve avec un « redraw » (la page est redessinée) durant lequel on « voit » nettement qu’il se passe quelque chose, puisque les éléments de texte (tout ce qui est hors images responsive, en fait) se déplacent. Le redessin de la page est donc très visible. Par ailleurs, dans le cas où il y a une vignette de prévisualisation avant le chargement de l’image complète, du fait des différences d’arrondi entre les trailles d’images, il n’est pas rare d’avoir alors un petit effet de bougé sur… 1 pixel.
De plus, cet effet de redraw visible se produit même quand on revient sur la page (dont l’ensemble est déjà en cache), puisque le principe même du plugin est qu’on redessinne la page forcément après l’avoir dessinée une première fois.
Dans le cas où l’on avait pas de vignette de prévisualisation (on charge le carré « rien.gif »), le javascript du plugin limitait les dégâts en « forçant » les dimensions des images contenant rien.gif, mais on avait quand même un effet de « bougé » après le premier affichage.
Pour moi, c’était le principal défaut de cette façon de réaliser des images responsives.
L’amélioration du jour s’applique de manière transparente pour le webmestre (il suffit de faire la mise à jour du plugin et de recalculer les pages - attention, recalculer aussi les CSS). Pour les images_responsive classiques (pas les nouvelles, verticales, que j’ai introduites dans la précédente mise à jour), la balise <img> est désormais intégrée à l’intérieur d’un <span>. L’image, elle, passe alors en position absolue à l’intérieur du spam, qui définit les dimensions de l’image.
Et comme on fait pour qu’un <span> adopte les proportions de l’image tout en restant responsive ? Avec la technique tirée de « Fluid Width Video » :
►http://css-tricks.com/NetMag/FluidWidthVideo/Article-FluidWidthVideo.php
Le span a une largeur de 100%, une hauteur de 0. Sa hauteur est définie précisément par un padding-bottom, qui est la proportion (par exemple 50% pour une image qui serait deux fois plus large que haute).
De cette façon, on a bien les dimensions de l’emplacement de l’image qui sont connues, dès le chargement de la page, par les CSS et le HTML, sans attendre le chargement des images et/ou du Javascript.
Il n’y a plus d’effet visible de bougé lors du redraw, puisque tout est déjà correctement positionné dans la page avant même le démarrage du javascript de chargement des images. Ce qui est épatant, c’est que la différence est également sensible lorsqu’on revient sur la page déjà en cache. On a désormais un effet de « surgissement » des images sans redessiner visiblement la page.
Un peu comme si on avait définit dans le code HTML les dimensions (width et height) des images, comme c’est préconisé, mais en restant en responsive.
Encore du nouveau sur mon #plugin #SPIP image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Cette fois, il s’agit de pouvoir calculer la taille de l’image en fonction de la hauteur, et non plus de la largeur, de la boîte qu’elle occupe. (Et il y avait un bug dans la version précédente, qui faisait qu’il n’y avait jamais d’image de prévisualisation.)
Pour cela, introduction d’une troisième variable :
[(#LOGO_ARTICLE|image_responsive{0,0,1})]Je pense que c’est d’un usage très spécifique, parce que concevoir une interface (qui plus est responsive) en définissant les hauteurs de boîtes plutôt que les largeurs, c’est assez coton.
Au passage, il faut re-modifier le .htaccess.
Exemple minimal : on place les logos des articles les uns à côté des autres, et ils auront la même hauteur (celle de la boîte contenante : 120 pixels ; ou, automatiquement, 240 pixels en écran haute définition) :
<div style="height: 120px;">
<BOUCLE_articles(ARTICLES){par date}{inverse}{0,5}>
[(#LOGO_ARTICLE|image_responsive{0,0,1})]
</BOUCLE_articles>
</div>
Bonjour ARNO et un grand merci pour ce plugin.
Puisque le but ici est d’optimiser les images envoyées en fonction de la taille nécessaire, ne serait-il pas judicieux de passer en plus par le plugin smush pour réduire encorela taille de ces images ?
Pour l’instant |image_responsive|image_smush ne fonctionne pas je suppose que ce serait au javascript de permettre ce détour.
Qu’en penses-tu ?
Une nouveauté sur mon #plugin #SPIP image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
L’idée est de pouvoir désormais fixer arbitrairement quelles largeurs d’image on autorise.
Le principe initial d’image_responsive, c’est de charger l’image une fois qu’on a calculé la page, donc on connaît déjà la largeur réelle d’affichage de l’image. De cette façon, on charge exactement l’image à la taille à laquelle on l’affiche.
Du coup, il devient totalement inutile même de gérer la largeur réelle de l’image en amont. Ça fonctionnait bien dans mes maquettes précédentes, avec au final un nombre limité de tailles d’images différentes. En laissant faire le plugin, je fabrique certes beaucoup de tailles de la même image, mais pas de façon excessive.
Le hic, c’est lorsque j’affiche l’image carrément en pleine largeur de l’écran (habituellement, j’étais plutôt dans des largeurs d’affichage fixées). Là, je me retrouve avec la possibilité de calculer des centaines de versions d’une même image, en fonction de la taille de la fenêtre d’affichage.
Du coup, j’introduis la possibilité de fixer les tailles autorisées pour charger les images :
[(#LOGO_ARTICLE
|image_proportions{3,2}
|image_responsive{320/600/1024}
)]Ici, je fabrique une image de proportions 3/2 (de largeur indéterminée dans ces proportions, je m’en fiche), puisque j’insère une vignette de prévisualisation de 320 (la première valeur). Le javascript qui charge l’image définitive, lui, ne chargera des images que de 320, 600 ou 1024 (en fait : plus les versions haute définition, donc potentiellement six versions de l’image). Exemple : si j’affiche l’image sur une largeur de 479 points, alors je charge l’image de largeur 600 (que je réduis donc à l’affichage).
On perd évidemment un peu de l’efficacité du plugin, puisqu’on charge une image un peu plus grande que celle qu’on affiche, mais cela évite d’avoir des centaines d’images différentes calculées dans certains cas.
Si on ne veut pas de vignette de prévisualisation mais les mêmes tailles autorisées au chargement a posteriori, la première valeur à indiquer est 0 :
|image_responsive{0/320/600/1024}Je l’utilise sur la page d’accueil de ce site (#shameless_autopromo) :
▻http://festival-scenaristes.com

@fil A priori, la réponse est ici ▻http://fr.wikipedia.org/wiki/Synchronicit%C3%A9
Pour la séparation des valeurs, pourquoi as-tu choisi des / et pas des virgules comme on fait d’habitude ? (Si c’est par facilité de codage, je veux bien m’occuper de remettre les virgules ; si c’est pour conserver la possibilité d’ajouter une variable supplémentaire après ces valeurs, je n’y touche pas)
@fil : c’est parce qu’il y a déjà une variable qui suit (le chargement des images en lazyload est toujours là).
Avec ceci, tu limites à 3 tailles et les images ne sont chargées que si le scroll les affiche (un écran de marge, tout de même) :
|image_responsive{0/320/600/1024, 1}

Dis @seenthis je crois me rappeler que tu as publié le plugin qui te permet de détecter la langue d’un segment de texte, tu saurais nous rappeler où ?
C’est detecter_langue (fonction du même nom) :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/plugins_seenthis/detecter_langue
Note qu’il y a tous les plugins dans :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/plugins_seenthis
Par exemple, lien_court est quelque chose que j’utilise parfois sur d’autres sites (c’est l’algo qui permet de présenter les liens dans Seenthis).

Merci @arno - gratitude éternelle et bisous mouillés :)
Modif sur mon #plugin #SPIP image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Cette fois, c’est très spécifique : on peut appeler la fonction charger_image_lazy, qui se charge de décider s’il faut charger les images (en mode « lazy load »), en lui passant la valeur du scrollTop.
Ça sert dans le cas où l’on a un script qui intercepte le scroll pour le gérer à la main. C’est le cas, uniquement sur interface touch, avec Skrollr. Dans ce cas, je déclenche skrollr en lui indiquant de faire ceci lors du « render ».
var sk = skrollr.init({
render: function(data) {
charger_image_lazy(data.curTop);
}
});Oui, c’est un peu spécial, mais je prépare un site avec de très longues pages en mode « long form » (ou « parallax »), chargement des images en responsive et lazy load, et du coup, viili voilou.
Grosse modif de mon #plugin #SPIP image_responsive : il permet désormais de choisir de charger les images en lazyload
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
L’idée, c’est de transformer un des inconvénients de ce système (lancer le chargement des images après un premier rendu de la page) en avantage, et d’intégrer directement un système de lazyload : c’est-à-dire ne charger que les images qui sont réellement affichées dans les limites visibles de l’écran.
Le plugin change de syntaxe : la deuxième variable permettait de désactiver le chargement des images haute définition, je décide de l’éliminer parce que ça ne sert à rien avec les modifs récentes (calculs et compression plus efficaces), et à la place, la seconde variable permet d’activer (si elle est mise à la valeur « 1 ») le lazyload sur cette image.
Par exemple :
[(#LOGO_ARTICLE_NORMAL
|image_proportions{16,9}
|image_responsive{0,1})
]Ici, |image_proportions va recadrer l’image selon les proportions 16/9e, sans réduire cependant la taille de l’image.
Et |image_responsive va fabriquer les éléments permettant le chargement d’une image responsive. Ici, la première variable (« 0 ») est la taille de la vignette chargée par défaut (avec la valeur 0, je décide de ne pas intégrer de vignette : je charge « rien.gif » à la place). La seconde variable (« 1 ») indique donc qu’il ne faut charger cette image que si elle se situe dans la fenêtre visible.
Au passage, le javascript de lazyload est assez marrant, j’ai privilégié l’efficacité des calculs, du coup la « position » verticale de l’image dans la page est calculé une seule fois (au chargement et au redimensionnement) et stocké dans un « data-top », puis effacé. Ça évite de faire des calculs à chaque fois qu’on scrolle. En revanche, on perd potentiellement en précision (images qui se déplaceraient dans la page, ou blocs affichés/masqués).
À noter qu’il y a évidemment une tolérance : ça charge un peu plus que l’écran visible, c’est pas la peine que les gens voient trop que les images n’ont pas été chargées.
Enfin, il y a désormais un calcul en javascript de la hauteur des images tant qu’elles sont en "rien.gif", ça permet de calculer plus précisément le lazyload.
Comme d’habitude, je l’utilise sur Orient XXI :
►http://orientxxi.info
Je me posais la question au sujet du Lazyload, si y’avait pas une autre approche envisageable (c’est peut-être la tienne et j’ai pas compris) :
– afficher en priorité les images visibles
– puis aller chercher et « afficher » les autres images (sans attendre que la personne scroll, donc « en-dessous » de la ligne de flottaison)
J’ai l’impression qu’en terme de rapidité d’affichage c’est équivalent quand on arrive sur le site, mais que cette solution est plus agréable quand on scroll parce qu’on donne une chance pour que les images aient le temps de s’afficher avant (en tous cas forcément plus qu’avec le lazyload).
C’est peut-être au niveau de la consommation de la bande passante que la solution lazyload est plus avantageuse, mais je ne sais pas quand elle situation elle est vraiment utile.
Après je dis tout ça un peu comme ça, je sais pas précisément comment ça marche en javascript, peut-être que ce que je propose n’est tout simplement pas possible.
Une dernière remarque : y’a déjà un plugin LazyLoad dans SPIP.
▻http://contrib.spip.net/jQuery-Lazy-Load-pour-SPIP
Il ne fonctionne pas sur les mêmes principes, mais peut-être pourrait-il être amélioré, en lui donnant des options et tout ? Ou peut-être autonomiser cette fonction si des gens veulent l’utiliser sans le reste du plugin (là encore, tout ça est peut-être trop imbriqué...) ?
En tous cas merci pour toutes ces contributions autour des images et du #RWD.
En gros, ce que fait LazyLoad, c’est de lancer le script jquery Lazy Load, très connu. Mon script est très différent, et son principe de fonctionnement est également très différent, j’ai essayé d’optimiser (limiter les recalculs de positionnement) et ça doit fonctionner en responsive (donc je ne fixe pas les dimensions des images a priori).
Ensuite, le principe du lazy load n’est pas idéal non plus dans l’absolu (notamment parce qu’il bloque le pré-chargement des images). En tout cas, le fait de charger des images progressivement avant de les afficher, c’est l’assurance de ne pas afficher toutes les images en même temps. Si on a de grosses images, ce n’est pas grave (il y a une image par « écran », plus ou moins), mais si c’est une multitude de petites vignettes (c’est le cas de Flip-Zone), la page est redessinée plusieurs fois (à chaque vignette) et c’est pénible ; en changeant d’un coup toute une série complète de « img src », j’ai bien l’impression que les navigateurs sont optimisés et assez souvent, toute une série de vignettes s’affichent d’un seul coup. Avec un preloading individuel, ça n’a pas l’air de faire pareil (une de mes versions faisait ça : préloading puis affichage). Le preloading avant d’afficher, c’est pas mal sur tout petit écran, mais ça m’a semblé au contraire très pénible sur écran normal.
Sinon, un preloader de toutes les images, c’est une idée, mais c’est encore un autre principe à mon avis. Je n’y suis pas favorable pour l’instant : charger des trucs « en trop », c’est justement ce qu’il s’agit d’éviter avec les image_responsive (parce qu’on est sans la 3G, parce que le smartphone n’est pas très vaillant…), alors pour le coup, ne charger que si les gens scrollent réellement. Et si tu veux faire ça, à mon avis, le mieux est encore de ne pas utiliser l’option « lazyload » de mon plugin : tu laisses le comportement normal, et je suspecte que c’est plus ou moins le principe de base d’un navigateur a qui on indique tous les « img src » d’une page – il commence par les premiers et/ou les éléments visibles.
Je continue avec mon #plugin #SPIP « Image responsive » :
– je sauvegarde la taille de l’image d’origine dans le code HTML (data-l, data-h) ; dans le Javascript, ça me permet d’éviter d’appeler des images à une dimension supérieure à l’image d’origine (ça marchait, mais ça fabriquait des fichiers identiques avec des noms différents) ;
– (si je ne me suis pas raté) je détruis l’image intermédiaire après l’avoir renommée (faudrait voir à faire « rentame », plutôt, tiens… mais en faisant gaffe à pas renommer l’image d’origine) ;
– si on a le mod Apache XSendFile (et correctement configuré) c’est désormais pris en compte et, au lieu de faire un readfile, l’action qui expédie l’image passe par X-SendFile. J’ignore à quel point ça va jouer sur la réactivité du scripte et/ou la charge du serveur. (Attention, le code à insérer dans le htaccess doit être modifié pour pouvoir utiliser XSendFile.)
Je colle ce lien, histoire de voir tes messages à la suite :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Amélioration de mon #plugin #SPIP image_responsive : introduction d’une fonction image_reduire_net (qu’on peut extraire, parce qu’elle est très générique) : elle réunit dans une seule passe les 3 fonctions graphiques dont j’ai besoin dans ce plugin :
– elle effectue la réduction (équivalent à image_reduire)
– elle fait passer un filtre de netteté selon la taille de l’image (équivalent à image_renforcement, mais en utilisant la nouvelle fonction imageconvolution de PHP 5.1, certainement beaucoup plus rapide)
– et sauvegarde directement à la qualité désirée (puisque sur Retina je sauvegarde une image très compressée).
Du coup, on doit gagner en temps de calcul mais, surtout, en qualité d’image finale, puisqu’au lieu de 3 sauvegardes JPEG successives je n’ai plus besoin que d’une seule.
Note : je continue à sauvegarder une version renommée de l’image finale, pour éviter de lancer la cavalerie de _image_valeurs_trans à chaque hit sur l’image.
Énaurme modif sur mon #plugin #SPIP « Image responsive » (oui, je suis content) :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Ça concerne le chargement des images sur écran haute définition (Retina chez Apple, mais je teste actuellement avec un Nexus 7).
Sur un écran « normal », en admettant qu’on affiche l’image sur 512 pixels de large, le plugin va charger l’image « xxx-resp512.jpg » :
Si on a un écran haute définition (densité 2), le javascript précédent chargeait la même image, mais en 1024 pixels de large « xxx-resp1024.jpg » (512x2) :
J’ai déjà évoqué ces deux buts contradictoires des images reponsives :
– ne plus charger les grandes images quand on est sur petit écran, parce que ça ne sert à rien (généralement, sur smartphone avec connexion lente),
– mais aussi, pouvoir charger les images en haut définition sur écran haute définition. Malheureusement, le plus grand nombre d’écrans haute déf pour le moment, ce sont les smartphones.
Donc sur smartphone, on a connexion (plutôt) lente et écran haute définition, du coup on charge des images plus grosses là où on pensait en charger des plus légères.
La solution : si écran haute définition, alors je charger bien une image de 1024 pixels, mais en compressant le JPEG de manière beaucoup plus importante « xxx-resp512-2.jpg » :
Par défaut, les images JPEG traitées par SPIP sont sauvegardées avec un taux de compression de 85%, de façon à avoir de belles vignettes. Avec un taux de 50%, on gagne donc énormément en poids de fichier. Mais évidemment, on détruit largement la qualité de l’image. Sauf qu’ici, on affiche l’image sur un écran haute définition : l’œil est à ce niveau de définition incapable de percevoir la différence.
Note : la compression à 50% n’est appliquée que si l’image d’origine est suffisamment grande par rapport à la taille cible. Avec le plugin, il n’est pas rare qu’on n’affiche finalement pas une image beaucoup plus grande que ce qu’on ciblait à l’origine (si mon image d’origine fait 800 pixels de large, que je l’affiche sur 600 pixels de large sur un écran Retina, je ne pourrai évidemment pas expédier d’image de 1200 pixels sur-compressée… donc dans ce cas je ne sur-compresse pas pour éviter que la dégradation ne devienne perceptible).
Alors, ça ressemble à la logique des « compressive images » :
▻http://filamentgroup.com/lab/rwd_img_compression
l’article prétend qu’une image sauvegardée à un taux JPEG de 10%, affichée deux fois plus petite, est perçue comme de même qualité qu’une image sauvegardée à un taux normal. C’est peut-être vrai quand on affiche cette image sur un écran « normal » (l’image est à nouveau lissée par le fait qu’on affiche 4 pixels de l’image d’origine en un seul à l’écran) ; mais sur écran haute définition, c’est très perceptible, et on perd à mon avis carrément l’intérêt de balancer une image haute définition sur un écran retina.
Bon, c’est en fonctionnement sur OrientXXI :
►http://orientxxi.info
Sur écran « normal », il n’y a logiquement aucune différence. En revanche, sur écran haute définition, on charge des images visiblement beaucoup plus « nettes », « définies » (« sharp »), parce qu’avec quatre fois plus de pixels, mais quasiment de même poids (environ un tiers de plus, alors que dans la version précédente, l’écran Retina provoquait le chargement d’images 7 fois plus lourdes…).
Je trouve que ça commence à devenir sympa.
(Pour ceux qui avaient déjà installé/testé le plugin, penser à remodifier le fichier .htaccess, la redirection a été modifiée.)
Ajout à mon #plugin #SPIP image_responsive, une fonction |image_proportions
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Par exemple :
[(#LOGO_ARTICLE_NORMAL|image_proportions{16,9})]L’intérêt par rapport à image_recadre, c’est qu’il s’agit ici de modifier retailler l’image sans en diminuer la taille à des dimensions arbitraires, mais de conserver l’image aussi proche de sa taille initiale que possible.
C’est rendu nécessaire et utilisable par le principe même du plugin image_responsive, qui va ensuite charger l’image à la taille qui va bien dans tous les cas.
Non. L’aspect responsive n’a pas besoin qu’on formate spécifiquement les images. Au contraire, le plugin permet qu’on balance les images d’origine sans faire trop attention.
Mais à l’inverse, pour faire maquette sympa, c’est vraiment plus efficace si on se force à avoir des vignettes de navigation de mêmes proportions (par exemple 16/9, mais ça peut être 4/3, 1/1, ce qu’on veut…). Voir la page d’accueil d’Orient XXI, les vignettes sont toutes recardées aux mêmes proportions :
►http://orientxxi.info
Pour ça, habituellement, on recadre les images directement aux dimensions prévues, genre :
[(#LOGO_ARTICLE
|image_passe_partout{300,200}
|image_recadre{300,200}
)]Mais avec le plugin image_responsive, je n’ai plus besoin de savoir la dimension finale de l’image, parce que c’est le plugin qui va charger l’image dont il a besoin. Et même potentiellement la largeur de l’écran d’un smartophone, à double définition.
Donc c’est pas la peine de s’embêter à calculer avec le redimensionnement de l’image en amont : tu balances l’image complète directement, ça chargera juste ce qui est nécessaire selon la maquette la définition de l’écran.
[(#LOGO_ARTICLE
|image_responsive
)][(#LOGO_ARTICLE
|image_proportions{300,200}
|image_responsive
)]C’est donc un confort lié à ce que fait ce plugin :
– comme il va chercher l’image à la bonne taille tout seul, il n’est plus nécessaire de réduire les images dans le squelette ; ça laisse d’autant plus de latitude pour différentes situations et les écrans retina ;
– mais dans le même temps, j’ai l’habitude de recarder les images pour forcer des maquettes plus typées.
Donc là j’en profite pour recadrer sans réduire, parce que c’est le plugin qui fera le reste du travail selon les situations.
C’est bien sympa et générique, ça mériterait d’être ajouter au plugin dist « filtres_images » (qui est indépendant du core, donc qui a son propre cycle de vie désormais, à peu près).
Dans :
▻http://zone.spip.org/trac/spip-zone/browser/_core_/branches/spip-3.0/plugins/filtres_images
Et dans :
►http://zone.spip.org/trac/spip-zone/browser/_core_/plugins/filtres_images
C’est déjà dans le plugin « CSS imbriqués » (version 1.6) :
►http://www.paris-beyrouth.org/tutoriaux-spip/article/plugin-spip-pre-processeur-de-css
1.6. Introduction de la fonction couleur_rgba($couleur, $alpha) qui permet de fabriquer une couleur RGBA à partir d’un code hexadécimal.
Il me semblait bien que je l’avais vue quelque part sur Paris Beyrouth
C’est à dire @Fil ?
Sur un de mes sites j’ai fait une série de tests sur la largeur et la hauteur pour afficher l’image en pleine largeur si elle est en paysage et assez grande et dans une colonne si elle en portrait ou trop petite. Je m’étais bien pris la tête.
Suite à l’observation de @rastapopoulos j’ai ouvert ▻http://core.spip.org/issues/3144 pour garder une trace du besoin.
b_b me dis de l’ajouter moi même mais je ne sais pas coder moi :-)
Quelques nouveautés pour mon #plugin #SPIP image_responsive :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Que l’on utilise par exemple ainsi :
[(#LOGO_ARTICLE_NORMAL|image_responsive{160})][(#LOGO_ARTICLE_NORMAL|image_responsive{160,0})][(#LOGO_ARTICLE_NORMAL|image_responsive{0,0})]Comme il fonctionne bien, je l’ai désormais systématisé sur Flip-Zone :
►http://www.flip-zone.net
Si l’on affiche le site avec plusieurs tailles d’écran, on pourra voir que les images qui sont chargées sont de tailles différentes.
Les deux nouveautés :
– la première variable désigne la taille de l’image par défaut ; a priori, on choisit la taille minimale d’affichage (sur mobile) ; on peut désormais fixer cette valeur à 0, et dans ce cas l’image par défaut sera « rien.gif » ; au chargement de la page, donc, rien ne se déclenche, on ne charge les images que via javascript. C’est pratique si, comme sur Flip-Zone, on peut avoir des dizaines d’images sur la page ; dans ce cas, limiter le nombre de hits est sensible.
– la seconde variable est optionnelle, et la seule option est de la mettre à zéro. Si on la fixe a zéro, cela signifie qu’on ne chargera pas les images en haute définition (écran Retina…). En effet, l’intérêt des images responsive est double : (a) charger l’image en fonction de la maquette dans laquelle elle s’affiche à l’écran (selon la taille de l’écran, une image s’affichera par exemple sur 70 pixels de large, 160 ou 524 pixels…) ; (b) charger une image de double définition si on détecte qu’on est sur un écran haute définition (dans ce cas, on a une maquette qui affiche l’image sur « 70 » pixels, mais on affiche une image de 140 pixels puisqu’il y a deux fois plus de points affichés).
Les deux objectifs sont parfois contradictoires :
– le point (a) permet de limiter la taille des images chargées sur petit écran,
– le point (b) force à charger une image deux fois plus larges, donc avec 4 fois plus de pixels, sur affichage à haute définition (souvent des smartphone…).
Du coup, on peut décider que certaines images se chargent à leur taille d’affichage, mais sans prendre en compte le fait qu’on est sur écran haute définition. Le but du plugin dans ce cas est, essentiellement, d’accélérer l’affichage sur le site.
Sur Flip-Zone, toutes les vignettes de navigation, qui sont des images, restent en définition normale ; certes ça se voit, mais comme ce sont des photos, je pense que c’est très acceptable vu le poids gagné sur smartphone (la situation de connexion la pire). En revanche, le logo du site, lui, se charge en haute définition sur écran haute déf… parce que c’est une image qui n’est pas très lourde, et parce que c’est un lettrage, dont l’affichage est très sensible à la haute définition.
Un nouveau #plugin pour #SPIP, destiné à gérer des images en #responsive : Image Responsive
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/image_responsive
Le plugin est actuellement installé sur Orient XXI :
►http://orientxxi.info
Pour se faire une idée des problématiques :
▻http://mobile.smashingmagazine.com/2013/07/08/choosing-a-responsive-image-solution
Aucune des solutions évoquées ne me plaît, et je me suis dit qu’on a déjà dans SPIP ce qu’il faut pour s’en sortir, du coup voici une solution qui me semble intéressante.
Notez que je suis particulièrement intéressé, ici, par des retours et des commentaires. C’est une solution très expérimentale (je l’ai codée aujourd’hui), et comme elle est du coup directement intégrée à SPIP, je pense que c’est une piste très intéressante à développer.
Le problème à résoudre :
– en responsive, selon la taille de l’écran, une image va s’afficher en différentes tailles ; sur la page d’accueil d’Orient XXI, c’est même très important (une même image s’affiche sur 160 pixels de large ou 460 pixels de large selon l’écran) ;
– de plus, sur un écran haute définition, il faudrait afficher des images encore deux fois plus grandes.
Du coup, dès qu’on commence à faire du design responsive, on a tendance à charger des images plus lourdes que ce qu’on va réellement afficher. Et ça commence à peser sur une connexion mobile pourrie.
Noter que c’est un aspect désormais lourdement pénalisé par le calcul du PageSpeed.
Ma solution avec ce plugin :
– on fait passer une image (ou, si je ne me suis pas raté, un texte complet contenant plusieurs images) par le filtre |image_responsive{120}
– cela va modifier le tag <img> :
+ le src va appeler une version réduite de l’image (ici, à 120 pixels de large),
+ l’image d’origine (celle qui est donc dans la version initiale du src) est stockée dans un data-src
+ j’ajoute une classe « image_responsive » à l’image.
Initialement, quand on charge la page, on va charger une version déjà réduite de l’image et, idéalement, on indiquera la taille d’affichage pour smartphone.
Une feuille de style est associée au plugin, qui force l’affichage de toutes les images de classe .image_responsive à 100% de la largeur. Attention, c’est le point vraiment important et un peu contraignant : c’est le conteneur de l’image (par exemple un <span class="logo"><img></span>) qui va déterminer la largeur d’affichage de l’image, parce que de toute façon l’image sera affichée sur 100% de cet espace. (La feuille de style va donc styler .logo éventuellement de manière responsive…)
Une fois la page chargée, un javascript va scanner chaque .images_responsive, récupérer la largeur à laquelle elle est affichée, éventuellement multiplier par la densité de l’écran (2 pour un écran retina), et remplacer l’image par la version de cette nouvelle largeur.
On charge donc une vignette, puis on remplace par une version de l’image à la taille exacte d’affichage.
L’idée c’est de faire du responsive, pas du fluide. Si votre image peut s’afficher en 1000 largeurs différentes, ce plugin va finir par fabriquer 1000 fichiers graphiques différents, ce qui n’est pas forcément génial…
– Assez simplement, là où mettait un [(#LOGO_ARTICLE_NORMAL|image_reduire{320})]
on met maintenant un :
[(#LOGO_ARTICLE_NORMAL|image_responsive{120})]
(en considérant, par exemple, que 120 est la taille d’affichage usuelle de cette vignette sur un smartphone).
Le reste des automatismes du système se charge automatiquement via le #INSERT_HEAD, donc il n’y a rien à faire, si ce n’est vérifier que les CSS sont adaptées pour forcer le dimensionnement du conteneur de l’image plutôt que l’image elle-même.
– Important : si votre site repose sur le .htaccess (URL sans query string), il faut absolument y insérer une ligne supplémentaire. Cela permet de traiter les images derrière des URL de fichiers JPG, ce qui devrait faciliter les mises en cache.
Avec ça, le score PageSpeed de la page d’accueil d’Orient XXI est passée de 76/100 à 94/100. Et l’impression de vitesse sur smartphone est très très nettement améliorée.
Pour info, sur le thème Responsive + Performance, Cédric a aussi commencé un plugin ayant peu ou prou le même but, pour l’instant complètement expérimental, en suivant des propositions d’articles traitant de ce sujet :
▻http://zone.spip.org/trac/spip-zone/browser/_plugins_/respim/trunk
Je viens de tenter de l’utiliser sur un site qui se trouve sur un hébergement Gandi : gros soucis (inutilisable). Les images ne se chargent le plus souvent pas, sauf si on force leur chargement. Je suspecte qu’il y a quelque chose à ajouter dans les headers que j’expédie au client, mais là ça me dépasse un peu. Surtout, c’est derrière un Varnish de Gandi dont la configuration est un secret d’État, ce qui n’aide pas (alors que sur mon serveur à moi, j’ai aussi un Varnish, et il n’y a aucun problème).
Cédric vient de publier un blog au sujet de sa solution pour des logos d’articles responsive ▻http://seenthis.net/messages/185485
@arno Comment se comporte ton plugin après quelques jours ? As-tu percé les Mystères de Varnish et Gandi ?
Sur Gandi, c’est un site en prod, alors je ne peux pas trop trop bidouiller, et en plus je suis un peu débordé pour y consacrer trop de temps.
En revanche, ça tourne désormais sur la partie Lingerie de Flip-Zone, et là j’ai aussi un Varnish (vu que les images sont désormais des scripts PHP, c’est particulièrement conçu pour être derrière un Varnish)
►http://en.dentell.es
et ça ne semble pas poser de soucis. À l’instant, j’ai viré le cache du site pour forcer le passage de quasiment toutes les images en responsive, alors ça va ramer un peu et certaines images ne vont pas venir le premier coup, mais je pense que d’ici quelques heures ça reprendra son rythme de croisière.
Noter : je viens de poster des modifications sur la Zone :
– on peut désormais choisir |image_reponsive{0}. La valeur zéro indique qu’on ne veut charger de vignette dans le src de l’image. À la place, ça charge rien.gif ;
– corrigé le bug des images verticales (pourtant, les image_reduire, j’ai l’habitude…).
►http://en.dentell.es fait planter mon iceweasel 20. J’ai pas flash installé.
Je n’utilise pas Flash. (En dehors des pubs Google.) Est-ce que ►http://www.flip-zone.net te plante aussi ? (Sur Flip-Zone, le plugin n’est pas installé.)

Salut,
une petite explication de Cédric sur la liste Zone sur la différence entre vos 2 plugins ( Image Responsive et Adaptive Images ) :
▻http://article.gmane.org/gmane.comp.web.spip.zone/35142
Je me disais que ça serait intéressant de l’avoir là pour éclairer les choix vers l’un ou l’autre...
Bonjour,
en test (sur 3.0.20) de ce plugin bien pensé comme toujours.
Seulement... un soucis.
la fonction image_proportions fonctionne parfaitement, le plugin est donc bien installé, le htaccess aussi.
Il y avait dans le squelette
[(#LOGO_ARTICLE|image_reduire{200,200})]
La css stylait correctement img.spip_logos en width=200px ;
je l’ai transformé en [(#LOGO_ARTICLE|image_proportions{1,1}|image_responsive{200})]
Or, à l’affichage, le logo s’affiche pixellisé en 650x650 (100%page), donc le conteneur de l’image est mal stylé.
Est-ce qu’il faut mettre le #LOGO_ARTICLE dans une div à part, où est-ce que normalement, le style spip_logos est conservé ? (je ne trouve pas dans le code généré de classe paticulière à l’intérieur de <picture>)
merci d’éclairer un peu mon chemin...



@nidal a annoncé le lancement du site @OrientXXI la semaine dernière :
▻http://seenthis.net/messages/180554
C’est donc là :
►http://orientxxi.info
Comme c’est bibi qui l’a fait, un petit coup de #shameless_autopromo pour détailler quelques aspects techniques…
– C’est évidemment du #SPIP_3, #HTML5 et #responsive. Donc évidemment, je travaille avec mon plugin « CSS imbriqués » :
►http://www.paris-beyrouth.org/tutoriaux-spip/article/plugin-spip-css-imbriques-pre
– L’un des aspects que j’ai pu beaucoup plus travailler que d’habitude, c’est la typographie des textes des articles. C’est drôlement gros (de base sur mon ordinateur : 19px), et c’est rend la lecture à l’écran vraiment fluide. Sur tablette, je trouve que c’est carrément épatant.
– Pour l’occasion, j’ai aussi pas mal bossé les tags meta destinés à informer les réseaux sociaux du contenu de la page. Les petits pavés qui apparaissent sur Twitter et Facebook quand quelqu’un partage un article sont vraiment attrayants.
– Le pavé « Lire aussi » dans la colonne de droite des articles est totalement automatique : c’est un calcul basé sur les mots-clés utilisés par chaque article. Ça marche pas mal pour créer de la navigation transversale.
– Je fais passer mon plugin « Détecter langue » (conçu initialement pour Seenthis) sur les textes, cette fois paragraphe par paragraphe, pour pouvoir publier des articles multilingues (avec de l’arabe, ça devient indispensable) :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/plugins_seenthis/detecter_langue
On peut le voir à l’œuvre par exemple sur ce poème traduit de Mahmoud Darwich :
►http://orientxxi.info/magazine/mahmoud-darwich-for-ever-le-discours-du-dictateur-0328
– Sur ce site, je force le retour chariot façon SPIP 2 (il faut sauter deux lignes) ; parce que plus ça va (depuis que je suis sur SPIP 3), plus je constate que laisser le retour à la ligne simple sur un site éditorial conduit rapidement à la catastrophe.
– Pour le pavé de Une (fond bleu) de la page d’accueil, une sélection manuelle grâce avec mon vieux plugin « Sélection d’articles » :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_/selection_d_articles
– Comme expliqué par @nidal, le site intègre directement le flux Seenthis du groupe (via l’importation de RSS de SPIP) :
►http://orientxxi.info/au-fil-du-web
– J’utilise mon vieux plugin « Lire aussi » pour pouvoir créer des « Dossiers » :
►http://orientxxi.info/magazine/oslo-20-ans-apres,0345
(donc, bien comprendre : sur ce site le pavé « Lire aussi » du site public se construit automatiquement ; le plugin « Lire aussi » n’est pas utilisé pour créer ce pavé, mais pour constituer des « Dossiers » éditoriaux)
– Dans la rubrique « Cartographie », j’affiche des cartes géantes zoomables de @reka, l’interface fonctionnant avec #leaflet.js. Ajout : un véritable mode plein écran (#fullscreen_api du HTML5, avec alternative en position:fixed pour les navigateurs qui ne l’acceptent pas). En revanche, par rapport à @fil, je n’ai pas de script coté serveur pour fabriquer les briques graphiques des cartes, j’utilise directement Zoomify et j’installe les briques sur le serveur.
Le détail sympa : la carte est consultable seule dans sa page :
▻http://orientxxi.info/cartographie/egypte-bassin-du-nil
mais il y a de plus un modèle SPIP pour intégrer la carte dans le texte d’un article :
►http://orientxxi.info/magazine/tensions-autour-du-nil,0297
(et ça c’est carrément cool).

C’est classe d’avoir ce genre d’explications sur des sites. Deux-trois retours :
– +1 pour la question des retours lignes. C’était un peu embêtant avant, fallait s’y faire, mais maintenant sur Spip 3 c’est pire :p
– Pour les réseaux sociaux, le rendu est top, cf ▻https://twitter.com/OrientXXI/status/387504642331901952
– moi aussi je veux un bouton de partage vers Seenthis. C’est le bouton pour navigateur intégré sur le site, c’est ça ?
– au niveau typo, je pense qu’on gagne vraiment à remplacer les dernières Arial qui traînent.
– sur la page d’accueil, les trois colonnes ça fait très classe, mais le web ne sait toujours pas justifier du coup ça éclate le texte chez moi. A l’inverse, j’aime beaucoup la page magazine non justifiée.
– le corps 19 pour le texte, ça fonctionne bien, mais par contre le corps 26 pour le chapô, c’est un peu trop gros pour moi.
– j’ai pas compris l’intérêt du plugin « lire aussi » pour constituer des dossiers éditoriaux par rapport à un groupe de mots-clés spécifique.
– le mode plein écran pour les cartes est vraiment impressionnant, et les cartes dans les articles sont bien aussi. Ca pourrait bien intéresser sous-surveillance. Manque peut-être juste un bouton pour revenir à une taille optimale dans le bloc quand t’as déjà zoomé.
Merci en tout cas pour les infos, joli boulot !
#spip_blog
Sur « Lire aussi » et les « Dossiers »…
– D’abord, tu dois savoir que je suis persuadé (de manière quasiment religieuse désormais) qu’il ne faut jamais utiliser les mots-clés pour gérer des statuts éditoriaux. La seule utilisation viable des mots-clés, c’est la thématisation.
À chaque fois que j’ai vu (ou qu’on m’a obligé à le faire) des mots-clés utilisés pour gérer la page de Une, la colonne de droite, les trucs qu’on fait apparaître plus gros… ça rend le site vraiment bordélique à gérer.
– Donc ici, oui, il y a des mots-clés, mais ce sont bien des mots-clés thématiques. Par exemple, les Accords d’Oslo :
▻http://orientxxi.info/accords-d-oslo
Mais il faut bien voir que les mots-clés, ce sont des thèmes « ouverts » : à tout moment quelqu’un peut ajouter tel mot-clés à tel nouvel article, et donc la page « Accords d’Oslo » évoluera selon ces ajouts.
– Ce dont j’avais besoin ici, c’est de créer des « Dossiers » figés. Un objet éditorial regroupant plusieurs articles, qu’on n’enrichira plus par la suite.
Donc pas des mots-clés. Sinon ça veut dire qu’on a un groupe de mots-clés dédiés à cela, et qu’on fabrique un mot-clé à usage unique pour chaque « Dossier ». Pour moi, c’est clairement un détournement des mots-clés, destinés à faire des manipulations éditoriales.
Ça n’est pas le pire détournement possible, mais c’est à éviter.
– Le plugin « Lire aussi » est explicitement destiné à gérer ces regroupements, au lieu de créer des « mots-clés à usage unique ». Il est construit sur le même principe que les liens de traduction : il y a un article de référence, et les articles qui lui sont liés. Dans chaque article concerné, je vois la liste des articles liés, et quel est l’article de référence.
Du coup, ici, c’est facile : l’article de référence est considéré comme la porte d’entrée du dossier (ce ne serait pas facile à faire avec des mots-clés), et je pourrais aussi décider de ne plus intégrer les articles secondaires du dossier dans la navigation, ou de manière différente (je n’ai pas fait ça, mais c’est une possibilité).
Coucou,
Plein de belles choses. Mignon la petite image « dossier » qui se colle sur le logo de l’article d’accueil du dossier.
Quelques bugs ou remarques :
– le logo est un peu pixélisé sur les autres pages que la page d’accueil (ff20/linux)
– quand y’a pas de logo pour les articles dans les listes de « Lire aussi », ça fait un peu bizarre. ici par ex : ▻http://orientxxi.info/magazine/barack-obama-et-hassan-rohani,0381
– c’est peut-être voulu, mais chez moi les thèmes ne sont pas stylés. Ça me fait penser aux sites de journaux américains, qui raffolent de liens bleus ►http://www.nytimes.com
Une petite question. Comment sont fabriquées les url ? Le numéro à la fin, c’est pour google (j’ai un vague souvenir que google demande un nombre unique pour chaque page dans l’url) ?
C’est super de présenter ses réalisations de sites et leur entrailles. Ça devrait être une rubrique sur le blog de SPIP ou sur spip-contrib, pour inviter tout le monde à le faire.
Pour les URL, c’est un bout de code trouvé je crois sur Contrib, mais je ne sais plus où. Dans mes_options.php :
▻https://gist.github.com/anonymous/6899027
Ah si, retrouvé, c’est là :
▻http://contrib.spip.net/Optimiser-les-URLS-pour-google-actus
Hop @arno pour info il existe un plugin leaflet.fullscreen fait par un ty gars sympa sur github ;)
▻https://github.com/brunob/leaflet.fullscreen
Et depuis hier, il gère aussi du pseudo fullscreen pour les vieux navs.
@arno oui c’est un truc « rapide » qui marche, mais du coup :
1) je trouve que ça enlaidie les URLs pour une histoire uniquement technique (en plus même pas pour un standard reconnu mais juste pour faire plaisir à une entreprise particulière)
2) si jamais le site a des objets éditoriaux différents (article, rubrique, événement, patate) : deux objets peuvent avoir le même nombre donc il n’est pas unique (ce qui normalement fait partie de la demande).
Lorsqu’on ne veut pas modifier ses URLs, la solution est de fournir à Google un sitemap particulier, propre à #Google-News. Il y a quelques obligations à respecter, et possiblement des infos en plus quand on les a sous la main (voir la doc).
▻https://support.google.com/news/publisher/answer/74288?hl=fr
J’ai fait ça dans un mini-plugin tout con qui ajoute ça au robot.txt de SPIP et qui fournit un « sitemap_news » basique qui fonctionne. On peut le surcharger ensuite chez soi si on a plus d’infos à y mettre.
▻http://zone.spip.org/trac/spip-zone/browser/_plugins_/sitemap_news/trunk
@arno : merci, je vais tester. Sur Rebellyon, les articles en manchette ont le mot-clé « manchette », ceux en « une », le mot-clé « une ». Et quand on a beaucoup d’articles sur un même sujet, on crée un mot-clé de dossier. Tout cela fonctionne, mais c’est pas forcément aisé à transmettre comme fonctionnement.
Je pense qu’il faut créer ou améliorer un plugin pour ces besoins, car il y a de plus en plus de sites où il y n’y a pas que les « articles » comme objets éditoriaux.
Par exemple pour le besoin de « mettre en une » (que ce soit pour l’accueil complet ou l’accueil d’une rubrique), si on veut mettre en avant des articles et des événements dans la même liste, c’est galère. Ou même si on a un site composé presque que d’événements (un site culturel par ex) et que c’est ça le contenu éditorial principal du site.
Bref, ce type de plugin devrait être agnostique au niveau des objets à manipuler.
Pour gérer les Unes, j’utilise généralement deux solutions :
– la plus efficace et agréable à gérer, ce que je fais sur ce site-là, c’est le plugin « Sélection d’articles » ; c’est rapide, ça marche bien…
– quand le site est plus compliqué, et que justement il faut pouvoir mettre en page d’accueil un peu tout et n’importe quoi (des articles, des rubriques, des « événements », des calendriers, des formulaires d’inscription à des trucs…), je fais dans le lourd : une « rubrique technique » (dont je fais généralement commencer le nom par un dièse), avec éventuellement des sous-rubriques (si la page d’accueil est très structurée), et là-dedans on installe des articles virtuels (des articles qui pointent directement vers une autre URL). C’est encore avec ça que j’ai les résultats les plus puissants et le plus de liberté, même si c’est assez contraignant.
J’ai continué à travailler sur mon plugin « Détails d’interface », qui modifie le graphisme de l’interface privée de #SPIP-3 :
►http://zone.spip.org/trac/spip-zone/browser/_plugins_
Ce que ça donne désormais :
►http://twitpic.com/ajs8c0/full