Jolies déductions :)
La facette « follow » est établie sur la base de l’attribut multivalué {auteur initial + partageurs}. Les intervenants dans la discussion ne sont donc pas comptés en tant que tels (ils sont indexés dans un autre attribut, mais pas utilisés dans l’interface : l’idée est que si je ne partage pas un billet, mes suiveurs n’ont pas forcément vocation à être alertés que je suis en train d’y discuter).
Chacune des facettes, comme tu l’as constaté, est limitée aux 20 éléments ayant le plus fort effectif, et à condition qu’il soit > 1.
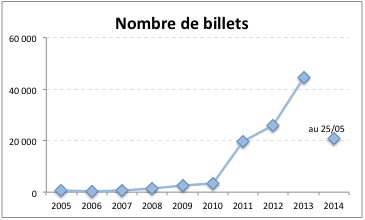
Le système recense à cet instant 156548 billets publiés. Il existe des billets effacés (11197 dont une trace reste dans le système, sans compter ceux de quelques tests, ou du compte machin, qui ont carrément été supprimés).
Pour ce qui est de fouiller plus avant dans les données, je pense qu’il sera plus efficace de créer des requêtes ad hoc. Le langage d’interrogation, très proche du SQL, est assez parlant.
Par exemple pour avoir le nombre de billets publiés mois par mois :
SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
La même chose pour les billets qui répondent à un critère fulltext :
SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where MATCH('spip') AND properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
etc.
Concernant la suggestion de trier selon l’intensité des discussions : il n’y aurait aucun obstacle technique, sachant que les éléments nécessaires (liste des participants à chaque discussion) sont déjà indexés. En revanche, il me semble qu’il s’agit d’une fausse bonne idée : j’ai comme un doute en effet sur l’intérêt de mettre en valeur des discussions qui impliqueraient de nombreuses personnes, mais qu’aucune ne souhaiterait partager…
La vocation du moteur de recherche est de permettre de trouver aussi rapidement que possible une information précise, les décisions doivent se baser uniquement là-dessus, pour cette page en tout cas. Mais l’outil permet d’imaginer d’autres « vues » sur les données, qui pourront servir à l’administration du serveur, à créer des pages annexes, à repérer des « corrélations » entre les sujets, des proximités entre auteurs, une analyse du « dictionnaire » global, et que sais-je encore. Tout un champ à explorer !
PS : la doc de SphinxQL : ▻http://sphinxsearch.com/docs/current.html#expressions