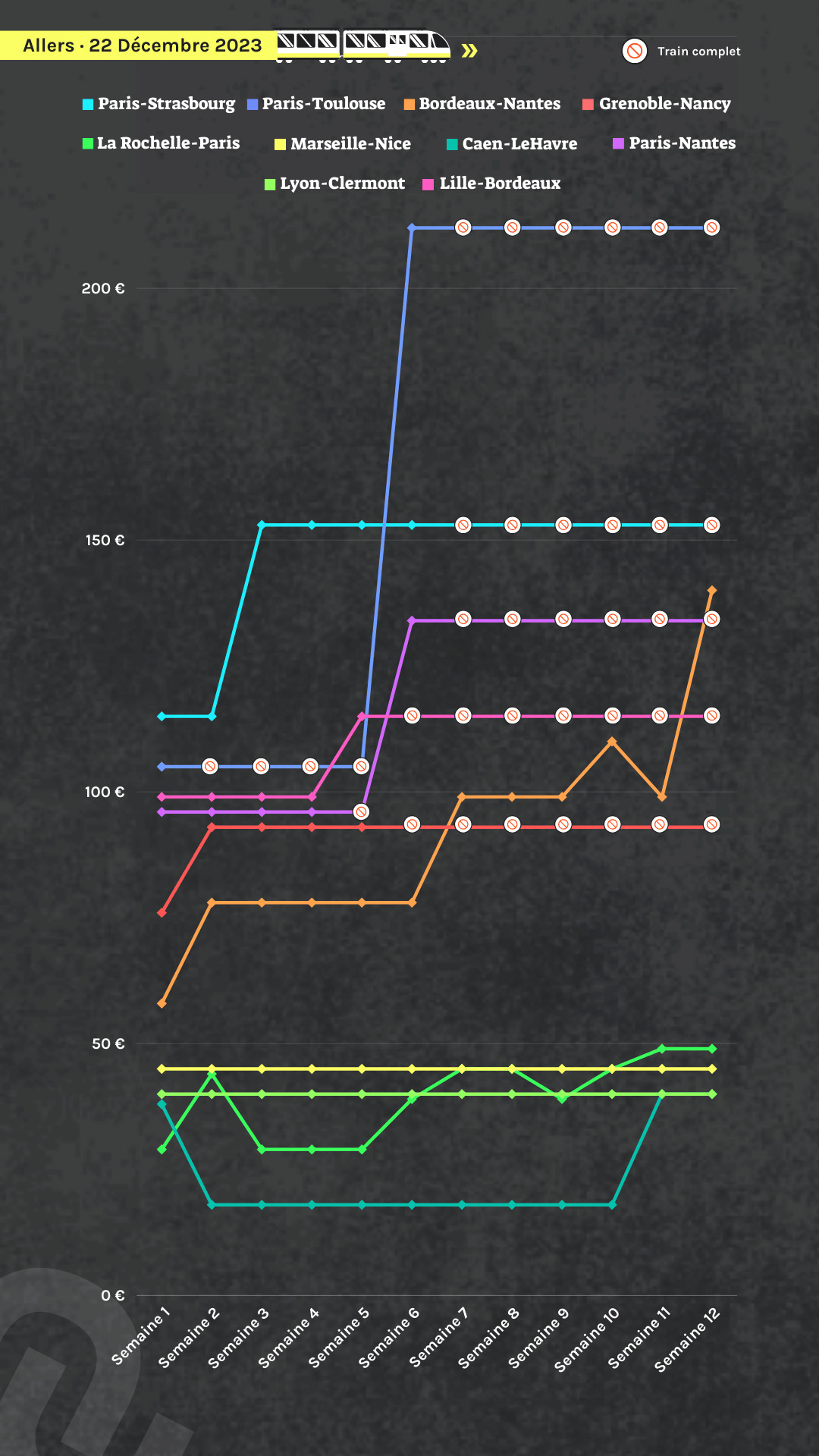
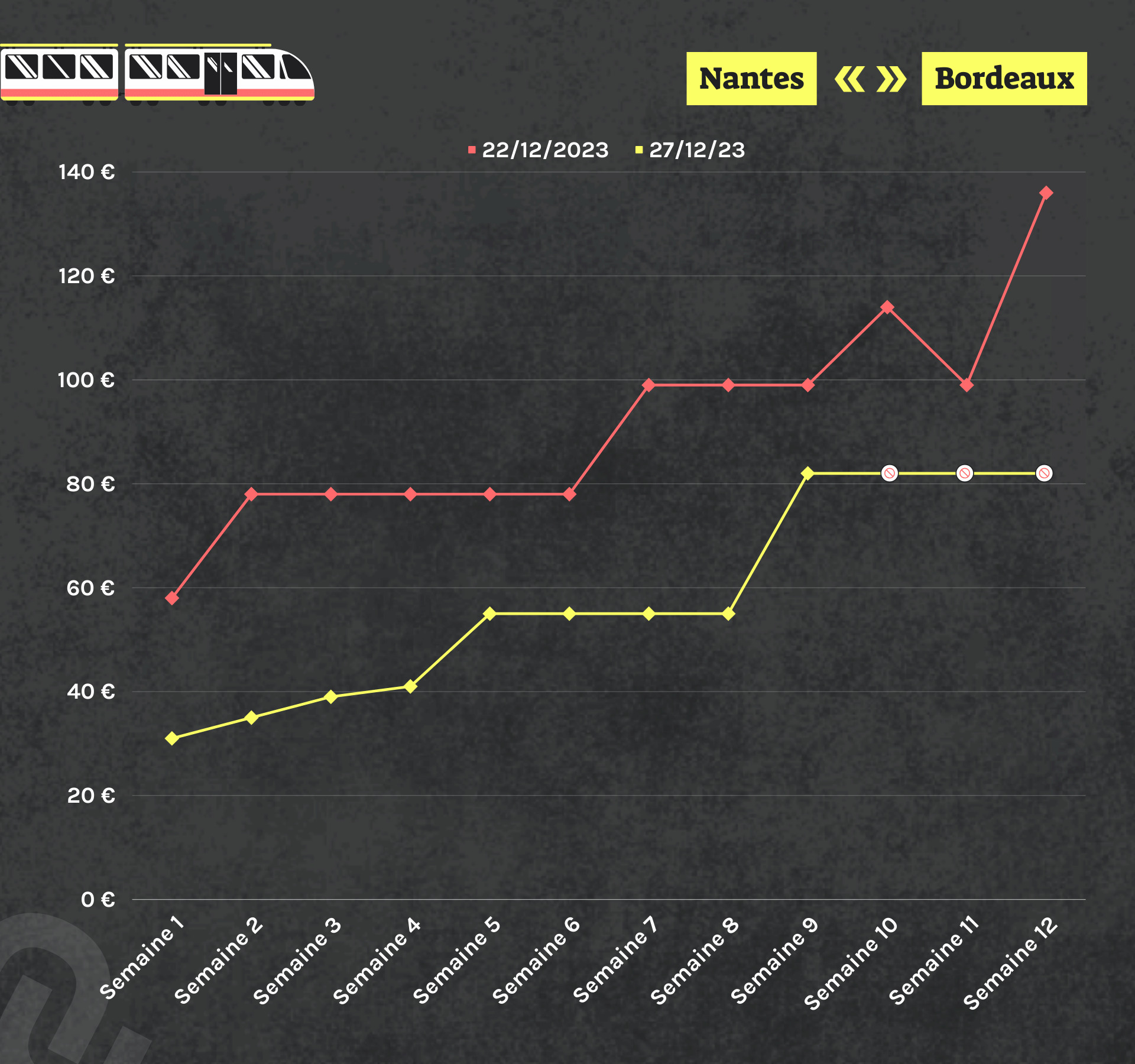
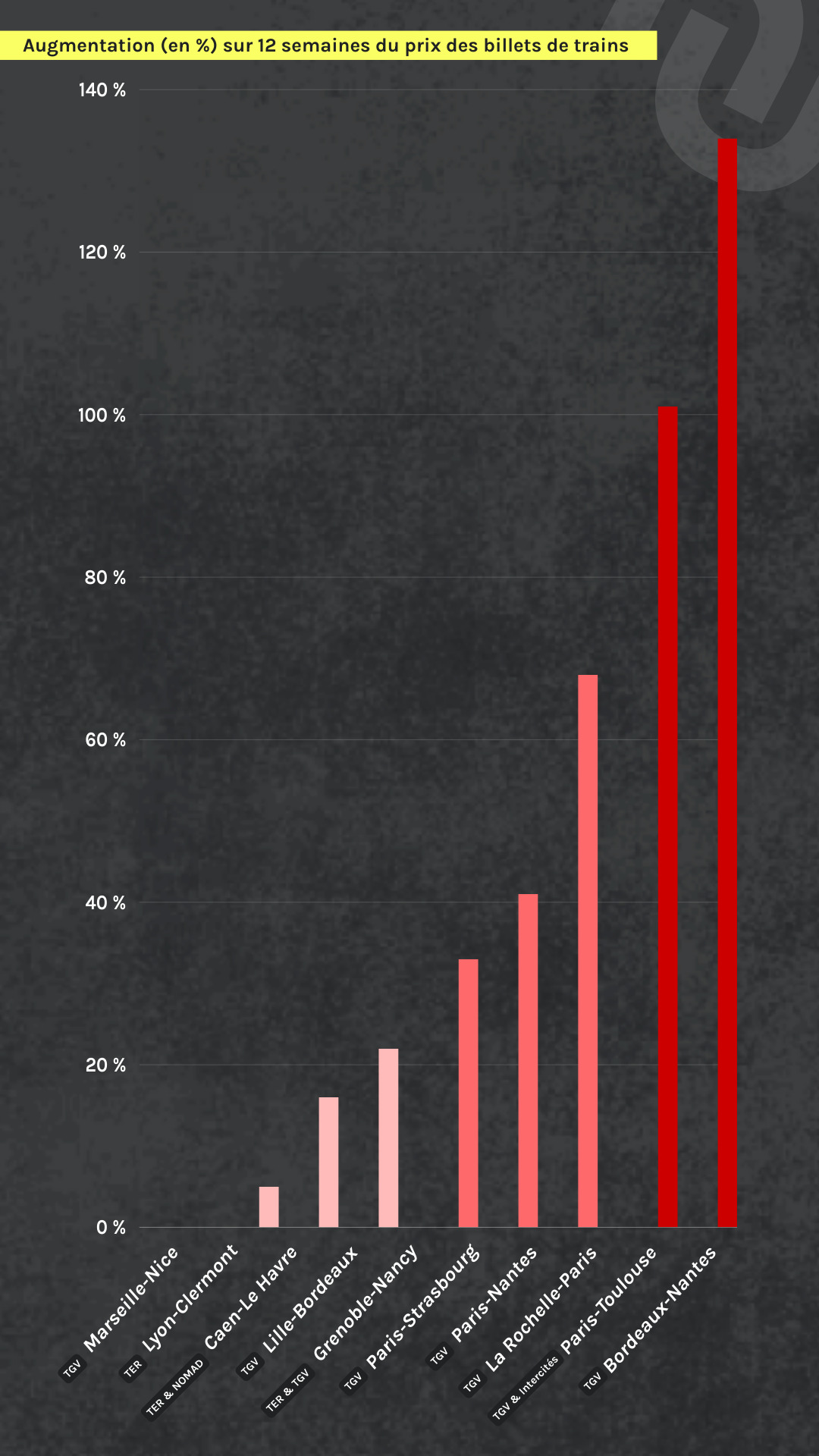
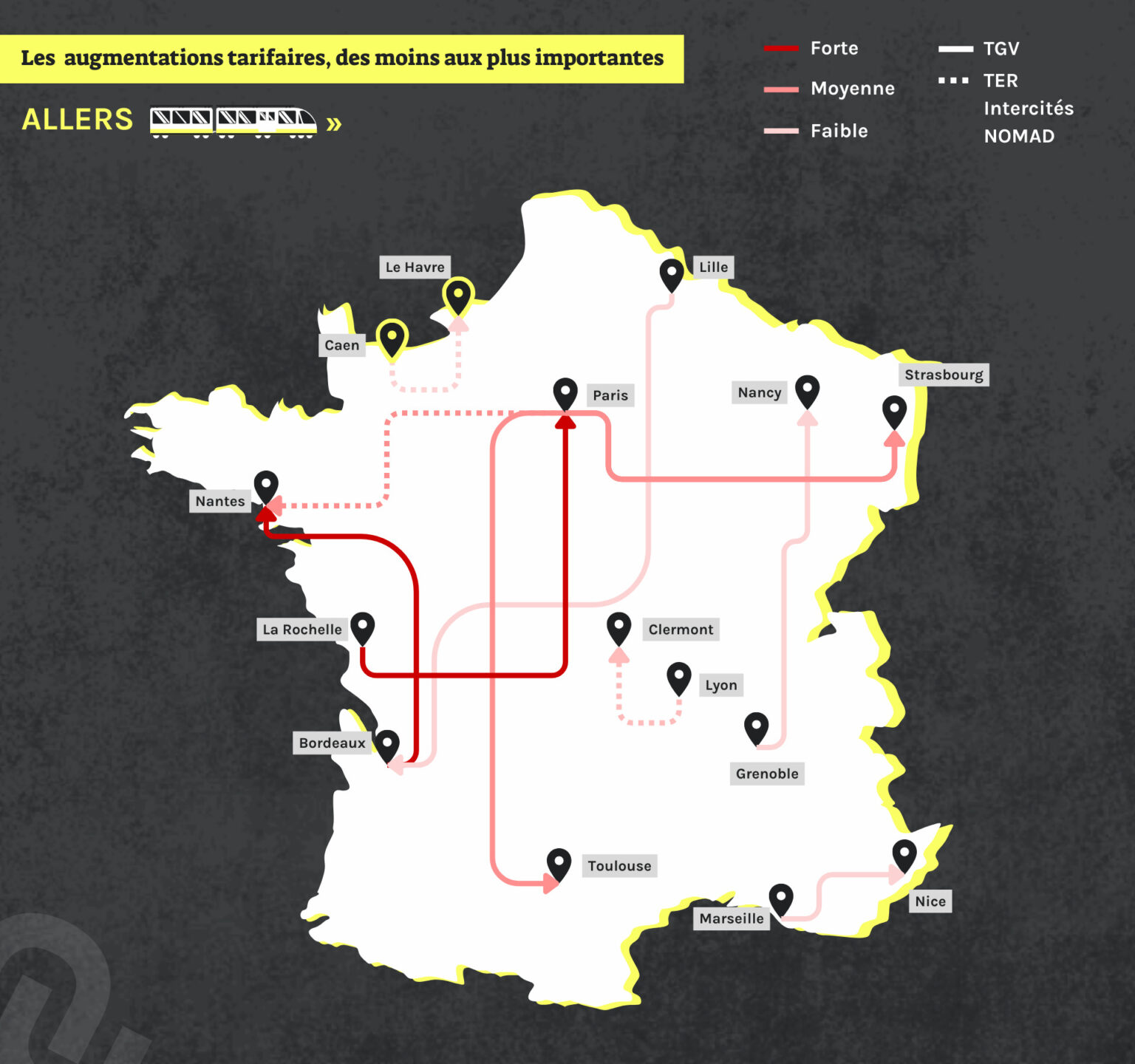
Sécurité, stationnement, déchets… #Nîmes a inauguré, à l’automne 2023, son « #hyperviseur_urbain ». Alors que la collecte et la circulation des #données sont au cœur de ce système, l’antenne locale de la Ligue des droits de l’homme s’inquiète. D’autres villes, comme #Dijon, ont déjà fait ce choix.
La salle a des allures de centre spatial : un mur de plus de 20 mètres de long totalement recouvert d’écrans, 76 au total, chacun pouvant se diviser en neuf. Ici parviennent les images des 1 300 #caméras disposées dans la ville de Nîmes et dans certaines communes de son agglomération.
A la pointe depuis 2001 sur le thème des #caméras_urbaines, se classant sur le podium des villes les plus vidéosurveillées du pays, Nîmes a inauguré, le 13 novembre 2023, son « #hyperviseur ». Ce plateau technique et confidentiel de 600 mètres carrés est entièrement consacré à une « nouvelle démarche de #territoire_intelligent », indique le maire (Les Républicains), Jean-Paul Fournier, réélu pour un quatrième mandat en 2020.
Avec cet outil dernier cri, sur lequel se relaient nuit et jour une cinquantaine de personnes, la ville fait un grand pas de plus vers la #smart_city (la « #ville_connectée »), une tendance en plein développement pour la gestion des collectivités.
Ce matin-là, les agents en poste peuvent facilement repérer, à partir d’images de très haute qualité, un stationnement gênant, un véhicule qui circule trop vite, un dépotoir sauvage, un comportement étrange… L’hyperviseur concentre toutes les informations en lien avec la gestion de l’#espace_public (sécurité, circulation, stationnement, environnement…), permet de gérer d’un simple clic l’éclairage public d’un quartier, de mettre une amende à distance (leur nombre a augmenté de 23 % en un an avec la #vidéoverbalisation) ou de repérer une intrusion dans un des 375 bâtiments municipaux connectés.
La collecte et la circulation des données en temps réel sont au cœur du programme. Le système s’appuie sur des caméras dotées, et c’est la nouveauté, de logiciels d’intelligence artificielle dont les #algorithmes fournissent de nouvelles informations. Car il ne s’agit plus seulement de filmer et de surveiller. « Nous utilisons des caméras qui permettent de gérer en temps réel la ville et apportent des analyses pour optimiser la consommation d’énergie, par exemple, ou gérer un flux de circulation grâce à un logiciel capable de faire du comptage et de la statistique », explique Christelle Michalot, responsable de ce centre opérationnel d’#hypervision_urbaine.
#Reconnaissance_faciale
Si la municipalité n’hésite pas à présenter, sur ses réseaux sociaux, ce nouveau dispositif, elle est en revanche beaucoup plus discrète lorsqu’il s’agit d’évoquer les #logiciels utilisés. Selon nos informations, la ville travaille avec #Ineo, une entreprise française spécialisée dans le domaine de la #ville_intelligente. Le centre de police municipale est également équipé du logiciel de #surveillance_automatisée #Syndex, et d’un logiciel d’analyse pour images de vidéosurveillance très performant, #Briefcam.
Ce dernier logiciel, de plus en plus répandu dans les collectivités françaises, a été mis au point par une société israélienne rachetée par le japonais #Canon, en 2018. Il est surtout au cœur de plusieurs polémiques et d’autant d’actions en justice intentées par des syndicats, des associations et des collectifs qui lui reprochent, notamment, de permettre la reconnaissance faciale de n’importe quel individu en activant une fonctionnalité spécifique.
Le 22 novembre 2023, le tribunal administratif de Caen a condamné la communauté de communes normande #Cœur-Côte-Fleurie, ardente promotrice de cette solution technologique, « à l’effacement des données à caractère personnel contenues dans le fichier », en estimant que l’utilisation de ce type de caméras dites « intelligentes » était susceptible de constituer « une atteinte grave et manifestement illégale au #respect_de_la_vie_privée ». D’autres décisions de la #justice administrative, comme à #Nice et à #Lille, n’ont pas condamné l’usage en soi du #logiciel, dès lors que la possibilité de procéder à la reconnaissance faciale n’était pas activée.
A Nîmes, le développement de cette « surveillance de masse » inquiète la Ligue des droits de l’homme (LDH), la seule association locale à avoir soulevé la question de l’utilisation des #données_personnelles au moment de la campagne municipale, et qui, aujourd’hui encore, s’interroge. « Nous avons le sentiment qu’on nous raconte des choses partielles quant à l’utilisation de ces données personnelles », explique le vice-président de l’antenne nîmoise, Jean Launay.
« Nous ne sommes pas vraiment informés, et cela pose la question des #libertés_individuelles, estime celui qui craint une escalade sans fin. Nous avons décortiqué les logiciels : ils sont prévus pour éventuellement faire de la reconnaissance faciale. C’est juste une affaire de #paramétrage. » Reconnaissance faciale officiellement interdite par la loi. Il n’empêche, la LDH estime que « le #droit_à_la_vie_privée passe par l’existence d’une sphère intime. Et force est de constater que cette sphère, à Nîmes, se réduit comme peau de chagrin », résume M. Launay.
« Des progrès dans de nombreux domaines »
L’élu à la ville et à Nîmes Métropole Frédéric Escojido s’en défend : « Nous ne sommes pas Big Brother ! Et nous ne pouvons pas faire n’importe quoi. L’hyperviseur fonctionne en respectant la loi, le #RGPD [règlement général sur la protection des données] et selon un cahier des charges très précis. » Pour moderniser son infrastructure et la transformer en hyperviseur, Nîmes, qui consacre 8 % de son budget annuel à la #sécurité et dépense 300 000 euros pour installer entre vingt-cinq et trente nouvelles caméras par an, a déboursé 1 million d’euros.
La métropole s’est inspirée de Dijon, qui a mis en place un poste de commandement partagé avec les vingt-trois communes de son territoire il y a cinq ans. En 2018, elle est arrivée deuxième aux World Smart City Awards, le prix mondial de la ville intelligente.
Dans l’agglomération, de grands panneaux lumineux indiquent en temps réel des situations précises. Un accident, et les automobilistes en sont informés dans les secondes qui suivent par le biais de ces mâts citadins ou sur leur smartphone, ce qui leur permet d’éviter le secteur. Baptisé « #OnDijon », ce projet, qui mise aussi sur l’open data, a nécessité un investissement de 105 millions d’euros. La ville s’est associée à des entreprises privées (#Bouygues_Telecom, #Citelum, #Suez et #Capgemini).
A Dijon, un #comité_d’éthique et de gouvernance de la donnée a été mis en place. Il réunit des habitants, des représentants de la collectivité, des associations et des entreprises pour établir une #charte « de la #donnée_numérique et des usages, explique Denis Hameau, adjoint au maire (socialiste) François Rebsamen et élu communautaire. La technique permet de faire des progrès dans de nombreux domaines, il faut s’assurer qu’elle produit des choses justes dans un cadre fixe. Les données ne sont pas là pour opprimer les gens, ni les fliquer ».
Des « systèmes susceptibles de modifier votre #comportement »
Nice, Angers, Lyon, Deauville (Calvados), Orléans… Les villes vidéogérées, de toutes tailles, se multiplient, et avec elles les questions éthiques concernant l’usage, pour le moment assez flou, des données personnelles et la #surveillance_individuelle, même si peu de citoyens semblent s’en emparer.
La Commission nationale de l’informatique et des libertés (CNIL), elle, veille. « Les systèmes deviennent de plus en plus performants, avec des #caméras_numériques capables de faire du 360 degrés et de zoomer, observe Thomas Dautieu, directeur de l’accompagnement juridique de la CNIL. Et il y a un nouveau phénomène : certaines d’entre elles sont augmentées, c’est-à-dire capables d’analyser, et ne se contentent pas de filmer. Elles intègrent un logiciel capable de faire parler les images, et ces images vont dire des choses. »
Cette nouveauté est au cœur de nouveaux enjeux : « On passe d’une situation où on était filmé dans la rue à une situation où nous sommes analysés, reprend Thomas Dautieu. Avec l’éventuel développement des #caméras_augmentées, quand vous mettrez un pied dans la rue, si vous restez trop longtemps sur un banc, si vous prenez un sens interdit, vous pourrez être filmé et analysé. Ces systèmes sont susceptibles de modifier votre comportement dans l’espace public. Si l’individu sait qu’il va déclencher une alerte s’il se met à courir, peut-être qu’il ne va pas courir. Et cela doit tous nous interpeller. »
Actuellement, juridiquement, ces caméras augmentées ne peuvent analyser que des objets (camions, voitures, vélos) à des fins statistiques. « Celles capables d’analyser des comportements individuels ne peuvent être déployées », assure le directeur à la CNIL. Mais c’est une question de temps. « Ce sera prochainement possible, sous réserve qu’elles soient déployées à l’occasion d’événements particuliers. » Comme les Jeux olympiques.
Le 19 mai 2023, le Parlement a adopté une loi pour mieux encadrer l’usage de la #vidéoprotection dite « intelligente ». « Le texte permet une expérimentation de ces dispositifs, et impose que ces algorithmes ne soient mis en place, avec autorisation préfectorale, dans le temps et l’espace, que pour une durée limitée, par exemple pour un grand événement comme un concert. Ce qui veut dire que, en dehors de ces cas, ce type de dispositif ne peut pas être déployé », insiste Thomas Dautieu. La CNIL, qui a déjà entamé des contrôles de centres d’hypervision urbains en 2023, en fait l’une de ses priorités pour 2024.































































{kind=link}