L’oiseau, le milliardaire et le précipice. – affordance.info
▻https://affordance.framasoft.org/2022/08/cest-pas-elon-qui-prend-twitter
Un aperçu des enjeux technos-commerciaux du rachat de Twitter
L’oiseau, le milliardaire et le précipice. – affordance.info
▻https://affordance.framasoft.org/2022/08/cest-pas-elon-qui-prend-twitter
Un aperçu des enjeux technos-commerciaux du rachat de Twitter

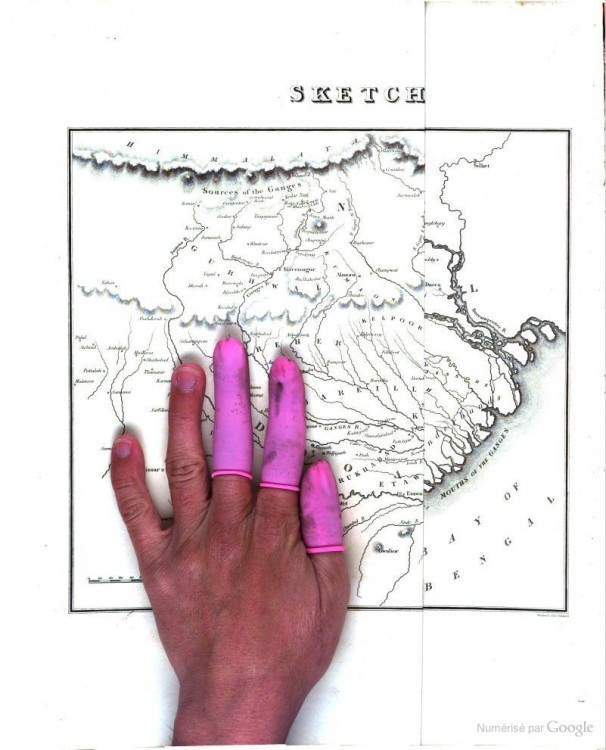
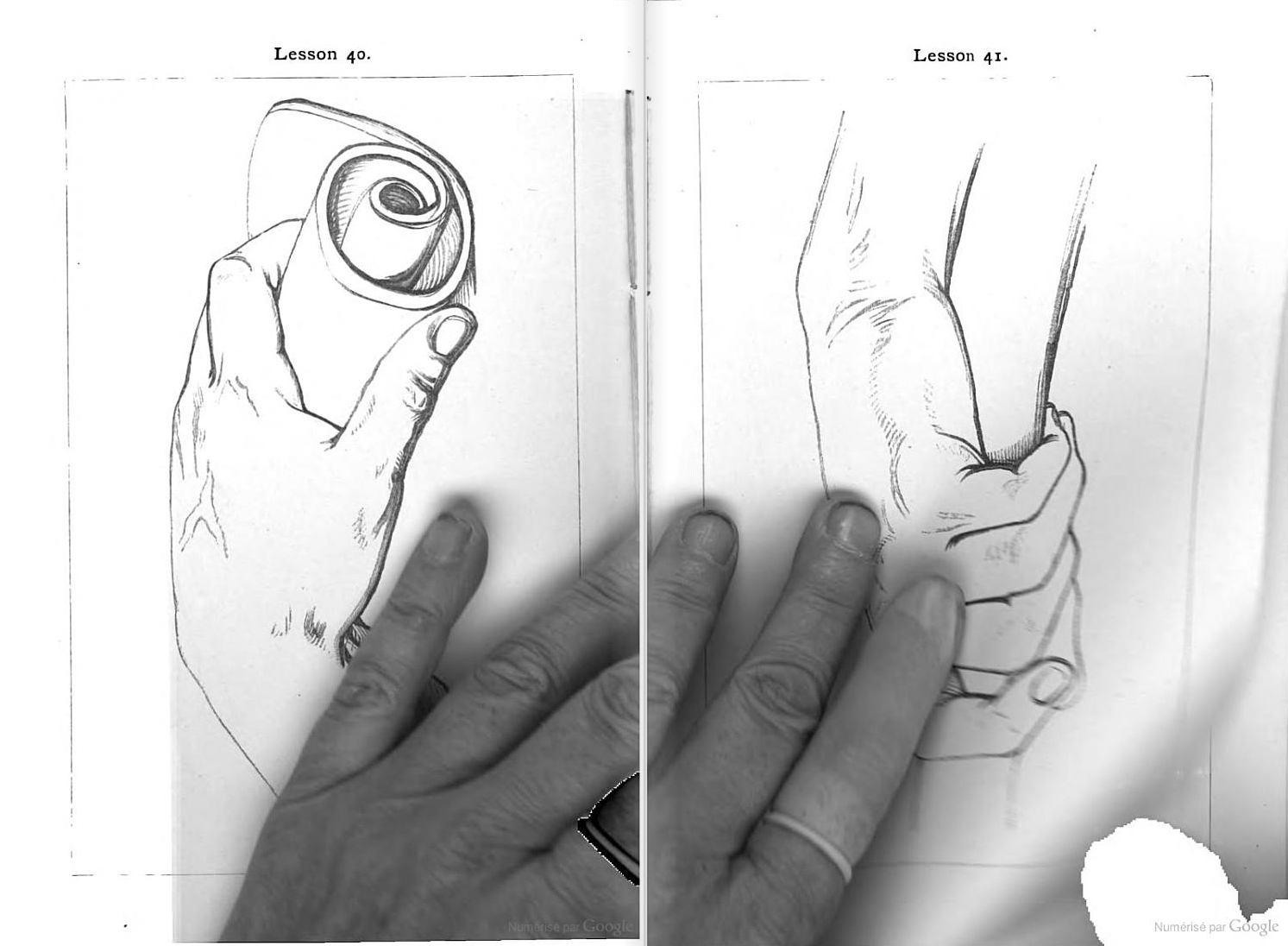
Les petites mains de Google Books
▻http://www.laboiteverte.fr/les-petites-mains-de-google-books
Google Books a scanné plus de 30 millions de livres prêtés par différentes institutions, utilisant des machines capables de photographier plus de 1000 pages par heure, la plupart des numérisations sont très bonnes mais sur la multitude de pages il est inévitable qu’il subsiste quelques bugs, l’un des plus intéressant apparaît quand l’opérateur oublie ou est obligé de laisser ses doigts sur la photo ce qui laisse apparaître les mains qui font marcher cette gigantesque machine. Parfois les algorithmes de Google détectent ces erreurs et essaient de les corriger, ce qui les déforme et en change les couleurs pour laisser apparaître cette fois les manipulations de la machine. Le site « The Art of Google Books » compile ces bugs et erreurs. via (...)

Révélation : c’est #Aaron_Swartz qui libérait les livres de Google Books sur Internet Archive ! | : : S.I.Lex : :
►http://scinfolex.wordpress.com/2013/02/06/cest-aaron-swartz-qui-liberait-les-livres-de-google-books-sur-i
Il y avait aussi d’autres collections du domaine public, celle des livres de #Google_Books. Google a numérisé et mis en ligne un grand nombre d’ouvrages du #domaine_public sur son site internet, mais l’accès est vraiment très pénible. Si vous voulez un livre, vous pouvez l’avoir. Mais si vous voulez 100 livres, ils bloquent votre adresse IP et ils vous bannissent pour toujours. Voilà ce qu’ils appellent un accès public au domaine public… Et un jour, on a vu arriver dans l’Internet Archive des chargements de livres, qui sont allés de plus en plus vite. D’où venaient-ils ? C’était Aaron ! Lui et quelques amis avaient imaginé un système où, avec quelques ordinateurs, ils pouvaient déjouer la limite fixée par Google et obtenir des masses de livres de Google Books pour les charger dans l’Internet Archive. Google n’a pas vraiment réagi, mais ses bibliothèques partenaires ont protesté…
Quand c’est arrivé, nous nous sommes demandés ce qui allait se passer, mais il n’y a rien eu. C’était du domaine public. Nous avons utilisé les données pour faire un lien en retour vers Google. Et tout ça marche bien. C’était encore une fois Aaron, qui avait voulu donner un accès public au domaine public. Ce qui me déchire, c’est qu’Aaron a été poursuivi par la justice fédérale pour avoir fait quelque chose que l’Internet Archive encourage activement et encourage les autres à faire. Et nous pensons que toutes les bibliothèques devraient l’encourager également. Permettre le téléchargement massif pour pouvoir effectuer du data mining et d’autres formes de recherche assistées par ordinateur. C’est tout simplement dans l’ordre des choses.

La #vie des #livres
The Art of Google Books
►http://theartofgooglebooks.tumblr.com
The adversaria of #Google_Books: captured mark of the hand and digitization as rephotography.

#Ebooks : Tolkien et Orwell retirés du #domaine_public
►http://www.idboox.com/ebook/infos-ebooks/ebooks-tolkien-et-orwell-retires-du-domaine-public
Les œuvres de JRR Tolkien et George Orwell ont été retirées du domaine public par décision de la Cour suprême des Etats-Unis. Les éditeurs et les fournisseurs de livres numériques comme Google eBooks ou Amazon ne pourront donc pas exploiter ces contenus gratuitement.
D’autres géants de la culture comme Alfred Hitchcock, Pablo Picasso et Igor Stravinsky sont également retirés du domaine public. Leurs œuvres sont donc sous copyright et personne ne pourra les exploiter sans accord des ayants droits.
Google a mal pris les choses et espère que les juges changeront leur fusil d’épaule. Selon la firme de Mountain View, cette décision va amputer le catalogue de livres électroniques #Google_books de millions de références.
#cdp

Sais-tu ce qui rend ce tour de passe-passe possible ? Sur quoi se base cette décision ?
Des pistes ici : ►http://www.actualitte.com/actualite/monde-edition/international/usa-des-textes-de-tolkien-et-orwell-quittent-le-domaine-public-31402.htm
►http://www.nytimes.com/2012/01/19/business/public-domain-works-can-be-copyrighted-anew-justices-rule.html?_r=1
►http://online.wsj.com/article/SB10001424052970204555904577168752017626174.html

La fin de l’hégémonie de #Google Books ? | Calimaq
►http://owni.fr/2011/07/28/la-fin-de-lhegemonie-de-google-books
Google serait contraint d’obtenir un accord explicite des auteurs avant la numérisation de leurs œuvres. Que faire pour la numérisation des œuvres orphelines ?
Une recherche Google Books en flux #RSS, c’est possible - Plugin Booksearch - #SPIP-Contrib
►http://www.spip-contrib.net/Plugin-Booksearch
L’#API de #Google_Books permet de faire une recherche dans les livres, mais le format de retour est exclusivement JSON ; pour effectuer une veille permanente sur un terme donné, ce plugin contient un squelette qui emploie l’API JSON avec une boucle DATA, et retourne le résultat au format RSS.
PS/ les copains qui le souhaitent peuvent ne rien installer et passer directement par mon serveur pour utiliser cette petite passerelle : m’envoyer un mail.
Quand Google Books permet de comprendre notre génome culturel « InternetActu.net
►http://www.internetactu.net/2011/06/20/quand-google-books-permet-de-comprendre-notre-genome-culturel
l’étude de l’évolution de la #culture nécessitait quelque chose comme un génome, une base de #données si puissante qu’elle permettrait à de telles analyses d’être faites rapidement, sur toutes sortes de sujets, pas seulement les verbes irréguliers. Et on a remarqué que certains des livres très obscurs que nous utilisions apparaissaient sur #Google_Books. On a fait le lien.” Et voici comment Harvard et Google Books se mettent à travailler ensemble.
#Google_Books #API
►http://code.google.com/apis/books/docs/v1/using.html
You can perform a volumes search by sending an HTTP GET request to the following URI:
►https://www.googleapis.com/books/v1/volumes?q=search+terms
This request has a single required parameter:
q - Search for volumes that contain this text string. There are special keywords you can specify in the search terms to search in particular fields, such as:
intitle: Returns results where the text following this keyword is found in the title.
inauthor: Returns results where the text following this keyword is found in the author.
inpublisher: Returns results where the text following this keyword is found in the publisher.
subject: Returns results where the text following this keyword is listed in the category list of the volume.
isbn: Returns results where the text following this keyword is the #ISBN number.
3 millions de livres libérés par la British Library
►http://www.numerama.com/magazine/17420-3-millions-de-livres-liberes-par-la-british-library.html
« la #British_Library a libéré pas moins de trois millions de documents sous licence Creative Commons Zero (CC0). Cette décision couvre de nombreux ouvrages publiés depuis 1950 au Royaume-Uni et en Irlande.
La licence #Creative_Commons_Zero est un contrat assez récent. Alors que les six grandes licences existent depuis le début de la fondation, la licence Creative Commons Zero a vu le jour au printemps 2009. Celle-ci de renoncer à un maximum de droits d’auteur afin d’être au plus proche du domaine public. N’importe qui peut ainsi copier, modifier et distribuer le document sans demander de permission et pour un usage commercial ou non. »

Je n’ai pas téléchargé les documents, mais la description que j’en ai trouvé, c’est « British National Bibliography records » :
►http://wiki.creativecommons.org/Case_Studies/British_Library
Ce que j’en comprends, c’est qu’il ne s’agit pas de livres, mais de fiches bibliographiques.
Ah ça c’est une exagération typique de #numérama. Bon, c’est déjà pas mal ; mais j’ai cherché des bouquins sur ma commune, et le moteur n’a rien retourné, contrairement à #google_books qui m’en envoie plusieurs chaque jour.