Deep Visual-Semantic Alignments for Generating Image Descriptions
Stanford University researchers are using/training improved neural networks to generate descriptions of images. Recognition of objects is nothing new, but those algorithms struggle with descriptions of scenes, and that’s precisely where progress has been made here.
Abstract
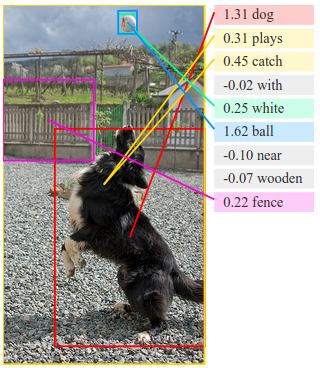
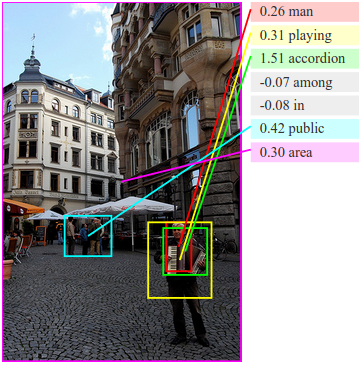
We present a model that generates free-form natural language descriptions of image regions*. Our model leverages datasets of images and their sentence descriptions to learn about the inter-modal correspondences between text and visual data. Our approach is based on a novel combination of Convolutional Neural Networks over image regions, bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding. We then describe a Recurrent Neural Network architecture that uses the inferred alignments to learn to generate novel descriptions of image regions. We demonstrate the effectiveness of our alignment model with ranking experiments on Flickr8K, Flickr30K and COCO datasets, where we substantially improve on the state of the art. We then show that the sentences created by our generative model outperform retrieval baselines on the three aforementioned datasets and a new dataset of region-level annotations.