SPIP
▻http://autodoc.magraine.net/spip-dev/zora/apis.html
autodoc de SPIP : les API triée par type
SPIP
▻http://autodoc.magraine.net/spip-dev/zora/apis.html
autodoc de SPIP : les API triée par type

Pourquoi ne pas documenter tout ça dans le glossaire officiel ? ►http://www.spip.net@
Tiens, il y a un bug quand on pointe sur le site de Spip (non seulement le site est annoncé en italien, mais en plus, l’arobase n’est pas incorporé au lien. )


Parce que c’est un job en cours et qui donc est encore incomplet (mais @marcimat abat un boulot dingue). A terme je crois que ce site devrait prendre place sur quelque chose comme ▻http://doc.spip.org ?

Rah, mais qui est-ce qui envoie des liens de trucs en plein chantier ?
C’est un espace qui me permet de tester le phpdoc qu’on met au fur et à mesure dans le code source de SPIP. Et c’est une documentation automatique et non traduite, contrairement à spip.net. Et ça ne documente que les fonctions du code source, par exemple la balise TITRE n’y est pas (puisqu’elle n’a pas de fonction associée).
Enfin, oui, derrière tout ça il y a l’idée de reprendre doc.spip à terme… C’est un peu expliqué là ▻http://blog.smellup.net/spip.php?article59 . L’idée est peut être d’avoir un endroit où tout le code source est documenté (ce que je fais avec autodoc), et un autre, différent et plus construit autour des APIs, permettant une interaction (forum à la php.net), avec une documentation qui ne serait pas uniquement issue du code source
Même si ça avance, c’est long à faire (surtout pour documenter) et d’autre part le logiciel phpDocumentor est une nouvelle fois en pleine refonte (voir ▻https://github.com/phpDocumentor/phpDocumentor2/issues/735) pour intégrer TWIG et pouvoir l’utiliser encore plus facilement. Ce qui va nécessiter une grande reprise du code de ce site (autodoc), mais accélérera fantastiquement sa génération (il utilise déjà Twig, mais avec plein de requêtes xpath() sur un gros XML, c’est assez long).
Voilà ce que je peux en dire.
Et enfin, il vaut mieux suivre ▻http://autodoc.magraine.net/spip-dev/zora car c’est sur la branche dev que le phpDoc est intégré pour l’instant.
oups ! super désolé : ce lien aurait du rester en mode « private » sur mon delicious et donc ne pas être visible sur seenthis...
Je le vire si tu préfère
C’est pas grave hein ! Y a une discussion du coup ▻http://thread.gmane.org/gmane.comp.web.spip.devel/63965 pour savoir ce qu’on en fait :)

A wonderful file system, #pifs (also spelled πfs) to store the files in the number #Pi. Since Pi is normal (in the mathematical sense), every possible file is present in Pi (side note: which means that Pi violates every existing #copyright). So, storing a file is just remembering where in Pi it is located and what its length is. But read the documentation, it is well explained:
▻https://github.com/philipl/pifs
#geek

hum ... mais est-ce que le stockage de l’adresse dans π ne risque pas d’être plus grand que le fichier lui même ?
J’ai un fichier de 40 Ko mais la séquence est à la 300 milliardième décimale ? La taille de l’adresse devient plus importante que la taille du fichier ?
(disclaimer : question de béotien).
Dans ce cas, non : pour stocker des adresses jusqu’à 300 milliards, 35 bits suffisent, soit bien moins que 40 ko.
Mais pifs utilise plein d’astuces pour optimiser le stockage, comme de découper le fichier en petits morceaux (car un fichier de 40 ko peut être beaucoup plus loin que la 300 milliardième décimale et donc prendre un temps fou à être trouvé).



@thibnton Si on veut pinailler, on peut noter que la normalité de Pi est conjecturée mais pas encore prouvée. Un matheux ambitieux pour faire cette démonstration ?

Ce lien ▻http://tpepi.free.fr/complexite.php m’a bien aidé à comprendre de quoi on cause ici. Heureusement qu’il y a de bons vulgarisateurs dans ma langue maternelle :p

Deux lecteurs, intéressés me font parvenir les questions suivantes :
• Calimero : et si MON fichier est LE contre-exemple de la normalité de π ? Il n’y a même pas une prime pour invalidation de la conjecture qui viendra me consoler…
• Ahasverus : et si l’adresse de mon fichier est loin (mais vraiment…), j’ai intérêt à être patient : la lecture se fait bit par bit avec un algo de type Bailey-Borwein-Plouffe, temps de calcul croissant avec le rang du bit…

@simplicissimus : tu as, semble-t-il, déjà la réponse pour Ahasverus : il semble qu’en fragmentant un fichier, tu trouves l’adresse des petits morceaux plus vite avec l’algo de Plouffe (hi hi). Et du coup, c’est ce que je trouve le plus curieux, et original, fragmenter un fichier deviendrait une « optimisation ».
Ahasverus, très réactif car très motivé, m’indique qu’il est un peu inquiet. Le découpage en paquets « plus faciles » à trouver lui évoque furieusement les difficultés qu’il éprouve parfois à remplir sa besace. Vu son grand âge, son vocabulaire est parfois un peu dépassé, je crois qu’en langage moderne cela s’appelle le problème du sac à dos ▻http://fr.wikipedia.org/wiki/Problème_du_sac_à_dos
Il avait bien envisagé de monter une solution de backup en plaçant une équipe de singes derrière des claviers d’ordinateurs, mais des calculs de dimensionnement (récents ?) lui laisse entendre que cela ne réglerait pas vraiment le problème de temps de réponse… ▻http://eva.almassy.free.fr/le.singe/Page_3x.html

J’apprends grâce à Wikipédiq qu’il existe des nombres interdits, par exemple parce que copyrightés : ▻http://en.wikipedia.org/wiki/Illegal_prime
Inne frainche oueurdze ▻http://fr.wikipedia.org/wiki/Nombre_premier_illégal
mesure #r128 avec #FFmpeg
▻http://ffmpeg.org/ffmpeg-filters.html#ebur128
EBU R128 scanner filter. This filter takes an audio stream as input and outputs it unchanged. By default, it logs a message at a frequency of 10Hz with the Momentary loudness (identified by M), Short-term loudness (S), Integrated loudness (I) and Loudness Range (LRA).
Malheureusement :
▻https://ffmpeg.org/trac/ffmpeg/ticket/2144
libavfilter ebur128 loudness inaccuracy, irregular time interval, LFE interference
Donc, pour le moment, :
►https://github.com/jiixyj/libebur128
reste nécessaire !
(D’aileurs je me demande bien pourquoi FFmpeg n’a pas repris cette bibliothèque pour implémenter la mesure loudness plutôt que tout réécrire).
#libebur128 #open-source
HTML KickStart - Ultra–Lean HTML Building Blocks for Rapid Website Production - KickStart your Website Production - 99Lime.com
▻http://www.99lime.com

C’est un #framework #HTML/#CSS et #javascript comme Bootstrap quoi ?
Euh, oui. Enfin le responsive semble pas être la priorité. Mais la plupart des balises html sont implémentées si j’ai bien vu. Je suis retombé dessus 3 fois en quelques semaines en étant à la recherche d’onglets, de colonnes, de... Voilà.
▻http://www.99lime.com/blog/html-kickstart-is-dead-long-live-html-kickstart
Ah ben grand nettoyage : le machin est responsive désormais mais perd (temporairement dit-il) quelques features...
I have also removed some seldom-used features in preparation for some new UI elements that I will be adding soon.
Removed Features
Media Elements
Video Placeholder
Map Placeholder
Calendar Placeholder
Form Elements
select.fancy
select multiple.fancy
Image Styles 1, 2, & 3
ScrollTo and LocalScroll
▻http://www.99lime.com/blog/html-kickstart-is-responsive
#ça_vit_encore ;-)

cool ... On veut des benchmarks !!!! des graphs de comparaison entre SPIP | Fulltext | sphinx
Il y en a comme ça qui se demandent sur ►http://irc.spip.net si des fois #SolR aurait été testé avec SPIP ?
▻http://lucene.apache.org/solr
▻http://www.ftopia.com/fr/2011/03/25/passage-de-sphinx-a-solr
pour le moment ça m’attire pas tellement d’installer une grosse machine en java alors que sphinx est léger, facile à installer, et tellement rapide ! La dernière version permet en plus d’indexer finement des données structurées en JSON (donc sans schéma préconçu dans l’index), ce qui résoudra nombre de problèmes signalés.

Est-il possible d’empaqueter le plugin ?
Je veux dire par là générer le fichier ZIP. Je vais voir ce que je peux faire.
Je me demandais si ce qui était fait était :
1. le signe (de la galère)
2. le zip / paquet.
Réponse 2 ! ▻http://zone.spip.org/trac/spip-zone/changeset/81390 :-)
Quelqu’un a-t-il déjà écrit un fichier de configuration Sphinx pour SPIP 3 ? Ça me ferait gagner du temps :)

@thomasschmit oui, on a tenté d’en écrire un générique la semaine dernière :
▻http://zone.spip.org/trac/spip-zone/browser/_plugins_/indexer/trunk/doc/Configuration%20Sphinx.md
Avec « content » qui contiendrait la concaténation de tout ce qu’on veut pouvoir chercher en fulltext. Et dans « properties » les métadonnées ou tout autres informations en plus : dates (il peut y en avoir plusieurs), géographie, auteurs, tags, rubriques, hiérarchie complète, prix, etc.
Tu peux suivre ce nouveau plugin « indexer », c’est une manière de faire plus « moderne » (ou tout du moins plus adapté) que l’autre. Avec un index Real Time qu’on peut interroger en direct en permanence à base de requêtes pseudo-SQL avec « select » mais aussi ajout (replace ou update).
Ah j’oubliais : « properties » tu lui envoies une chaîne JSON, donc tu y mets vraiment ce que tu veux, et avec la profondeur que tu veux. Après dans les requêtes tu peux demander « properties.date », « properties.geo.lat » (clé d’un sous-tableau), « properties.tags » (tableau complet), etc.

Oui @fil pardon, je n’avais pas vu qu’il n’était pas encore intégré à ce fil de discussion.
De mon côté, ça ne semble pas fonctionner. Lorsque j’essaie d’indexer, par l’intermédiaire de la page ▻http://www.exemple.fr/ecrire/?exec=indexer, j’ai l’erreur suivante :
Array
(
[0] => Array
(
[errno] => 1064
[sqlstate] => 42000
[error] => unknown column: 'properties'
)
)
Bourrin … mais efficace ! Le site est indexé.
Merci :)
Bon, je galère ! Même avec une boucle toute simple, la recherche ne fonctionne pas bien.
Voici la boucle :
<B_recherche>
#SPHINX_QUERY
<ul>
<BOUCLE_recherche(SPHINX)
{index spip}
{recherche #ENV*{recherche}}
{!par date}
{pagination 25}
>
<li>#TITLE - #DATE</li>
</BOUCLE_recherche>
</ul>
#PAGINATION
</B_recherche>En fait, d’après les logs, seules les requêtes de moins de deux caractères sont transmises à Sphinx. C’est très bizarre. Aurais-je oublié quelque chose ?
Hum… Où est-ce que l’on peut en discuter ?
salut baron @speciale, c’est corrigé :
▻https://github.com/seenthis/seenthis_sphinx/commit/f2b11

Quel est le meilleur moyen de récupérer ses seens sur #seenthis (hors screen scraping) ?
Il y a le RSS, mais il n’a (naturellement) pas tout depuis le début. J’ai regardé la page API mais elle ne cause que de poster des messages.
Je dis ça c’est pour les synchroniser dans Evernote, dont je me sers pas mal notamment quand je ne suis pas connecté.
tu peux les télécharger tous d’un coup dans un format xml
►http://seenthis.net/fran%C3%A7ais/mentions/article/propri%C3%A9t%C3%A9-intellectuelle
et il existe déjà deux « clients », l’un en python, l’autre en php :
►https://github.com/bortzmeyer/seenthis-python
►http://seenthis.net/messages/30043
je ne suis pas satisfait de ce fonctionnement, ça devrait être beaucoup plus simple — un accès IMAP ou WebDAV par exemple...
Ah, super, c’est exactement ce que je voulais. Le seul truc : ça me donne toujours <text></text> pour tous les seens.
Perso ça me va comme fonctionnement (même si du JSON serait encore plus simple). IMAP c’est lourd. WebDAV ça peut être mieux, mais il y a quand même des problèmes d’interop.
A la limite, pour éviter de devoir faire un dump intégral d’un coup, on peut songer à un paramètre since= (qui pointe sur une date ou un ID) pour ne récupérer que ce qui vient après.
Je comprends, mais je maintiens que IMAP c’est lourd — et les clients ont tendance à être pourris.
Le problème de sync dépend largement de savoir si c’est unidirectionnel ou bidirectionnel (ou plus...). Pour de l’unidirectionnel, juste pouvoir demander les changements depuis tel ID ou telle date suffit normalement.
Pour du bidirectionnel ça pourrait être intéressant de regarder du coté de git (qui a une API HTTP depuis quelques temps).


Ubuntu 12.10 Quantal - Script de post install | Le blog de NicoLargo
▻http://blog.nicolargo.com/2012/12/ubuntu-12-10-quantal-script-de-post-install.html
Pour rappel, ces scripts sont un moyen simple et modulaire de faire automatiquement un ensemble d’actions après l’installation standard du système d’exploitation.
Préparer l’arrivée de Precise Pangolin avec un script de postinstall | Le blog de NicoLargo
▻http://blog.nicolargo.com/2012/04/preparer-larrivee-de-precise-pangolin-avec-un-script-de-postinstall.
Les dernières versions de ce script (pour les distributions Ubuntu 11.04 et 11.10) étaient développées en Shell Script (BASH). Afin de simplifier le développement, j’ai donc décidé de re-développer complètement le script en Python en lui apportant une fonction de personnalisation par fichier de configuration.
Sur une idée originale de @nicolargo je commence donc ma petite liste (si un jour je doit réinstaller ma ma machine)
▻https://github.com/benchti/post_ubuntu/blob/master/post_install.sh

Seafile
►http://seafile.com/en/home
Seafile can sync a file library among all of your computers. Whenever you add, delete or edit a file, the latest version will appear in everyone’s computer. No more email headache! In addition, Seafile keeps older versions of the files online. It’s easy to restore a file to an older version.
Peut-être enfin une vraie alternative à #dropbox libre et auto-hébergeable ?

Et one.ubuntu vous en pensez quoi ? il y a une appli avec.
Oups, ok, c’est pas versionné bien sur…

And two. Je joue mais faut m’expliquer je suis informatiquement analphabète.
À noter que le client de synchronisation d’#owncloud s’améliore nettement également, à en juger par la dernière beta :
▻http://dragotin.wordpress.com/2012/12/21/owncloud-client-1-2-0-beta1
Si vous voulez un groupe Seenthis sur cloud.seafile.com :
▻http://cloud.seafile.com/group/281
Par contre je ne sais pas si on peut faire une demande pour rejoindre un groupe ou si l’admin du groupe doit ajouter les membres manuellement...
J’ai pu m’inscrire au groupe 281 tout seul, et j’ai créé le groupe 283, donc j’ai l’impression qu’on peux s’inscrire sans avoir nécessairement l’autorisation de l’admin
j’explore, je joue, je teste
J’ai pas trouvé d’infos sur le type de licence et c’est en beta. Tu as un lien pour confirmer que c’est libre ?
Sinon, on a crée ▻http://cloud.seafile.com/group/279 :)
Ah non pardon pour 283, je me suis trompé, le message dit que c’est l’admin qui inscrit sur demande. Quand je disais que j’étais analphabète.

@james gplv3 : ▻https://github.com/haiwen/seafile/blob/master/LICENCE.txt
Et je pense que ce sont les 5Go d’hébergement sur leur serveur qui sont en beta, le soft est indiqué comme étant ok pour être en production.

@reka pour rejoindre le groupe il faut que je t’ajoute manuellement après avoir reçu ta demande. Mais je vais supprimer le groupe 281, je propose d’utiliser le 279 plutôt.
D’ailleurs j’ai été ajouté au 279 sans même être averti, on dirait...
Oui, gardons le tas de sable, et oui c’est marrant j’avais l’impression d’avoir été inscrit automatiquement :) Je vais aussi supprimer le 283 qui n’était qu’un test
c’est drôlement sympa de recevoir des messages d’un logiciel libre chinois :
您好:
您有1条新消息,请点击下面的链接查看:
▻http://cloud.seafile.com/home/my
感谢使用我们的网站!
Seafile团队
La traduction automatique proposée sur SeenThis rame lamentablement.
Quant à celle de Google, pour moi, c’est la toute première fois qu’on dirait pas du Google Translate ;-))
c’est moi qui vous ai ajouté ;)
merci pour l’info sur la licence :)
@simplicissimus même réflexion ici, je viens juste de le skyper à @fil. Superbe traduction, bien meilleure que ce que j’ai vu avec le norvégien ...
Moi je dis, il vaut mieux le skyper à fil que le filer à skype.
(Je suis déjà dehors, et pourtant ça caille)

j’ai reçu l’invitation pour le 283 et je me suis inscrite mais je ne sais pas pourquoi faire :)
Bon, j’ai installé la partie serveur sur un serveur dédié perso, et mes premières impressions au bout de quelques jours sont extrêmement positives :
– pas de plantage pour l’instant
– synchro aussi transparente et efficace qu’avec Dropbox
– vitesses de transfert des fichiers bien supérieure à celle de Dropbox
– possibilité de chiffrer les données sur le serveur de manière très pratique et transparente
Au niveau des « inconvénients », mineurs :
– lorsqu’on partage des fichiers, pas de vue « galerie » pour les photos et vidéos
– client mobile sous Android pour l’instant assez simple
– la partie serveur nécessite d’ouvrir trois ou quatre ports sur son firewall
Bref, en ce qui me concerne c’est du tout bon, et le développement du projet est très actif.
–—> – lorsqu’on partage des fichiers, pas de vue « galerie » pour les photos et vidéos
ça c’est un peu dommage, mais j’imagine que c’est une amélioration qu’on peut leur suggérer ? et peut)-être pas trop difficile à mettre en plac ? y a t il un ou des contacts "humains" ?
On peut évidemment leur suggérer, je ne sais pas si ça sera prioritaire pour eux car le public visé semble davantage « équipes de travail » que « photos de famille ».
Le plus simple est sans doute d’ouvrir un ticket sur le github du projet :
▻https://github.com/haiwen/seafile/issues?page=1&state=open
Ou de poster un message sur leur Google group :
▻https://groups.google.com/forum/#!forum/seafile
En fait il semble que la prévisualisation des images soit fonctionnelle ou dans les tuyaux :
▻https://groups.google.com/forum/#!topic/seafile/UjnbBb43doQ
Hi hi ! c’est vrai mais l’aspect « photo de famille » peut-être très efficace pour l’équipe avec laquelle on travaille, je vois bien que quand j’envoie une « gallerie » de carte à la rédac plutôt qu’une liste, on gagne beaucoup de temps ... :)

Le groupe continue ? Merci @Juba pour le test serveur
Et un article élogieux pour la sortie de Seafile-2.1 et l’intégration dans ’buntu :
Cloud Sync Tool Seafile 2.1 Released ~ Web Upd8 : Ubuntu / Linux blog
▻http://www.webupd8.org/2014/01/cloud-sync-tool-seafile-21-released.html
Seafile is an open source cloud synchronization and collaboration tool that you can install on your own server. It comes with desktop clients for Linux, Windows and Mac as well as mobile clients for Android and iOS.
Seafile features: file libraries (can be synchronized separately), wiki module, group discussion module, online rich document / markdown editor, file revisions, file preview, event notifications, library encryption, audio / video playback support and more.
The tool uses a version control model somewhat similar to GIT but with some differences such as automatic syncing, no history stored on the client side so the data is not stored twice, resumable transfers, more user-friendly file conflicts and more.
Seafile 2.1 released with the main goal of this release to make it easier for new users to get started with Seafile.
#synchronisation #cloud #RPi #dropbox-alternative #email #vie_privée #open_source #mobile #serveur #do-it-yourself

@lliseil Le groupe n’a jamais vraiment été actif à part deux trois fichiers le premier jour, à ma connaissance...
De rien pour le test serveur, et un an après j’utilise toujours Seafile (j’ai même totalement remplacé Dropbox) et je maintiens mon avis initial : rapide, stable, pratique, nickel.
Et le développement est très actif, avec de nouvelles fonctionnalités très régulièrement (chiffrement côté client, partage de dossiers avec possibilité d’envoi de fichiers, nouvelle interface Web, etc.).
yami :-p
Merci de ce retour @Juba ! Ton serveur est local ou dans le cloud ?
#encryption
Mon serveur Seafile est sur un serveur dédié perso. « Dans le cloud » pourrait-on dire, mais un cloud sur lequel j’ai (à peu près) la main.
parmi les nouveaux sur ce créneau :
– #Syncthing ►http://syncthing.net
– #Hive2hive ▻http://hive2hive.com
Haha hive2hive = java = même leur page d’accueil censé être juste du HTML arrive à me faire planter. Trop fort ces devs java.
Bon en fait après avoir tourné longtemps, Firefox me dit que c’est un script twitter/widgets.js qui tourne dans le vide.

Le bouquin de référence sur la programmation fonctionnelle :
►http://mitpress.mit.edu/sicp/full-text/book/book.html
version epub : ►https://github.com/ieure/sicp
Solutions des exos en différents langages (Scheme, Clojure, Ruby and JavaScript) : ►https://github.com/pjb3/sicp (il semble en exister d’autres ailleurs)
#programming #développement #LISP #programmation_fonctionnelle #lambda_calcul
Bof, ce livre ne parle même pas de #Haskell.
Le langage ou l’homme ? L’homme y est cité (dans la préface, du moins). Le langage, n’existait pas à l’époque de l’écriture du bouquin (1980). J’ai surement mal intitulé mon « seen », ce bouquin est surtout un #classique_de_l'informatique (et donc peut être une référence aussi).
Je l’ai commencé, et son approche, pour l’instant, convient bien au demi (voir quart) de dev que je suis, qui souhaite se muscler un peu. :)
►http://en.wikipedia.org/wiki/Structure_and_Interpretation_of_Computer_Programs

La gestion du plein-écran sur Flip-Zone. (Je commence la description des détails techniques de la refonte de Flip-Zone.)
Le mode « plein-écran » est visible dans les animations de présentation des collections (anciennement : les « flipbooks »). Il y a un bouton dans le coin de l’animation. Par exemple là :
►http://www.flip-zone.com/fashion/swimwear/janine-robin
L’idée, c’est que dans la version précédente, cette grande animation était entièrement en Flash. Donc j’y gérais le plein écran via Flash. En abandonnant le Flash, je ne voulais pas perdre le plein écran (qui constituait un des aspects spectaculaires de Flip-Zone, que les « autres » magazines de mode ne présentent pas de façon aussi chouette).
Donc : j’utilise l’API #Fullscreen du #HTML5. Curieusement utilisée rigoureusement nulle part, cette API est pourtant épatante et largement utilisable.
– Il faut commencer par utiliser un petit framework qui fasse fonctionner l’API sur Firefox, Safari, Chrome avec leurs implémentations non standard. Pour ça, j’utilise :
►https://github.com/kayahr/jquery-fullscreen-plugin
– J’ai cependant patché ce petit script, parce que désormais Opera aussi a implémenté l’API, mais cette fois en respectant la recommandation officielle. (Je l’ai déjà signalé : il n’existe aucun framework qui ait implémenté la recommandation officielle, si bien que le seul navigateur qui l’ai implémenté est le seul sur lequel aucune des démos ne fonctionne !)
►http://www.flip-zone.com/squelettes/javascript/jquery.fullscreen-mod.js
– Mais je ne passe non plus directement par les fonctions de gestion du plein écran, parce que je veux aussi gérer le cas où l’API n’est pas implémentée (et il y a du monde). Dans ce cas, j’ajoute une classe au conteneur que je veux passer en plein écran, classe qui dit que tout cela est en position fixed, width à 100% et height à 100%. Façon lightbox, en gros.
– Du coup, le mode « plein écran » est relativement transparent (sauf quand les brouteurs, comme Firefox, ont implémenté ça de manière paranoïaque en te demandant de valider 2000 fois un gros bouton autorisant à passer en plein écran…). Même sur MSIE 8 (par exemple), on gagne à passer en « plein écran ».
Pour des raisons économiques évidentes, malheureusement, je conserve le bandeau de publicité à droite en mode plein écran. Sans le bandeau, c’est carrément spectaculaire (si vous avez adblock ou similaire, vous pourrez profiter de l’intégralité de l’écran).
À noter : le mode « plein écran », même non implémenté avec l’API, est très agréable pour utiliser confortablement Flip-Zone sur un smartphone.
– Pour ceux qui n’ont pas suivi : ça n’est pas du tout la même chose que de passer volontairement la fenêtre du navigateur en plein écran. Dans le mode que j’utilise ici, seule l’animation de présentation des collections passe en plein écran, à la façon d’une animation Flash.
Donc : j’utilise l’API #Fullscreen du #HTML5. Curieusement utilisée rigoureusement nulle part...
Mais si elle est utilisée cette API, le plugin #GIS pour #SPIP la propose pour ses cartes depuis 8 mois :p

Mais si elle est utilisée cette API, le plugin #GIS pour #SPIP la propose pour ses cartes depuis 8 mois :p
ah monsieur @b_b veut se la jouer à coup de dates ???
Sur le lecteur de mediaspip (démo par là : ▻http://player.mediaspip.net/demos/videos/article/exemple-complet) c’est deux jours avant cf : ▻http://svn.aires-de-confluxence.info/changeset/6600/plugins_spip/html5/trunk/javascript/mediaspip_player.js
#mega_shameless_autopromo_tambien #b_b_est_un_copieur #bouhouhou_le_vilain ;) #mais_je_n_etais_surement_pas_le_premier_puisque_j_ai_pompe_le_code_quelque_part (ce dernier hashtag montre la puissance de seenthis... sur twitter il prendrait la moitié de l’espace possible)
Allez, allez ! Les enfants, on se range deux par deux, la récré est #finite ! :D

Le manifeste du réparateur
►https://github.com/hugokernel/manifesto/blob/master/fr/manifesto.md
5. Résistez à la mode et aux mises à jours superflues. Elles alimentent la culture du jetable.
Via ►http://standblog.org/blog/post/2012/12/07/En-vrac-du-vendredi
Existe aussi en PDF : ►https://github.com/hugokernel/manifesto/blob/master/fr/le_manifeste_du_reparateur.pdf?raw=true

Tiens, mon système Android prend de plus en plus de place sur ma mémoire interne. J’ai pratiquement jeté toutes les applications que j’avais ajouté, mais j’ai de moins en moins de place. J’ai utilisé des nettoyeurs, mais la place diminue et je suis à la limite de la saturation de la mémoire interne. Une idée ?

Upcoming 3.0 changes · twitter/bootstrap
►https://github.com/twitter/bootstrap/wiki/Upcoming-3.0-changes
While our last major version bump (2.0) was a complete rewrite of the docs, CSS, and JavaScript, the move to 3.0 is not quite as ambitious. This is an ongoing document to identify the changes we’ll be making along the way.
Source: GitHub
Envoyer un message vers le #syslog local en #PHP : ►http://php.net/manual/fr/function.syslog.php
et ça :
Pure PHP syslog client
Log data to a RFC 3164 compliant syslog server :
►http://www.phpclasses.org/browse/file/12157.html
L’implémentation de la fonction PHP native dans symfony :
►http://trac.symfony-project.org/browser/trunk/lib/log/sfLog/syslog.class.php?rev=1415
PHP #PEG - A PEG compiler for #parsing text in #PHP
►https://github.com/maetl/php-peg
This is a Parsing Expression Grammar compiler for PHP. PEG parsers are an alternative to other CFG grammars that includes both tokenization and lexing in a single top down grammar. For a basic overview of the subject, see ►http://en.wikipedia.org/wiki/Parsing_expression_grammar
comme je suis curieux je me suis dit que j’allais essayer de regarder ce qu’il existe comme compilateurs de parser/phraseur/lexer aboutissant à un code PHP — j’ai trouvé celui-là, qui est très simple à installer et à utiliser, mais aussi deux autres, avec lesquels j’ai eu moins de chance :
►https://github.com/jgm/peg-markdown
et
►https://github.com/wez/lemon-php
Avec php-peg je suis parvenu à faire une espèce de parser capable (plus ou moins) de traiter les textes de seenthis. C’est encourageant. Est-ce éventuellement utile ? Un intérêt pourrait être d’être capable d’assembler les textes seenthis ailleurs que dans PHP, mais pourquoi pas en javascript ou en python (ou en C si ça vous chante).
Excellente charge contre les incroyables complexités de #git, dont l’auteur note à juste titre qu’il est conçu pour un tout petit nombre d’utilisateurs (ceux qui maintiennent le noyau Linux) et que les besoins de 99 % des programmeurs sont ignorés.
►https://steveko.wordpress.com/2012/02/24/10-things-i-hate-about-git
Je trouve que c’est un poil exagéré, mais pour les parties qui sont effectivement problématiques, ça fait un bout de temps que je me dis qu’il serait intéressant de conserver le plumbing de git mais de créer une nouvelle couche de porcelaine par-dessus qui soit plus simple à utiliser pour certains cas courants.

A l’origine, Git était censé être utilisé via Cogito - une IHM un peu mieux adaptée à l’H que git brut de décoffrage : ►http://git.or.cz/cogito - mais bizarrement ses développeurs ont fini par conclure que « Git user interface should be sufficiently user friendly »... Je suis dubitatif - la flexibilité combinée à la performance a un coût et le compromis que propose Git est clairement optimisé pour une niche bien étroite.
Ce qu’on a besoin de savoir pour travailler sur un projet sous SVN :
Ce qu’on a besoin de savoir pour un projet sur #Github :
Ça me paraît assez flagrant.
Un des points que j’ai trouvé important, c’est que normalement seul les mainteneurs ont besoin de connaître plus de commandes et faire des choses plus compliqués que le autres. Là dans Git, ça complexifie les choses à savoir pour tous, pour que les mainteneurs aient un peu moins de boulot. Ça facilite les merge pour les admins, mais ça ne facilite pas l’arrivée de contributeurs.
Pour moi qui ne suis pas férue des arcanes de ces machins en utilisant la surcouche d’un logiciel comme Github, Git devient assez agréable à utiliser. Ne serait-ce que pour basculer d’une branche à l’autre sans avoir à faire un checkout de tout un dossier. Evidemment le changement intervient au niveau de l’interface, n’empêche… j’avoue que j’ai abandonné la formation Git proposé à Capitole du libre car essentiellement pour des ingénieurs déjà initiés, dommage, pourtant motivée j’ai trouvée ça trop complexe et je me suis sentie très con, jamais agréable.

@rastapopoulos Très bien, les deux dessins mais il est dommage que le deuxième confonde Git et Github...
Non non, je ne pense pas que l’auteur confonde, mais il part du principe, dès le début de l’article, qu’une grande partie des projets libres actuels sont sur Github. Donc pour y participer il faut connaître Git et Github, du coup. D’où le fait qu’il l’intègre dans ses explications.
Il rajoute une explication à la fin :
The comparison between a Subversion repository with commit access and a Git repository without it isn’t fair True. But that’s been my experience: most SVN repositories I’ve seen have many committers – it works better that way. Git (or at least Github) repositories tend not to: you’re expected to submit pull requests, even after you reach the “trusted” stage.
C’est aussi mon expérience, comme quand on compare SPIP-Zone où tout le monde peut commiter, et les quelques projets SPIP qui sont sur Github où on peut seulement faire des pull request. Du coup finalement cette manière de travailler hiérarchise plus malgré la soi-disant décentralisation.
Comme le dit l’article, ce n’est pas l’architecture en elle-même qui fait ça, mais plutôt comment les gens l’utilisent en ce moment ainsi que les interfaces disponibles actuellement pour l’utiliser de manière humaine.

J’ai bien compris l’évolution vers « plus de collaboration » quand on est passé de SCCS/RCS à CVS puis SVN, mais GIT ne pousse pas franchement au travail collaboratif, pour les raisons données ci-dessus par @rastapopoulos. Doit-on appeler ça une régression ? A-t-on déjà observé de telles régressions (des usages) dans l’évolution du logiciel libre ?
@RastaPopoulos : j’ai déjà vu ce phénomène (un dépôt git officiel où un seul a le droit d’écrire, les autres ne pouvant faire que des pull requests) mais attention, git et GitHub n’imposent pas ce modèle. Sur GitHub, on peut parfaitement avoir un dépôt où plusieurs personnes peuvent écrire (c’est ce qu’on fait au boulot, cf. ►https://github.com/AFNIC/DNSwitness)
Ben oui, c’est que je dis depuis le début (et ce que dit l’article), c’est pas l’architecture qui impose ça forcément. Mais c’est un usage très fréquent (de plus en plus ? à chiffrer...) dans les projets libres actuellement.
Après on peut extrapoler... :) : il y a peut-être aussi une métaphysique du chacun chez soi avec cette facilité à avoir chacun son petit dépôt. Quand on a un dépôt commun : il faut apprendre à donner des droits d’écriture à plus de monde, et il faut apprendre à travailler en commun, à faire attention au code des autres. Bien sûr que ça limite techniquement, mais peut-être que socialement ça implique plus de chose. Alors que quand on fork tous chacun dans son coin, chacun est un innovateur dans son coin, chacun se vend sur le marché du code source libre, et on intègre les talents : c’est du développement libéral individualiste (ce qui, somme toute, correspond à la philosophie de Linus Torvalds, d’ailleurs).
Bon, là c’est une réflexion pas du tout technique et je pense tout haut en voyant ce que ça donne hein... :)
Mais c’est pas forcément si con.
sithmel/graphTable · GitHub
►https://github.com/sithmel/graphTable
Un sous-plugin de #jQuery #Flot qui fabrique un graphique à partir d’une table #HTML, donc plus accessible à priori. Et plus facile à construire puisqu’on a pas besoin de connaître le JS pour le faire.
À faire : un plugin #SPIP pour l’intégrer encore plus facilement à partir de classes #CSS ajoutées aux tables : « graphtable columns » ou « graphtable rows », entre autre. Du coup il n’y aurait même plus besoin de l’appel non plus. Juste activer le plugin et mettre des classes sur certains tableaux.
straup/Clustr
►https://github.com/straup/Clustr#readme
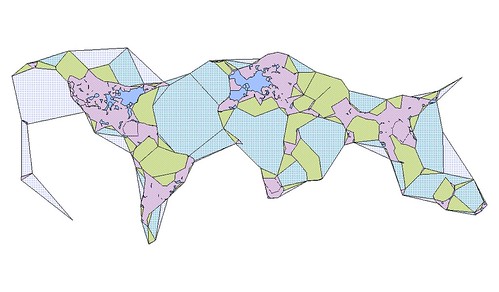
Clustr takes a text file containing longitude/latitude points, tagged with a bit of text, and attempts to generate minimal polygons that “cover” those points, using an “alpha” parameter to determine the notion of “coverage”. The polygons are written to an ESRI Shapefile, suitable for use in GIS software.
T’as un exemple visuel quelque part ? Je pense avoir compris le principe mais pas trop. :)
(#gis, pas qgis)
►https://github.com/fnagel/jQuery-Accessible-RIA
a collection of strictly WAI WCAG 2.0 and WAI ARIA conform web applications based on jQuery (using the UI Widget Factory). Currently a lightbox app, live form-validation, accessible tabs and sortable tables are ready to use. Released under MIT licence.
mbostock/d3
►https://github.com/mbostock/d3/wiki
D3.js is a JavaScript library for manipulating documents based on data. D3 helps you bring data to life using HTML, SVG and CSS. D3’s emphasis on web standards gives you the full capabilities of modern browsers without tying yourself to a proprietary framework, combining powerful visualization components and a data-driven approach to DOM manipulation.
mikeal/filed
►https://github.com/mikeal/filed
Those familiar with request will be familiar seeing object capability detection when doing HTTP. filed does this as well.
http.createServer(function (req, resp) {
filed(’/data.json’).pipe(resp)
})
Not only does the JSON file get streamed to the HTTP Response it will include an Etag, Last-Modified, Content-Length, and a Content-Type header based on the filed extension.