Prolonged grief disorder symptoms afflict many who lost loved ones from COVID-19
▻https://www.reuters.com/graphics/HEALTH-CORONAVIRUS/USA-CASUALTIES/lbpggbmrapq
Prolonged grief disorder symptoms afflict many who lost loved ones from COVID-19
▻https://www.reuters.com/graphics/HEALTH-CORONAVIRUS/USA-CASUALTIES/lbpggbmrapq

Je découvre cette collection de « Reuters Graphics », mélange de #longforms et des #data-visualisation :
▻https://www.reuters.com/graphics

En toutes choses, il faut de la mesure : de l’usage de la télémétrie
▻https://www.laquadrature.net/2021/09/24/en-toutes-choses-il-faut-de-la-mesure-de-lusage-de-la-telemetrie
Dans un récent épisode du feuilleton « l’application TousAntiCovid, le pistage et nous », trois informaticiens ont publié le 19 août 2021 une analyse de risque du système de collecte de statistiques de l’application TousAntiCovid. Ils y…
When more Covid-19 data doesn’t equal more understanding | MIT News | Massachusetts Institute of Technology
▻https://news.mit.edu/2021/when-more-covid-data-doesnt-equal-more-understanding-0304
“An initial hypothesis was that if we had more data visualizations, from data collected in a systematic way, then people would be better informed,” says Lee. (...) The researchers found that antimask groups were creating and sharing data visualizations as much as, if not more than, other groups.
And those visualizations weren’t sloppy. “They are virtually indistinguishable from those shared by mainstream sources,” says Satyanarayan. “They are often just as polished as graphs you would expect to encounter in data journalism or public health dashboards.”
“It’s a very striking finding,” says Lee. “It shows that characterizing antimask groups as data-illiterate or not engaging with the data, is empirically false.”

La pieuvre Microsoft et nos données de santé
▻https://lundi.am/pieuvre-microsoft
Sous couvert de lutte contre l’épidémie et d’état d’urgence sanitaire, le gouvernement a donné le coup d’envoi à son projet de méga plateforme de données de santé hébergée chez Microsoft. Petite plongée dans l’intelligence artificielle en médecine avec le collectif inter-hop qui depuis le début du projet milite contre cette plateforme géante et pour une utilisation autonome des données de santé à échelle humaine. Source : Lundi matin

Mais, surtout, pourquoi vouloir absolument réunir toutes les données de santé de plus de 65 millions de personnes chez un même fournisseur de service ?
et
Les ordinateurs, c’est une évidence, peuvent nous aider à faire beaucoup de choses, mais, avec des structures politiques aussi pyramidales que les nôtres, il faut s’en méfier et lutter contre les usages qui alimentent les velléités de toute puissance et de contrôle.
voir aussi le site du collectif inter-hop : ▻https://interhop.org et le courrier adressé au ministère de la santé pour un appel d’offre pour le choix de l’hébergeur des données de santé : ▻https://interhop.org/2020/07/26/communique-presse-ministre-sante-appel-offre
#BigData #Microsoft #inter-hop #sante #data-center #CNIL #Plateforme #état_d’urgence_sanitaire #Système_National_des_Données_de_Santé #SNDS
Pan-European Privacy-Preserving Proximity Tracing | Pepp-Pt
▻https://www.pepp-pt.org
PEPP-PT makes it possible to interrupt new chains of SARS-CoV-2 transmission rapidly and effectively by informing potentially exposed people. We are a large and inclusive European team. We provide standards, technology, and services to countries and developers. We embrace a fully privacy-preserving approach. We build on well-tested, fully implemented proximity measurement and scalable backend service. We enable tracing of infection chains across national borders.
Proximity Tracing YES, Giving Up Privacy NO!
#surveillance voir aussi ▻https://seenthis.net/messages/836812
Une autre initiative de ce genre, lancée par l’équipe de Trevor Bradford (qui fait aussi nextstrain)
▻https://nexttrace.org/about
comment fonctionne PEPP-PT (thread)
▻https://twitter.com/marcelsalathe/status/1246352102059847680
“an alternative to locking everyone up for 18 months or letting millions die”
Le fonctionnement technique de la 3ème appli (basée sur des échanges bluetooth entre les téléphones ...mais qui nécessite quand même un serveur centralisé) :
Le twitt de présentation du système : (de Carmela Troncoso)
As countries deploy data-hungry contact tracing, we worry about what will happen with this data. Together with colleagues from 7 institutions, we designed a system that hides all personal information from the server. Please read and give comments!
=> La présentation complète : ▻https://github.com/DP-3T/documents/blob/master/DP3T%20-%20Data%20Protection%20and%20Security.pdf
=> le fil Twitter en mode « questions/réponses » : ►https://twitter.com/mikarv/status/1246124667355660291
#bluetooth #data-paranoia #vie_privée #centralisation_des_données
Gouvernance numérique et santé publique. Vers un confinement sélectif basé sur les informations personnelles ?, par Stéphane Grumbach et Pablo Jensen
▻https://www.lemonde.fr/blog/binaire/2020/04/09/gouvernance-numerique-et-sante-publique-vers-un-confinement-selectif-base-su
Ce qui me chagrine, c’est que l’article du Monde, ainsi que l’article de Science,
▻https://science.sciencemag.org/content/early/2020/03/30/science.abb6936
n’approfondissent les difficultés que je notais ici :
►https://seenthis.net/messages/839937
Je trouve qu’on reste vraiment à la surface des choses, et je trouve ça dangereux. Parce que soit on se retrouve à avoir une opposition frontale de nos propres amis (pas de traçage du tout c’est du fascisme), soit ces articles qui disent qu’on peut le faire façon RGPD mais en évitant les questions qui fâchent, soit tout simplement des grandes entreprises déjà spécialistes du flicage généralisé, avec leurs solutions clé en main. Et en face, des politiques à qui l’on impose de « sauver des vie », et qui ont donc comme interlocteurs soit des gauchistes qui ne veulent rien entendre (même avec de bons arguments, ça ne l’aide pas le politique, dans cette situation), soit des partisans RGPD qui ne répondent pas aux questions pratiques, soit des entreprises milliardaires avec des solutions de flicage out of the box (qui sont déjà largement utilisées par ailleurs…) qui promettent qu’avec ça, on va sauver les gens, et que l’action volontariste de l’État (avec les types en blanc qui débarquent encadrés par l’armée dans une barre d’immeuble de banlieue pour traquer l’infecté qui se cache parmi nous…) sera pour le coup parfaitement visible.
Je veux dire : le choix me semble vite fait.

vous êtes terrifiants, prêts à tourner casaques et à vous faire embobiner par les VRP de la surveillance, plutot rouge, jaune ou bleu le baton technologique ? C’est un gag ?
Le débat est détourné, car ce n’est ni une question technologique de surveillance ou une question éthique des moyens de flicages à mettre en place dont il faut débattre.
Avant toute chose, débattons des moyens techniques réels qui sont donnés pour se protéger d’une pandémie.
Vous pensez vraiment qu’un traçage blutooth va servir, poussons donc le bouchon en terme technique, comment cela va-t-il fonctionner même si nous acceptons d’insérer sous notre peau un mouchard qui nous géolocalise et prend notre température et l’envoi à un serveur centralisé ?
On va détecter quoi et comment va-t-on traiter ces données ? la distance ? la charge virale ? les moments où on a retiré son masque ? le moment où l’on est contagieux mais sans symptômes ? On va prévenir ceux qui ont été au moins une demie heure en contact avec nous 15 jours avant ? Tu prends le métro tout les jours 1h00, tu as croisé 12000 voyageurs.
STP pense juste à porter un masque et à faire des tests réguliers, on reparlera ensuite de la façon dont le débat a été détourné par les politiques et les industriels de la surveillance.


Comme @laquadrature @touti tu extrapoles à des implants big brother, des obligations d’installer des apps qui te géolocalisent en permanence, l’État qui te traque partout et à toute heure.
L’extrapolation est crédible dès lors que c’est ce que l’État aime faire avec l’informatisation, et le complexe militaro-industriel-surveillance est prêt à opérer… mais c’est ça que ces projets tentent de contrer, en montrant qu’il peut exister des méthodes « propres ».
Si on lit ce projet précis, il s’agit, si tu as choisi d’activer une app de ce genre, de pouvoir faire remonter une information concernant le résultat d’un test aux personnes qui pourraient avoir été en contact avec toi.
Par conséquent ça ne s’oppose en rien aux tests, bien au contraire. Ca veut dire que le test que tu as fait va pouvoir (peut-être) être aussi utile à (quelques) autres.
Perso j’apprécierais assez qu’une personne que j’ai croisée et qui a fait un test puisse me prévenir, comme ça je peux me mettre à l’isolement et éviter de contaminer mes proches, faire un test s’il y en a, etc. ; et je me sentirais mal dans le cas où je serais dépisté et je ne pourrais prévenir personne des gens que j’ai pu contaminer la veille.
L’exemple du métro est intéressant, car en effet si chaque fois qu’on prend le métro on risque d’infecter 12 000 personnes, il faut peut-être fermer le métro. Ça n’a pas grand chose à voir avec le sujet, à part si ce que tu veux dire c’est que l’explosion combinatoire est de toute façon impossible à freiner.
le débat a été détourné par les politiques et les industriels de la surveillance
On est sur les mêmes débats que sur le logiciel libre. Je suis pessimiste sur l’issue, mais, je me répépète, il s’agit là de chercheurs de la recherche publique européenne, qui tentent de répondre à ces deux impératifs (santé, vie privée). Si on les flingue sans autre forme de procès, il ne restera en effet que les industriels de la surveillance (plus de la moitié des papiers signalés sous le tag #virusphone).
Sans forcément conclure ni choisir ma casaque, je trouve que ça mérite l’intérêt plutôt qu’un rejet épidermique.
Comme @laquadrature @touti tu extrapoles à des implants big brother, des obligations d’installer des apps qui te géolocalisent en permanence, l’État qui te traque partout et à toute heure.
Ça commence mal avec cette caricature qui me catalogue, et j’ai dut mal m’exprimer car je donne cet exemple non pas par parano mais pour comprendre que même au maximum de la surveillance, ça ne résout pas la question première qui est une question du comment fera-t-on techniquement pour détecter avec qui tu as été en contact.
Pour le moment je ne parle même pas du problème éthique.
Ça n’a rien d’un rejet épidermique, le leurre technophile masque l’incurie des politiques et le fait que justement techniquement ça risque fort de ne rien endiguer, cf :
▻https://www.aclu.org/report/aclu-white-paper-limits-location-tracking-epidemic?redirect=aclu-white-paper-l

Je crois que ce qui me pose problème c’est qu’on a l’expérience de ce que le rejet de malades ou présumés malades peut générer (pestiférés, malades du sida/séropositifs voir HHH, lépreux etc.), indépendamment de la rationalité des critères de contamination/protection. Généraliser la communication de son statut sérologique de cette manière me gêne notamment si il faut en plus croiser à terme les critères complémentaires qui semblent être associés au covid-19 (groupe sanguin, facteurs de risque etc. Je ne suis pas luddite, mais je ne fais pas particulièrement confiance à ce type de pratiques nominatives et de croisement en terme de santé (je dis bien nominatives car adresses bluetooth et autres mac-adress uniques permettent d’identifier les personnes).

Merci à tou·tes pour ce débat. J’ai tendance à trouver que sur le terreau d’ignorance où prolifère ce virus (ignorance des comportements pour limiter sa propagation, ignorance de notre état de santé et de notre capacité à le propager), la connaissance de nos mouvements et possibilités de propagation, c’est un peu la charrue mise devant les bœufs, qu’il y a encore beaucoup de mesures low-tech à mettre en œuvre avant, dont nous pourrions nous priver, aveuglé·es par l’efficacité d’une solution high-tech (et puis les masques et le gel, c’est cher). Je ne sais pas si l’existence de dispositifs moins intrusifs et moins dangereux pour les libertés peut empêcher des gouvernants gourmands de #stratégie_du_choc pour nous écraser la gueule de choisir de nous surveiller de manière plus éthique.

@antonin, plutôt qu’ignorance (qui peut faire penser que d’autres savent alors que le flou règne) je dirais inconnues , comme dans les formules d’algo prédictifs avec des inconnues médicales parfois réellement ignorées et beaucoup trop nombreuses à être décisives dans le cas de la pandémie actuelle. Etonnée que je suis de voir certaines vidéos en démonstrations de formules magiques mathématiques pour te persuader des bienfaits du traçage, ce qui ressemble à un vaste écran de fumée pour accéder rapidement au miracle technologique à venir, censé nous sauver du personnel soignants manquants, des lits d’hopitaux inexistants, des médicaments l’année prochaine, de la douleur sans curare, des masques, tests, aides à la recherche qui manquent toujours pour endiguer la pandémie et nous laisser sortir. Donc oui, le recours au low-tech et peut-être à une vision plus humaine dédiée aux soins et à la lutte pour plus d’égalités, et non qui risque de nous diviser (délinquants sans logiciel anticovid).
Autre terme qui me gêne, voire me faire rire jaune, c’est la surveillance éthique , et là du coup c’est vraiment une question non plus d’efficience mais de choix de société, du basculement collectif, qui touche la limite de la démocratie et le politique (qu’est-ce qu’on fait ensemble ?). Raa le St Graal de l’éthique (à coller comme un sucre quand on veut faire avaler le terme qui le précède), de l’anonymisation, de la bénédiction de la CNIL, tout cela sent le grand bain des croyances au secours de nos angoisses.
Collecte de données et déclin de la vie privée [Wiki informatique de Médéric]
▻https://wiki.ordi49.fr/doku.php/savoir:collecte_de_donnees_et_declin_de_la_vie_privee
Cette page est une veille technologique pour sensibiliser au phénomène de collecte massive de données personnelles (data mining) et au déclin de la vie privée lié à un certain usage des technologies de l’information et de la communication
Ressources commentées et organisées par thèmes (en français, ~depuis 2012). Compilation très complète.
#vie_privée #collecte_des_données #compilation_web #data-mining

Autour de l’informatique : les algorithmes et la disparition du sujet
▻https://www.academia.edu/20749267/Big_data_l_enjeu_est_moins_la_donn%C3%A9e_personnelle_que_la_disparition_d
Antoinette Rouvroy, chercheure au Fond National de la Recherche Scientifique Belge, rattachée au Centre de Recherche Information, Droit et Société de l’Université (CRIDS ) de l’Université de Namur répond aux questions de Binaire sur les algorithmes et la gouvernementalité algorithmique. Elle nous conduit aux frontières du droit et de la philosophie. C’est une occasion exceptionnelle de nous interroger sur ces nouvelles dimensions de nos vies et du monde numérique. Antoinette Rouvroy, qui (...)
#Google #Amazon #Facebook #algorithme #contrôle #biométrie #justice #prédiction #reconnaissance #data-mining #BigData #comportement #data #GAFAM #marketing #profiling #surveillance #travailleurs #criminalité #discrimination (...)
##criminalité ##santé

« Evolving the Graph » by Coursera, Jon Wong, 28.08.2019
▻https://medium.com/coursera-engineering/evolving-the-graph-4c587a4ad9a8
#graphql #data-hub #schema-language #learnings #coursera
« An Overview of GraphQL » by Neo4j, William Lyon
Developer Relations Engineer
▻https://dzone.com/refcardz/an-overview-of-graphql
#graphql #schema-language #query-language #data-hub #overview #neo4j

#python is First Step to Data Science
▻https://hackernoon.com/python-is-first-step-to-data-science-705911ddf5a1?source=rss----3a8144ea
The steadily increasing importance of data science across industries has led to a rapid demand for data scientists. It’s been said that the role of data scientist is the 21st century’s sexiest job title. If you wonder why it has become such a sought after position these days, the short answer is that there has been a huge explosion in both data generated and captured by organizations and common people and data scientists are the people who derive valuable insights from that data and figure out what can be done with it.If you go through some job advertisements for data scientists, you’ll see that expertise in data science and Python are considered as two of the most crucial skills described.In this post, we’re going to discuss why these skills are considered must for data scientists.1- What (...)
12 Key Lessons from ML researchers and practitioners
▻https://hackernoon.com/12-key-lessons-from-ml-researchers-and-practitioners-3d4818a2feff?source
Machine learning algorithms come with the promise of being able to figure out how to perform important tasks by learning from data, i.e., generalizing from examples without being explicitly told what to do. This means that the higher the amount of data, the more ambtious problems can be tackled by these algorithms. However, developing successful machine learning applications requires quite some “black art” that is hard to find in text books or introductory courses on machine learning.I recently stumbled upon a great research paper by Professor Pedro Domingos that puts together lessons learned by machine learning researchers and practitioners. In this post, I am going to walkthrough those lessons with you.Get ready to learn about: pitfalls to avoid, important issues to focus on, and (...)
#machine-learning #development #best-practices #artificial-intelligence #data-science
Our 25 Favorite Data Science Courses From Harvard To Udemy
▻https://hackernoon.com/our-25-favorite-data-science-courses-from-harvard-to-udemy-9a89cac0358d?
Originally Posted HereLearning every facet of data science takes time. We have written pieces on different resources before. But we really wanted to focus on courses, or video like courses on youtube.There are so many options, it can be nice to have a list of classes worth taking.We are going to start with the free data science options so you can decide whether or not you want to start investing more in courses.Tip : Coursera can make it seem like the only option is to purchase the course. But they do have an audit button on the very bottom. Now, if you appreciate Coursera, by all means, you should purchase their specialization, I am still uncertain how I feel about it. But, I do love taking Coursera courses.Select the audit course option to not pay for the courseBootcamps and (...)
How to prevent embarrassment in AI
▻https://hackernoon.com/how-to-prevent-embarrassment-in-ai-5e64f437b9bb?source=rss----3a8144eabf
The must-have safety net that’ll save your baconHow will you prevent embarrassment in machine learning? The answer is… partially.Expect the unexpected!Wise product managers and designers might save your skin by seeing some issues coming a mile off and helping you cook a preventative fix into your production code. Unfortunately, AI systems are complex and your team usually won’t think of everything.There will be nasty surprises that force you into reactive mode.Real life is like that too. I’m meticulous when planning my vacations, but I didn’t consider the possibility that I’d miss my train to Rome thanks to a hospital tour sponsored by shellfish poisoning. True story. It taught college-age me never to repeat the words “I’ve thought of everything.”Speaking of things nobody expects…When the (...)
#data-science #artificial-intelligence #hackernoon-top-story #machine-learning #technology
Forecasting Future Customer Inflow Numbers using #arima and FBProphet
▻https://hackernoon.com/forecasting-future-customer-inflow-numbers-using-arima-and-fbprophet-2f7
Peaking into the futureSometimes it is important for a venture to peak into the future to understand how much volume foot traffic or how many units of products they can expect to sell. This could help better prepare for the future by scaling up sales and customer services team to adequately prepare for likely sales over the course of the next few years/months and ensuring there are demand side resources to handle projected growth.▻https://medium.com/media/ef398bdfacdcbc10075fcee3b0ac728d/hrefLike our trusted guide, Mr. Knuckles, in the above GIF, we can use historical data points to help us understand not just the present, but the future- helping guide us into the unknown. When we try and make such projections based only on time and values this is known as a time series analysis. We (...)
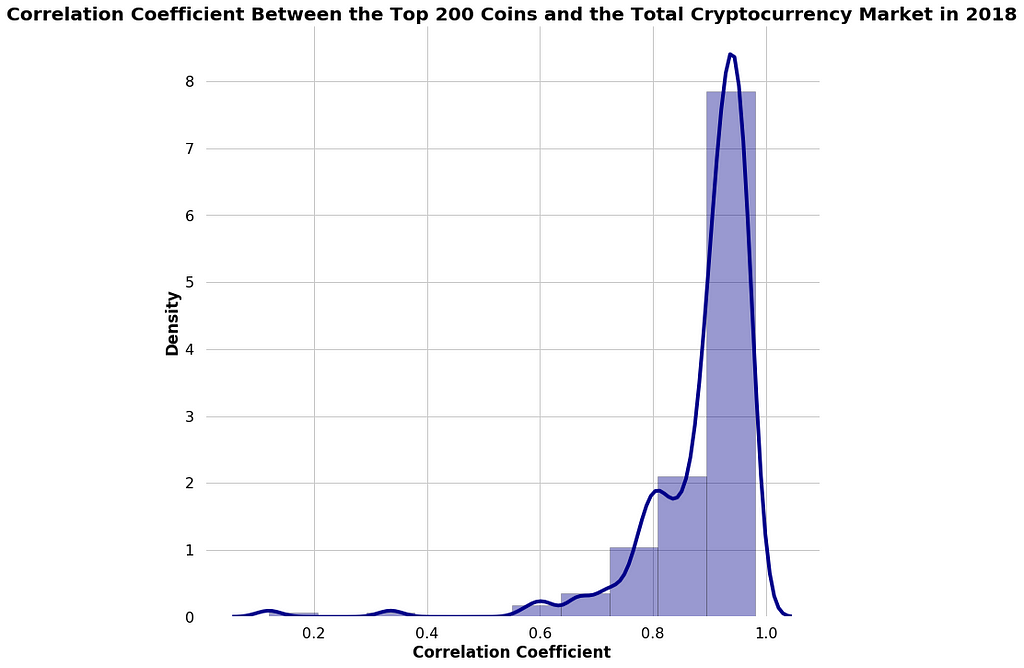
Correlations Between Top Coins and the #cryptocurrency Market Dropped in 2019
▻https://hackernoon.com/correlations-between-top-coins-and-the-cryptocurrency-market-dropped-in-
Last year, I published an article which discovered that 75% of the top 200 coins by market cap had a correlation of 0.67 or higher over the last two years.In 2018, correlations between cryptocurrencies and the total cryptocurrency market were especially high. 75% of the top 200 coins by market cap had a correlation of 0.87 or higher.High correlations are typically a really bad thing because it makes it harder for diversification to mitigate risk and implies that the market cannot differentiate between good & bad projects.2018 was bear market and it makes sense that correlations were high since the prices of all cryptocurrencies tumbled altogether.But since then, the market has changed. So far 2019 has primarily been a sideways market.The market has mostly been flat, with the (...)
10 Great Articles On Data Science And Data Engineering
▻https://hackernoon.com/10-great-articles-on-data-science-and-data-engineering-d5abdf4a4a44?sour
Data science and #programming are such rapidly expanding specialities it is hard to keep up with all the articles that come out from Google, Uber, Netflix and one off engineers. We have been reading several over the past few weeks and wanted to share some of our top blog posts for this week April 2019!We hope you enjoy these articles.Building and Scaling Data Lineage at NetflixBy: Di Lin, Girish Lingappa, Jitender AswaniImagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question — “Can I run a check myself to understand what data is behind this metric?”Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical (...)
Building a #serverless Data Pipeline with #aws S3 Lamba and DynamoDB
▻https://hackernoon.com/build-a-serverless-data-pipeline-with-aws-s3-lamba-and-dynamodb-5ecb8c3e
AWS Lambda plus Layers is one of the best solutions for managing a data pipeline and for implementing a serverless architecture. This post shows how to build a simple data pipeline using AWS Lambda Functions, S3 and DynamoDB.What this pipeline accomplishes?Every day an external datasource exports data to S3 and imports to AWS DynamoDB table.PrerequisitesServerless frameworkPython3.6PandasdockerHow this pipeline worksOn a daily basis, an external data source exports data of the pervious day in csv format to an S3 bucket. S3 event triggers an AWS Lambda Functions that do ETL process and save the data to DynamoDB.Install Serverless FrameworkBefore getting started, Install the Serverless Framework. Open up a terminal and type npm install -g serverless to install Serverless framework.Create (...)
#learning Data Science : Our Favorite Data Science #books
▻https://hackernoon.com/learning-data-science-our-favorite-data-science-books-d02ada5ed5d?source
Originally Posted HereWhether you are just breaking into data science, or you are looking to improve your data science skills. Books are one great method to get a base level understanding of specific topics. Now, we personally believe nothing beats experience, but in lieu of that, taking a course or reading a book is a great way possibilities that you can build on later when you are trying to practically approach data science.In data science, there are many topics to cover, so we wanted to focused on several specific topics. This post will cover books on #python, R programming, big data, SQL and just some generally good reads for data scientists.Heads Up! — This post contains referral links from Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a (...)
#learning Data Science : Our Favorite #python Resources
▻https://hackernoon.com/learning-data-science-our-favorite-python-resources-from-free-to-not-877
Python is a common language that is used by both data engineers and data scientists. This is because it can automate the operational work that data engineers need to do and has the algorithms, analytics, and data visualization libraries required by data scientist.In both rolls, the need to manage, automate and analyze data is made easier by only a few lines of code. So much so that one of the books we have read and seen in many data focused practitioners libraries in the book Automate The Boring Stuff With Python.The book covers python basics and some simple automation tips. This is especially good for business analysts who work heavily in Excel.There are also books by O’Reilly that are also a great overview of the basics.You can start your list of books with the Python Cookbook. This (...)
Predicting the likelihood of a customer to make repeat purchases using logistic regression
▻https://hackernoon.com/predicting-the-likelihood-of-a-customer-to-make-repeat-purchases-using-l
Source: FuraffinityFor a business getting a customer is exciting, not only because it helps you ‘secure the bag’ by bringing in much needed revenue, but it also creates an opportunity to create loyalty with this new found customer which in turn could help you ‘secure more bags’ through repeat purchases.Safe BagAssuming your business continues driving and optimising the action(s) that have the biggest positive impact on creating repeat purchases, you create more organic brand ambassadors who will refer friends to your business at no extra cost to you. Additionally, depending on the sizes of the purchases made by these repeat customers, this will increase average customer lifetime value. All things constant, the higher the average lifetime value the more wiggle room you have to spend on (...)
#machine-learning #hackernoon-top-story #exploratory-data-analysis #logistic-regression #data-visualization
How Hyper-Personalised #marketing Can Deliver Better Customer Experiences at Scale
▻https://hackernoon.com/how-hyper-personalised-marketing-can-deliver-better-customer-experiences
How Hyper-Personalized Marketing Can Deliver Better Customer Experiences at ScaleDecades ago, local grocery store owners had to remember the names of their regular customers, the preferences and lifestyles of their most loyal customers, leveraging all that information to provide a more welcoming and memorable service.Today, technology empowers businesses to seamlessly gather and capture customer data like names, birth dates, and purchase history which helps them to deliver personalized customer experiences at scale. In fact, it is now common for online retailers to send messages by addressing users by their first names and recommending products based on their historical buying behavior, gender, and precise geolocation data.Personalization in #mobile app marketing has been around for (...)
Why #ux Design Must Be the Foundation of Your Software Product
▻https://hackernoon.com/why-ux-design-must-be-the-foundation-of-your-software-product-f66e431cc7
“A user interface is like a joke. If you have to explain it, it’s not that good.” — Martin LeBlanc, IconfinderIt is an open secret that product design today is primarily about convenience and benefits for users. The best, most successful products embody flawless user experience.We at SumatoSoft strive to incorporate best practices in software we build for clients — and user experience design (UX) is one of them.So what is exactly user experience design?User experience design is the process of creating products that provide relevant and significant experiences to users based on their behaviour analysis. By analyzing the behavior of users, UX design identifies their motives and creates optimum digital experiences for them. The main objective of UX design is to improve the way users interact with (...)
#user-experience-design #data-driven #product-design #user-experience
Learning Data Science In 6 Weeks — How You Can Do It?
▻https://hackernoon.com/learning-data-science-in-6-weeks-how-you-can-do-it-d46520c12d43?source=r
Learning Data Science In 6 Weeks — How You Can Do It?With data science emerging as one of the hottest professions in the recent years, there’s an extremely high demand for data practitioners.However, many aspirants are bogged down by the myth that you need a Ph.D. or a Master’s in the field to become a data scientist.Those with very little statistics or programming skills too are often afraid of taking up courses in data science fearing they won’t find any use of what they learn.But in reality, if you have a passion for learning, can grapple with new challenges and persevere, you can learn data science in just 6 weeks data camp.And we don’t mean learning some basic things that won’t help you in getting a job.In 6 weeks, the right course can get you job-ready by teaching you the requisite skills (...)
#ai #entrepreneur #data-science #machine-learning #magnimind-academy