Faut-il bloquer ça ?
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko ; compatible ; GPTBot/1.0 ; +▻https://openai.com/gptbot)
Quel est le moyen le plus aisé de virer tous les bots ? J’y serais personnellement favorable. :-)
Faut-il bloquer ça ?
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko ; compatible ; GPTBot/1.0 ; +▻https://openai.com/gptbot)
Quel est le moyen le plus aisé de virer tous les bots ? J’y serais personnellement favorable. :-)


Merci @ktche pour la suggestion. Je vais l’étudier (pour nginx), et sans doute la mettre en œuvre sur SeenThis. J’espère que c’est compatible avec la vieille version de Debian... sinon, ça m’encouragera à réaliser la migration.
@tous : les moteurs de recherche vont être globalement exclus, ils ne pourront plus parcourir SeenThis qu’en étant anonymes.


Sur pas mal de sujets, Seenthis tombe bien dans une recherche Google, parce que les longs threads sont intéressants. Du coup je ne comprends pas quel intérêt on aurait à se priver d’un bon référencement.
Pour rappel, Seenthis a un fonctionnement volontairement différent de la plupart des réseaux sociaux : il est conçu pour pouvoir être de manière libre, comme n’importe quelle page Web, sans demander à ce qu’on s’y inscrive (même Bluesky, je ne peux même pas voir la page de @fil sans y avoir moi-même un compte). Et dans les chiffres de visites que j’avais, c’était bien le cas : beaucoup plus de visites que d’inscrits.
C’est-à-dire qu’on est dans une logique plus proche du blog que du pur réseau social, donc on dépend pour une large part du fait que les excellents threads de qualité qu’on a ici fonctionnent comme des pages de blog et donc doivent être correctement référencés.
(C’est aussi pour ça que j’ai depuis le début ce système de micro-caches imbriqués pour tenter de rigoureusement limiter les recalculs avec accès mySQL lors du passage d’un robot sur l’ensemble du site.)
Je n’ai pas la même expérience que toi concernant les recherches sur SeenThis ; je ne retrouve jamais mes posts techniques, par exemple, si je les cherche avec les mots clefs qui vont bien (par exemple pour de la table de hash pour authentifier les connexions SMTP sur postfix).
L’autre jour, j’avais une surcharge sur le serveur. Toute la semaine, on en a eu. Et là, ce jour-là, c’était openai. Une autre fois, c’était un bot de capture d’images. Et une autre fois, c’était un bidule qui faisait du post sur toutes les URL qu’il trouvait...
Mais si ça vous va qu’on laisse les moteurs lire ce qu’on partage, ma foi, je laisse les choses en l’état, en me contentant de virer les ips les plus dommageables, au coup par coup.
Pour moi ce sont les moteurs de recherche qui doivent passer (GoogleBot notamment). Les autres je vois pas d’intérêt immédiat (les bots d’images, a priori, ça n’a même rigoureusement aucun intérêt puisqu’on n’héberge aucune image).
Top 10 par user-agent à l’instant, que le serveur est surchargé : que des bots, dont 2 avec UA vide.
Sogou Pic Spider/3.0(+http://www.sogou.com/docs/help/webmasters.htm#07)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/103.0.5060.134 Safari/537.36
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot)
Mozilla/5.0 (compatible; YandexRenderResourcesBot/1.0; +http://yandex.com/bots) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0
Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/)
-
SPIP-3.2.19 (https://www.spip.net)
Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot)
Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)
Ma phrase est mal formée : « pour moi, ce sont les moteurs de recherche qui doivent pouvoir continuer à passer ». Je voulais dire qu’à mon avis, tu peux tout bloquer, sauf les principaux moteurs de recherche, si on peut faudrait au moins garder GoogleBot et Bing (les Russes et les Chinois, je suis pas certain que ce soit bien utile…).

hum... même pour retrouver ici le compte de LC dont il est question avant clôture, j’ai du (faute d’imagination, de savoir ?) passer par gougueule




@b_b, @seenthis, @rastapopoulos, @arno, @tous : un endroit simple d’accès pour discuter du prochain serveur virtuel de ST ? Le serveur actuel est un vieux serveur Debian. Le mettre à jour à l’arrache devrait pouvoir fonctionner, mais je me disais qu’on pouvait aussi monter un serveur tout neuf. Il y a tout de même quelques composants obsolètes il me semble (sphinx ?)... MAIS. Je n’ai raisonnablement pas de temps à consacrer autre que : fournir la Debian vierge et l’IP publique temporaire.


Ou même encore un ticket quelque part dans : ►https://github.com/seenthis ?
Il faudrait amtha un minimum d’asynchronicité et de persistance :-))
J’ai trouvé pour me reconnecter à Github.

Je comprends rien à vos échanges. J’ose ! Et je me demande si vous pouviez m’aider... J’étais abonnée à uptobox qui a fermé. Peux plus télécharger les séries ! Auriez vous des infos ?
Sinon j’ai fait des petits commits sur seenthis-squelettes. Du text-wrap:pretty et du {This machine kills fascists}. Si quelqu’un veut pousser en prod.
Merci ! Si la mention « This machine kills fascists » ne permet pas de nous protéger contre les bots qui nous font grimper la charge, je ne vois pas ce qu’on pourra faire de plus…
J’ignore comment vous voulez procéder pour discuter sur Github. Je vous laisse m’indiquer où on cause.
Pour info, actuellement, ST c’est 240Go de fichiers, et 17Go de base MariaDB.





Bonjour, @olivier8 et bienvenue ici.
C’est un réseau assez différent des autres qui te permet de faire du microbloging, même si tu peux faire des billets super longs.
Tout ce que tu as besoin de savoir pour commencer est dans le carré « à lire » en haut à droite de la page d’accueil.
Une autre particularité sympathique du lieu, c’est que tu peux t’abonner également à des thèmes (ou en créer toi-même pour tes besoins en archivage) via les hachtags : ►https://seenthis.net/tags
Sinon, faut s’abonner à @seenthis pour quand on a des soucis précis avec la plateforme, mais souvent, les autres utilisateurs sont bienveillants.
Le moteur de recherche intégré est vachement bien et permet de trouver une grande variété de partages et de discussions.
À force, tu trouveras des seenthisiens qui ont des centres d’intérêt qui te plairont.
Dernièrement, il y a eu une discussion sur #duniter : ►https://seenthis.net/messages/652489
D’ailleurs, tu connais peut-être déjà @vincenttux ici.
Pour l’instant, il n’y a pas foule sur la #monnaie_libre, mais avec toi, ça viendra peut-être → ▻https://seenthis.net/recherche?recherche=%22monnaie+libre%22
Et aussi un lien qui parle de la libération du code de #seenthis, puisque je sais que pour toi ça compte → ▻https://seenthis.net/messages/154462

Le parking ici est gratuit, les données personnelles ne sont ni vendues, ni échangées.


@monolecte ça a l’air sympa et bien pensé !
@monolecte raah le saut de ligne se fait avec un saut de ligne contraire à FB...

@monolecte J’ai plusieurs questions :
– est-il possible de faire un backup de ses contributions ?
@odilon Si le parking est gratuit, comment sont financés les coûts du bazar ? Appel à contributions ?
– y a t-il un moyen de relier cela à Mastodon et Diaspora plutôt qu’à Twitter (que je vais aussi abandonner)
@vincenttux Clair qu’il va falloir doper la #monnaie_libre ici. D’ailleurs je viens de certifier @fil dont l’identité ne me semble faire aucun doute ;-)


salut à toi @olivier8 je prend les devants et te signale un intrus (f.carmignola) sur @seenthis
#seenthis ne sachant pas comment éradiquer ce morbac
tu peux effacer ses messages quand il te répond ou choisir de le bloquer. Ceci est aussi valable pour @palestine___________
▻https://seenthis.net/messages/656343
►https://seenthis.net/messages/653239

@olivier8 pour les backups tu as plusieurs options :
– utiliser l’API ►https://seenthis.net/fran%C3%A7ais/mentions/article/api
– utiliser l’export XML depuis cette adresse seenthis.net/ ?page=xml_export
Et peut-être d’autres que j’oublie. Tu peux aussi utiliser la formidable extension pour Firefox qui permet d’importer tous tes posts en local afin d’y effectuer des recherches rapidement (à ce qu’il parait son auteur est sympa ^^) : ▻https://seenthis.net/messages/496352
comment sont financés les coûts du bazar ? Appel à contributions ?
Il y a un début de groupe de travail à ce sujet, mais je n’ai pas l’impression que ça avance des masses, malheureusement. Du coup, le site est hébergé gracieusement (depuis trop longtemps amha) par @biggrizzly en attendant que ça avance de ce côté. Une liste de diffusion existe pour discuter de ces aspects cf ►http://listes.rezo.net/mailman/listinfo/seenthis
Et pour tout ce qui concerne le code, c’est par ici que ça se passe ►http://github.com/seenthis
y a t-il un moyen de relier cela à Mastodon et Diaspora
Certainement en utilisant une passerelle comme IFTT qui importerait le flux RSS de tes posts vers ces réseaux cf ▻https://seenthis.net/fran%C3%A7ais/article/passerelle-twitter


Oui @vanderling éviter de le lire serait pas mal. Ceci dit « mon nom est Palestine » il peut le lire à l’infini histoire de remplir son cœur d’espoir et de se libérer l’esprit
Je pense plutôt que son cœur se remplisse de haine et qu’il ne se libère l’esprit en te lisant. L’ignorer est peut être la meilleure solution.
#troll_haineux

@vanderling oups ! j’ai cru que tu mettais @palestine___________ dans le même sac que Carmignola. J’ai eu très peur... Pardon pour la méprise.


@reka oui, mon billet à propos de l’intrus porte à confusion mais je suis rassuré @palestine___________ l’a bien capté.
Ce #morbac me guette toujours et j’ai supprimé un billet qui l’interpellait et qui n’était pas étoilé.
▻https://seenthis.net/messages/655734
Délicat, de la part d’un contempteur de tous les racismes, de toutes les islamophobies et de tous les fémicides.
@francoiscarmignola1 je te pisse à la raie.


fait suite à la discussion ici
▻http://seenthis.net/messages/289156#message301665
et les modifs du code sont visibles sur
►https://github.com/seenthis

Qui saurait svp m’expliquer comment fonctionne le petit bouton « traduire » qui apparaît sur les messages #seenthis en anglais ?

Le bouton fait une requête POST vers : http://seenthis.net/index.php?page=translate avec trois paramètres supplémentaires contenu, dest et source, respectivement le contenu à traduire, la langue de destination (par exemple fr) et la langue source (par exemple en).
Quand à savoir comment fonctionne exactement http://seenthis.net/index.php?page=translate il faut chercher dans le code source de #Seenthis disponible sur :
►https://github.com/seenthis
J’ai pas trouvé mais je suppose que c’est un relai vers l’API Google Translate :
▻https://developers.google.com/translate
(Je sais pas si je réponds vraiment à la question)
le filtre se trouve dans ▻https://github.com/seenthis/seenthis_squelettes/blob/master/php/traduire_texte.php
maintenant en plugin séparé sur la zone
▻https://zone.spip.org/trac/spip-zone/browser/_plugins_/traduire_texte

#svn2git is a tiny utility for migrating projects from #Subversion to #Git
▻https://github.com/nirvdrum/svn2git
exemple :
mkdir seenthis_sphinx && cd seenthis_sphinx/
svn2git svn://trac.rezo.net/seenthis/seenthis_sphinx --authors=../authors.txt --metadata --no-minimize-url --trunk /
(....log log log....)
git remote add origin https://github.com/seenthis/seenthis_sphinx.git
git push -u origin masteret tout le code de #seenthis est désormais déplacé vers #github : ►https://github.com/seenthis
– ping @severo

je viens de passer ma soirée à créer des issues avec tous les petits trucs à faire que j’avais dans mes notes
▻https://github.com/orgs/seenthis/dashboard/issues
vous pouvez en ajouter (et en résoudre !)

►https://github.com/seenthis/seenthis_squelettes/issues pour un accès sans inscription


Un nouveau moteur de recherche pour seenthis
Nous avons travaillé ces deux dernières semaines, avec @marcimat et @rastapopoulos, à la programmation d’un #moteur_de_recherche générique pour #SPIP, basé sur #Sphinx, et très adaptable à différents types de sites. En l’appliquant à #seenthis, on obtient un outil dont les caractéristiques sont assez intéressantes :
– opérateurs logiques (et, ou, non)
– recherche de mots parmi une liste
– #proximité
– des #facettes permettent par ailleurs d’affiner la recherche, en proposant des #hashtags et des @people liés aux mots demandés
– une facette de date permet de filtrer par année (2014, 2013, etc).
– enfin, on propose plusieurs tris (par pertinence, date, ou en mettant en tête de liste les messages les plus partagés)
Je vous laisse découvrir tout cela :
– le moteur lui-même : ▻http://seenthis.net/recherche
– la documentation : ►http://seenthis.net/fran%C3%A7ais/article/moteur-de-recherche
– le code d’#indexer, le plugin générique pour SPIP : ▻http://zone.spip.org/trac/spip-zone/browser/_plugins_/indexer/trunk
– le code du plugin qui l’adapte à seenthis : ▻https://github.com/seenthis/seenthis_sphinx
Commentaires et relevés de bugs sont très bienvenus.
Super bonne nouvelle : j’ai vraiment un mal de chien à retrouver d’anciens articles archivés. Merci pour votre travail.
Je viens de tester, c’est de la balle!

La recherche est sur le message ou sur le fil ?
Ça peut être intéressant de chercher des messages qui contiennent une image ou une vidéo ou qui a reçu des commentaires (dans le cas où on cherche un de nos messages et que ce sont des infos qui se retiennent bien).
Sinon une recherche sur le fil entier pour des messages qu’on recherche sur un sujet, par exemple si on cherche sur poutine et ukraine, ça peut rapporter pas mal de sujets en plus (surtout que souvent les billets sont taggés a posteriori par les autres membres)
Rechercher des fils dans lesquels des membres de seenthis ont participé ?
Bon c’est des idées en l’air, je sais pas s’il y a un réel besoin pour ça ?
La colonne de droite « follow » elle se base sur la recherche / les résultats ? Ça me met des comptes que je suis déjà en tout cas
Edit : ha non ça permet d’affiner la recherche en spécifiant un auteur, mais si j’ai fais ma recherche avec déjà un auteur, ça va sortir aucun résultat

Pas compris. J’ai essayé les # et je ne sais pas si je dois affiner les recherches parce que je me suis retrouvée dans un flux sans queue ni tête...bigre ! Je crois que je suis complètement crevée !

Je n’ai fait que quelques essais de recherche. Sans problème. L’interface est super claire et les affinages très bien venus.
Mais surtout, je vois des comptages. Alors, je n’ai pas pu m’empêcher…
Sur une entrée vide, on compte tout. Du coup, ça fait une super façon d’entrer dans les stats…
On a des unités statistiques différentes :
– pour les années, apparemment, il s’agit des billets (messages initiaux). Si tu implémentes un dépliement hiérarchique par mois, outre que ça permet de préciser le filtre chronologique (surtout utile pour l’année en cours), ça permettrait d’avoir l’activité mensuelle.
– pour les comptes (follow) et les tags, il me semble qu’il s’agit de toute l’activité (billet, commentaire, étoile)
Là aussi, peut-être un niveau hiérarchique inférieur permettrait de ventiler entre ces 3 types d’activités (ce qui permettrait de préciser quand on cherche une réponse dans une discussion)
Du coup, les totaux n’ont pas de raison de coïncider. Si mon interprétation est bonne, il y a eu (et il subsiste après effacement des comptes) 120000 billets (ça change tout le temps…) et comme le numéro du dernier est autour de 260400, cela fait de l’ordre de 1,2 « activité complémentaire » (commentaire ou étoile) par billet.
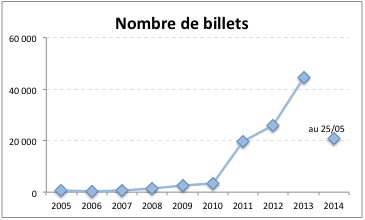
Juste pour voir, j’ai fait le suivi du nombre de billets par année.
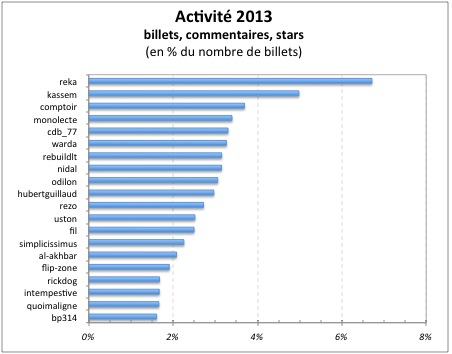
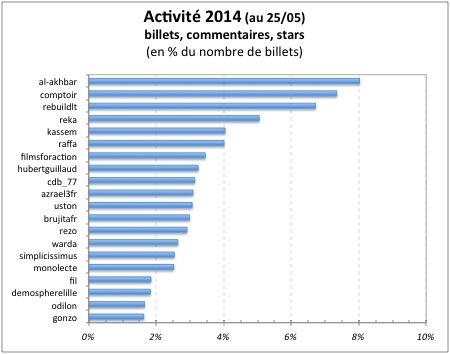
Et l’activité des top 20 (en % du nombre de billets)
(pour 2010, la somme des 20 follows fait 3548, alors que le nombre de billets est de 3520)
2013
2014
Éventuellement, un nouveau bloc par nombre « d’activité complémentaire » pour classer les billets par intensité de la discussion ou des étoiles (souhait qui a été exprimé, me semble-t-il).
Encore merci. Et bravo pour l’interface « naturelle » ou « invisible ».
Jolies déductions :)
La facette « follow » est établie sur la base de l’attribut multivalué {auteur initial + partageurs}. Les intervenants dans la discussion ne sont donc pas comptés en tant que tels (ils sont indexés dans un autre attribut, mais pas utilisés dans l’interface : l’idée est que si je ne partage pas un billet, mes suiveurs n’ont pas forcément vocation à être alertés que je suis en train d’y discuter).
Chacune des facettes, comme tu l’as constaté, est limitée aux 20 éléments ayant le plus fort effectif, et à condition qu’il soit > 1.
Le système recense à cet instant 156548 billets publiés. Il existe des billets effacés (11197 dont une trace reste dans le système, sans compter ceux de quelques tests, ou du compte machin, qui ont carrément été supprimés).
Pour ce qui est de fouiller plus avant dans les données, je pense qu’il sera plus efficace de créer des requêtes ad hoc. Le langage d’interrogation, très proche du SQL, est assez parlant.
Par exemple pour avoir le nombre de billets publiés mois par mois :SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
La même chose pour les billets qui répondent à un critère fulltext :SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where MATCH('spip') AND properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
etc.
Concernant la suggestion de trier selon l’intensité des discussions : il n’y aurait aucun obstacle technique, sachant que les éléments nécessaires (liste des participants à chaque discussion) sont déjà indexés. En revanche, il me semble qu’il s’agit d’une fausse bonne idée : j’ai comme un doute en effet sur l’intérêt de mettre en valeur des discussions qui impliqueraient de nombreuses personnes, mais qu’aucune ne souhaiterait partager…
La vocation du moteur de recherche est de permettre de trouver aussi rapidement que possible une information précise, les décisions doivent se baser uniquement là-dessus, pour cette page en tout cas. Mais l’outil permet d’imaginer d’autres « vues » sur les données, qui pourront servir à l’administration du serveur, à créer des pages annexes, à repérer des « corrélations » entre les sujets, des proximités entre auteurs, une analyse du « dictionnaire » global, et que sais-je encore. Tout un champ à explorer !
PS : la doc de SphinxQL : ▻http://sphinxsearch.com/docs/current.html#expressions
Tu sais que l’utilisateur est d’abord et avant tout pervers : il utilise les outils qu’on lui donne pour faire tout autre chose avec… Et, donc, oui je sais qu’il s’agit de recherche, pas de stats. Tavaikapa mettre des comptages.
Blague à part, en fait, je ne sais pas comment faire pour rentrer dans les tables de ST à des fins statistiques. À l’occasion (R ?), je jetterais bien un œil…
Oui @fil, pour la mise en avant des discussions « chaudes » (celles ayant le plus de participants et/ou celles ayant le plus de messages), je ne voyais pas ça spécialement dans la page de recherche. Mais dans une autre vue à part ce serait bien oui.
(Dans le même thème, un truc qui pourrait être bien, hors interface, ce serait aussi un flux Atom des commentaires postés par les gens qu’on suit.)
(une loi qui porte mon nom la classe .. ah mince c’est moi qui l’ai créée...)
Le menu pour affiner la recherche par facette semble avoir des bugs :
▻http://seenthis.net/recherche?recherche=%23permaculture+%40nicolasm+%23agriculture
– le tag agriculture n’est pas déjà coché dans le menu
– si je clique sur le tag alimentation ça me met cette url = ▻http://seenthis.net/recherche?recherche=%23agriculture&tag=%23alimentation (ça vire mon pseudo et le tag permaculture) alors que j’imaginais que ça rajoutais le tag alimentation en contrainte supplémentaire ? Même souci avec les facettes par auteur pour ▻http://seenthis.net/recherche?recherche=%23agriculture+
Ah, cool ! C’est possible d’obtenir les résultats sous forme de RSS ?

@homlett le moteur est accessible en RSS et en JSON :
▻http://seenthis.net/?page=sphinx.rss&recherche=sphinx
▻http://seenthis.net/?page=sphinx.json&recherche=sphinx
Attention c’est de la version alpha, je changerai probablement les URLs une fois que ce sera testé et stabilisé.
À noter les deux flux proposent des données complémentaires : uri, title, date, @login de l’auteur, tags et « snippet », c’est-à-dire l’extrait du contenu avec les mots repérés mis entre <b> (à styler comme tu veux, le gras rendant assez moche).
Ce qui manque je pense, à ce stade, c’est de pouvoir personnaliser (faire « mes messages » ou « messages de mon réseau » plutôt que « Tous les messages »).
En fait, j’ai beaucoup utilisé le moteur hier pour écrire mon dernier papier et je suis ravie de la facilité avec laquelle j’ai pu retrouver toutes les sources dont j’avais besoin. Souvent, j’associe deux termes pour mieux cibler ma recherche, et sans avoir besoin de me prendre la tête avec les opérateurs booléens, j’exhume très rapidement ce que je mettais des heures à chercher jusque là (et que je ne retrouvais généralement pas !). J’aime beaucoup le surlignage des termes recherchés et la possibilité de trier les résultats par date ou pertinence, de limiter par année, auteur, me ravit littéralement.
Je n’ai pas eu de bugs, pas de problème et mes requêtes ont toutes abouti.
Donc désolée de ne pas aider plus que cela, mais je suis juste la ravie de la crèche qui pensait depuis un bon moment que le gros défaut de Seenthis, c’était de ne jamais rien y retrouver !
@fil OK, c’est noté. Merci en tout cas, c’est top et ça manquait vraiment ! Par contre c’est vrai que <b> c’est moyen. Pourquoi pas un <span> ou même <em> ? Mais c’est pas très important.
En tout cas ça va permettre de faire de la veille sur #seenthis, @seenthis et seenthis ! ;-) ( ▻http://seenthis.net/messages/256466 )
Peut-être puis-je émettre un bidule qui serait bien pratique mais je ne sais pas si c’est le sujet de cette discussion. Serait-il imaginable de mettre une étoile à côté d’une réponse. Car parfois, il y a des réponses qui mériteraient d’être mentionnées dans les recherches. Voir des possibilités d’y répondre....
je ne vois pas le lien entre étoile et réponse de recherche ?
en effet c’est hors-sujet :)
pour gérer le développement de seenthis, on vient tout juste de mettre en place un compte github où vous pouvez envoyer des issues (problèmes ou demandes de fonctionnalités) et des pull-requests (des modifications du code source).
►https://github.com/seenthis

Est-ce qu’une migration vers SPIP 3 est prévue ?

Une petite amélioration du moteur : la recherche se fait désormais à partir de la racine des mots (lemmatisation) ; ainsi le moteur trouvera les messages contenant aussi bien le pluriel que le singulier, ou bien diverses formes des verbes conjugués (c’est censé fonctionner pour l’anglais et pour le français).
Si, à l’occasion, vous souhaitez rechercher la forme exacte d’un mot, utilisez l’opérateur = ; par exemple, une recherche de =terres évitera les messages contenant le mot terre au singulier seulement.
(Et pour répondre à @nhoizey : il me semble probable que les plugins seenthis fonctionnent déjà pour la plupart avec SPIP 3, je n’ai pas essayé mais je ne vois pas ce qui pourrait bloquer. Si dans tes tests tu vois des bugs, n’hésite pas à les signaler ou à envoyer une pull-request sur ►https://github.com/seenthis )


Bonjour
On m’a dit de m’adresser ici si je ne comprenais pas quelque chose.
Comme par exemple : comment faire pour afficher sur sa page personnelle un billet d’un autre utilisateur ? Il faut le mettre en favori, c’est tout ?
Je n’ai pas trouvé le bookmarklet en page d’accueil qui, paraît-il (dixit la page « le minimum à savoir »), transforme complètement le confort d’utilisation.
Merci d’avance !

Bonjour @bruno2, bienvenue !
Oui, c’est ça, pour afficher sur sa page le billet d’un autre, il suffit de le mettre en favori. C’est une fonction « repartage ».
Pour le bookmarklet, il est sur la page d’accueil ►http://seenthis.net, dans la colonne de droite, juste après À lire.
Autre question, tant que j’y suis :
Y aurait-il quelque part un badge seenthis que je pourrais coller sur mes sites perso pour guider mes visiteurs vers ma page ?
Non, on se le fabrique soi-même... #DIY
Bon, OK.
Autre question :
Pour suivre un thème, je n’ai pas trouvé d’autre moyen qu’utiliser le moteur de recherche, chercher le thème avec le # dans la page et cliquer dessus, puis ensuite faire « suivre le thème ».
Il n’y a pas moyen de faire plus simple ?
Fondamentalement plus simple, je vois pas comment. Mais il y a un lien « thèmes » dans le bandeau du haut, vers ►http://seenthis.net/tags avec la liste des thèmes/tags suivis.
Tu peux aussi directement taper l’url http://seenthis.net/tag/THEME_EN_QUESTION
À savoir : si par exemple tu suis le thème #seenthis, tu suis avec ses sous-thèmes : #seenthis_doc, #seenthis_todo, etc. Mais bien sûr, pas l’inverse.
Autre chose : devant chaque liens partagés, il y a un triangle. S’il est blanc, l’url n’a été partagée qu’une fois. S’il est noir, l’url a été partagée plusieurs fois. Et un clic sur le triangle renvoi vers la liste de tous les posts où elle apparait.
Last but not least, la mise en forme :
– du gras en encadrant avec le signe *
– de l’italique avec le signe _
– du code avec le signe `
– des citations avec Shift+Tab
Quand tu es connecté, tu ne vois que ceux auxquels tu es abonné. Sinon, tu vois les posts de tout le monde.
Pour voir les postes de tout le monde quand tu es connecté, c’est ►http://seenthis.net/all
Sauf que cette page « all » n’est liée nulle part, et que donc personne ne peut la deviner, nouveau ou pas (moi-même je ne m’en souvenais plus).

Bonjour et #merci,
J’utilise la recherche avec recherche ?annee=2016&order=stars
J’aimerais pouvoir ajouter quelque chose comme &moisdelannee=2
Y-a-t-il une syntaxe adaptée à ce désir ?
Pour le moment non, et je me demande si ça ne serait pas plutôt quelque chose comme date=2016-02 qu’il faudrait faire. À discuter sur ►https://github.com/seenthis/seenthis_squelettes/issues ?

Le #code_source de #seenthis est disponible :
Accès Web à l’adresse
▻http://trac.rezo.net/trac/seenthis/browser
Checkout subversion :
svn co svn://trac.rezo.net/seenthis/
Méthode d’installation :
►http://trac.rezo.net/trac/seenthis/browser/plugin_seenthis_principal/INSTALL.txt
et viva el #logiciel_libre


Il manque une indication de la license non ?


probablement GPL 3 mais ça pourrait être la WTF licence (me dit-on @james)


reste plus que le rendre compatible spip 3.x
tu t’y colles @albert ? :)
\o/ yeah super merci !
Et juste par curiosité : pourquoi pas sur spip-zone ? Pour que les futurs commits soient plus contrôlés ? (et report des quelques trucs génériques qui sont aussi sur la zone ?)
Merci pour la constructivité de tes commentaires @albert ! :D (tu m’as fait gagné un pari :p)


De source sûre, authentifiée par mes soins mais sans recoupage connu (je le tiens de l’auteur quoi), la GPL v.3 se cache derrière tout ça @james @thibnton #seenthis_licence
\o/
Merci, je sens que je vais m’y remettre du coup !

@rastapopoulos seenthis n’est pas un complément de SPIP mais juste un site parmi d’autres, qui se trouve utiliser SPIP. D’où l’idée de continuer à le développer sur le repo SVN où il a commencé.
Ouais, c’est plus ou moins pas faux, je comprends tout à fait le principe hein. :D
En fait dans mon esprit actuellement « un site » c’est : « des squelettes + un thème graphique ». Ces morceaux-là étant propres au site en question (et encore, ça peut éventuellement être rendu générique si ya pas une image de marque à garder). Tout ce qui est fonctionnel et qui n’est pas propre à un usage d’une seule personne (tel client, telle assoc, ou soi-même) est alors de fait générique, donc « un complément de SPIP » : ajouter tel objet éditorial, utiliser une autre syntaxe, reconnaître et gérer les hashtags dans un contenu, etc, etc. Les squelettes du site étant une agrégation publique de ces fonctionnalités.
À partir du moment où on accepte que d’autres installent peu ou prou le même site, j’ai tendance à penser que ce genre de configuration est alors une distribution de SPIP (une suite de fonctionnalités génériques, avec un squelette par défaut), et non pas un site parmi d’autres.
Enfin je sais pas si je suis très clair. Et de toute façon on a pas encore affiné le principe (ni abstrait ni technique) des distributions, donc c’est un peu dans le vide que je dis tout ça...
Mais c’est à peu près comme ça que je conçois le truc dans ma tête (et oui j’ai un peu une obsession pour les trucs « génériques », où les fonctions sont au maximum séparées/modulables). Je préfère quand même le noter là, plutôt que le garder dans ma tête et l’oublier. :p
Ce serait d’ailleurs top que Seenthis soit « tout simplement » un plugin, avec des dépendances, qu’on puisse ajouter sans soucis à un SPIP existant, les contenus se logeant par exemple dans une rubrique.

@Fil D’abord, il faut dire « logiciel libre » et pas « au pène source ». Ensuite, il y a plein de projets intéressants et pas assez de temps.
Et puis je suis vexé que mon succès installatoire soit dénigré et retrogradé au rang de tentative ! Sans compter mes contributions à la documentation du schmilblick ! ►http://seenthis.net/messages/154085
Par contre, ma deuxième installation est restée tentative à ce jour : il s’agit de créer un seenspip mais à ce jour il est hors de question que moi j’installe encore ça sous SPIP 2.1, quoiqu’on en dise ou pense. Du coup, ça attend que j’ai le temps (beaucoup) pour réécrire les déclarations de tables et toussa.

@fil J’en suis à l’étape « Activation du site » de la documentation et tout s’est bien passé jusque là :) J’ai juste fait une pause dans le process d’install ...
Mon but est de jouer avec ça ►http://seenthis.net/messages/216935 + une install sur mon domaine.
Allez je me remotive !

Vu qu’une communauté forte est à Seenthis.net je ne vois pas de motivation à déployer d’autres instances tant que l’abonnement inter-instances n’est pas possible.
Pour info :
1/
Impossible d’activer le plugin ../plugins/opensearch
Nécessite le plugin SAISIES en version [1.1 ;] minimum.
Perso, je l’ai pas activé, mais en ajoutant le plugin en question, ça passe.
Il faudrait ajouter à la doc dans la liste des plugins :
``svn co svn://zone.spip.org/spip-zone/_plugins_/saisies/ saisies/``
2/ pour configurer gravatar, j’ai l’erreur suivante :
Filtre sinon_interdire_acces non défini ../plugins/gravatar/prive/squelettes/contenu/configurer_gravatar.html
==> ▻http://contrib.spip.net/Gravatar#forum474234 :-)
Correction : ajouter CFG à la liste des plugins à installer, grml :p
``svn co svn://zone.spip.org/spip-zone/_plugins_/cfg/branches/v1 cfg/``
3/ bien évidement, pensez à activer l’inscription de nouveaux rédacteurs (<ecrire/?exec=config_contenu#configurer-redacteurs>) :)
Hop @james pourtant la doc indique bien :
Si vous avez installé les plugins CFG et Saisies, la page de configuration du plugin est accessible à l’adresse ecrire/ ?exec=cfg&cfg=opensearch (menu CFG => onglet OpenSearch).
Que faire de plus ?
yo mignon :) Que faire de plus ? ajouter à la doc de seenthis, qu’il faut installer Saisies ;-)
haaa je croyais que tu causais de la doc de saisies ;)
l’adresse a changé, on vient de tout mettre sur github :
►https://github.com/seenthis

Cooool. Il est dans un de ces modules le bug qui rajoute des espaces devant les ponctuations hautes ?
@Fil « microblogging » Comme Twitter ? Ce n’est plus du « shortblogging » ?