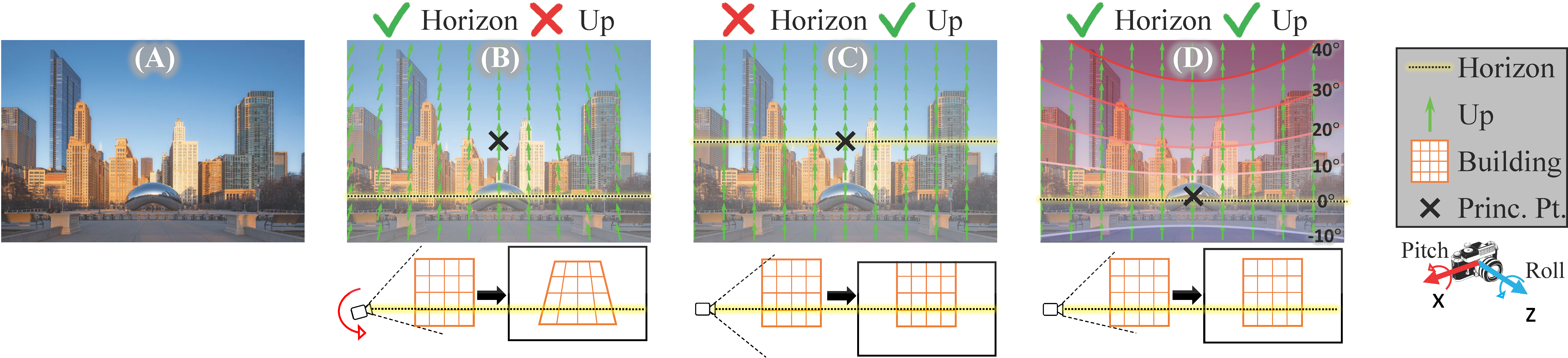
Perspective Fields
▻https://jinlinyi.github.io/PerspectiveFields
Perspective Fields
▻https://jinlinyi.github.io/PerspectiveFields
Comprendre ChatGPT (avec DefendIntelligence)
▻https://www.youtube.com/watch?v=j3fvoM5Er2k
Mieux comprendre ChatGPT, sans pour autant l’excuser pour ses fakes éhontés. Pour tout comprendre aux IA génératives.
__________________________
00:00 Introduction
03:45 Un peu de contexte
05:06 Les modèles de langage
05:37 L’énigme
06:45 La chambre chinoise
12:05 Comment ça fonctionne ?
17:12 L’exposition médiatique
22:50 Bien interroger ChatGPT
26:39 Bien vérifier ce que dit ChatGPT
28:01 Détecter des textes générés par IA
33:45 Problématiques sur les données
39:24 À venir dans les moteurs de recherche
46:43 Conclusion
___________________________
ERREURS SIGNALEES
– à 13min : selon OpenAI le modèle GPT3 a été entraîné à partir de 570 Go de textes, pas juste 50Go (ça c’est la taille des données Wikipedia)
– à 48min : la citation n’est pas de Saint Thomas d’Aquin, mais bien de Saint-Thomas, l’apôtre.
Huemint - AI #color_palette generator
▻https://huemint.com
Huemint uses #machine_learning to create unique #color_schemes for your brand, website or graphic
Un énième générateur de palettes de couleurs, l’interface est sympa et permet de mettre facilement en situation les palettes générées.
]]>Pour la première fois, des drones auraient attaqué des humains de leur propre initiative
▻https://www.courrierinternational.com/article/guerre-pour-la-premiere-fois-des-drones-auraient-attaque-des-
D’après un rapport des Nations unies publié en mars dernier, des #attaques de #drones sans aucune intervention humaine ont été recensées en #Libye. On ne sait pas s’il y a eu des victimes, mais cet événement prouverait que les tentatives de réguler les #robots_tueurs ont déjà un train de retard.
Des milliards d’arbres cartographiés dans le désert grâce à des satellites et des supercalculateurs
▻https://theconversation.com/des-milliards-darbres-cartographies-dans-le-desert-grace-a-des-sate
Les zones arides et semi-arides sont à l’étude depuis longtemps, pour savoir si leur couvert végétal régresse. En effet, la théorie selon laquelle le Sahara s’étendait et la végétation ligneuse reculait a été émise pour la première fois dans les années 1930. Puis, la « grande sécheresse » des années 1970 au Sahel a mis l’accent sur la désertification causée par la surexploitation et par le changement climatique. Au cours des dernières décennies, c’est l’impact potentiel du changement climatique sur la végétation qui a été la principale préoccupation – et l’effet rétroactif de la végétation sur le climat, lié au rôle de la végétation dans le cycle global du carbone.
#végétalisation #arbres #machine_learning #apprentissage_automatique #technologie #Afrique_sahélienne #désertification
On espère seulement que ces technologies somme toute fort coûteuses ne serviront pas à spolier les habitant·es de la région de leurs terres cultivables au profit de quelques consortiums financiaro-industriels.
]]>43 covers 50 cents
▻https://p.xuv.be/43-covers-50-cents
Machine learning voice synthesis does wonders these days. ↬ waxy.org
# !me #en #Cover_Tuesday #Machine_Learning #video
L’accès et la circulation des savoirs se font dans un monde de plus en plus ouvert. Les données en libre accès se multiplient, mais leurs usages ne vont pas de soi… #numérique #internet #usages #openaccess
►https://sms.hypotheses.org/24810
Open source, open educational resources, open data, open courses, ces différentes expressions anglophones traduisent la multiplication des données actuellement accessibles en mode ouvert sur le web. Elles modifient progressivement les modalités d’accès et de circulation des savoirs à l’ère des géants du numérique –les GAFAM. Dans les domaines de l’éducation comme des données publiques, leurs usages ne vont pas forcément de soi.
Ces questionnements ont fait l’objet d’un ouvrage collectif coordonné par Luc Massou, Brigitte Juanals, Philippe Bonfils et Philippe Dumas, regroupant une sélection de communications sur les sources ouvertes numériques dans le secteur éducatif et social réalisées lors d’un colloque à l’université Aix-Marseille en 2016 (...)
]]>Comment réussir son projet de #Machine_Learning ?
▻https://makina-corpus.com/blog/metier/2020/reussir-son-projet-de-machine-learning
Voici quelques retours d’expérience et des indications pour vous aider à réussir vos projets de machine learning
What AI still can’t do - MIT Technology Review
▻https://www.technologyreview.com/s/615189/what-ai-still-cant-do
In less than a decade, computers have become extremely good at diagnosing diseases, translating languages, and transcribing speech. They can outplay humans at complicated strategy games, create photorealistic images, and suggest useful replies to your emails.
Yet despite these impressive achievements, artificial intelligence has glaring weaknesses.
Machine-learning systems can be duped or confounded by situations they haven’t seen before. A self-driving car gets flummoxed by a scenario that a human driver could handle easily. An AI system laboriously trained to carry out one task (identifying cats, say) has to be taught all over again to do something else (identifying dogs). In the process, it’s liable to lose some of the expertise it had in the original task. Computer scientists call this problem “catastrophic forgetting.”
These shortcomings have something in common: they exist because AI systems don’t understand causation. They see that some events are associated with other events, but they don’t ascertain which things directly make other things happen. It’s as if you knew that the presence of clouds made rain likelier, but you didn’t know clouds caused rain.
But there’s a growing consensus that progress in AI will stall if computers don’t get better at wrestling with causation. If machines could grasp that certain things lead to other things, they wouldn’t have to learn everything anew all the time—they could take what they had learned in one domain and apply it to another. And if machines could use common sense we’d be able to put more trust in them to take actions on their own, knowing that they aren’t likely to make dumb errors.
Pearl’s work has also led to the development of causal Bayesian networks—software that sifts through large amounts of data to detect which variables appear to have the most influence on other variables. For example, GNS Healthcare, a company in Cambridge, Massachusetts, uses these techniques to advise researchers about experiments that look promising.
In one project, GNS worked with researchers who study multiple myeloma, a kind of blood cancer. The researchers wanted to know why some patients with the disease live longer than others after getting stem-cell transplants, a common form of treatment. The software churned through data with 30,000 variables and pointed to a few that seemed especially likely to be causal. Biostatisticians and experts in the disease zeroed in on one in particular: the level of a certain protein in patients’ bodies. Researchers could then run a targeted clinical trial to see whether patients with the protein did indeed benefit more from the treatment. “It’s way faster than poking here and there in the lab,” says GNS cofounder Iya Khalil.
Nonetheless, the improvements that Pearl and other scholars have achieved in causal theory haven’t yet made many inroads in deep learning, which identifies correlations without too much worry about causation. Bareinboim is working to take the next step: making computers more useful tools for human causal explorations.
Getting people to think more carefully about causation isn’t necessarily much easier than teaching it to machines, he says. Researchers in a wide range of disciplines, from molecular biology to public policy, are sometimes content to unearth correlations that are not actually rooted in causal relationships. For instance, some studies suggest drinking alcohol will kill you early, while others indicate that moderate consumption is fine and even beneficial, and still other research has found that heavy drinkers outlive nondrinkers. This phenomenon, known as the “reproducibility crisis,” crops up not only in medicine and nutrition but also in psychology and economics. “You can see the fragility of all these inferences,” says Bareinboim. “We’re flipping results every couple of years.”
On reste quand même dans la fascination technologique
Bareinboim described this vision while we were sitting in the lobby of MIT’s Sloan School of Management, after a talk he gave last fall. “We have a building here at MIT with, I don’t know, 200 people,” he said. How do those social scientists, or any scientists anywhere, decide which experiments to pursue and which data points to gather? By following their intuition: “They are trying to see where things will lead, based on their current understanding.”
That’s an inherently limited approach, he said, because human scientists designing an experiment can consider only a handful of variables in their minds at once. A computer, on the other hand, can see the interplay of hundreds or thousands of variables. Encoded with “the basic principles” of Pearl’s causal calculus and able to calculate what might happen with new sets of variables, an automated scientist could suggest exactly which experiments the human researchers should spend their time on.
#Intelligence_artificielle #Causalité #Connaissance #Pragmatique #Machine_learning
]]>Hackers can trick a Tesla into accelerating by 50 miles per hour - MIT Technology Review
▻https://www.technologyreview.com/s/615244/hackers-can-trick-a-tesla-into-accelerating-by-50-miles-per-hour
Hackers have manipulated multiple Tesla cars into speeding up by 50 miles per hour. The researchers fooled the car’s MobilEye EyeQ3 camera system by subtly altering a speed limit sign on the side of a road in a way that a person driving by would almost never notice.
This demonstration from the cybersecurity firm McAfee is the latest indication that adversarial machine learning can potentially wreck autonomous driving systems, presenting a security challenge to those hoping to commercialize the technology.
MobilEye EyeQ3 camera systems read speed limit signs and feed that information into autonomous driving features like Tesla’s automatic cruise control, said Steve Povolny and Shivangee Trivedi from McAfee’s Advanced Threat Research team.
The researchers stuck a tiny and nearly imperceptible sticker on a speed limit sign. The camera read the sign as 85 instead of 35 and, in testing, both the 2016 Tesla Model X and that year’s Model S sped up 50 miles per hour.
The modified speed limit sign reads as 85 on the Tesla’s heads-up display. A Mobileye spokesperson downplayed the research by suggesting this sign would fool a human into reading 85 as well.
MCAFEE
The Tesla, reading the modified 35 as 85, is tricked into accelerating.
MCAFEE
This is the latest in an increasing mountain of research showing how machine learning systems can be attacked and fooled in life-threatening situations.
“Why we’re studying this in advance is because you have intelligent systems that at some point in the future are going to be doing tasks that are now handled by humans,” Povolny said. “If we are not very prescient about what the attacks are and very careful about how the systems are designed, you then have a rolling fleet of interconnected computers which are one of the most impactful and enticing attack surfaces out there.”
As autonomous systems proliferate, the issue extends to machine learning algorithms far beyond vehicles: A March 2019 study showed medical machine-learning systems fooled into giving bad diagnoses.
A Mobileye spokesperson downplayed the research by suggesting the modified sign would even fool a human into reading 85 instead of 35. The company doesn’t consider tricking the camera to be an attack and, despite the role the camera plays in Tesla’s cruise control and the camera wasn’t designed for autonomous driving.
“Autonomous vehicle technology will not rely on sensing alone, but will also be supported by various other technologies and data, such as crowdsourced mapping, to ensure the reliability of the information received from the camera sensors and offer more robust redundancies and safety,” the Mobileye spokesperson said in a statement.
Comme je cherchais des mots clés, je me disais que « #cyberattaque » n’était pas le bon terme, car l’attaque n’est pas via le numérique, mais bien en accolant un stocker sur un panneau physique. Il ne s’agit pas non plus d’une attaque destructive, mais simplement de « rendre fou (footing) » le système de guidage, car celui-ci ne « comprend » pas une situation. La réponse de MobilEye est intéressante : un véhicule autonome ne peut pas se fier à sa seule « perception », mais recouper l’information avec d’autres sources.
#Machine_learning #Véhicules_autonomes #Tesla #Panneau_routiers #Intelligence_artificielle
]]>AI bias creep is a problem that’s hard to fix | Biometric Update
▻https://www.biometricupdate.com/202002/__trashed-6
On the heels of a National Institute of Standards and Technology (NIST) study on demographic differentials of biometric facial recognition accuracy, Karen Hao, an artificial intelligence authority and reporter for MIT Technology Review, recently explained that “bias can creep in at many stages of the [AI] deep-learning process” because “the standard practices in computer science aren’t designed to detect it.”
“Fixing discrimination in algorithmic systems is not something that can be solved easily,” explained Andrew Selbst, a post-doctoral candidate at the Data & Society Research Institute, and lead author of the recent paper, Fairness and Abstraction in Sociotechnical Systems.
“A key goal of the fair-ML community is to develop machine-learning based systems that, once introduced into a social context, can achieve social and legal outcomes such as fairness, justice, and due process,” the paper’s authors, which include Danah Boyd, Sorelle A. Friedler, Suresh Venkatasubramanian, and Janet Vertesi, noted, adding that “(b)edrock concepts in computer science – such as abstraction and modular design – are used to define notions of fairness and discrimination, to produce fairness-aware learning algorithms, and to intervene at different stages of a decision-making pipeline to produce ‘fair’ outcomes.”
Consequently, just recently a broad coalition of more than 100 civil rights, digital justice, and community-based organizations issued a joint statement of civil rights concerns in which they highlighted concerns with the adoption of algorithmic-based decision making tools.
Explaining why “AI bias is hard to fix,” Hoa cited as an example, “unknown unknowns. The introduction of bias isn’t always obvious during a model’s construction because you may not realize the downstream impacts of your data and choices until much later. Once you do, it’s hard to retroactively identify where that bias came from and then figure out how to get rid of it.”
Hoa also blames “lack of social context,” meaning “the way in which computer scientists are taught to frame problems often isn’t compatible with the best way to think about social problems.”
Then there are the definitions of fairness where it’s not at all “clear what the absence of bias should look like,” Hoa argued, noting, “this isn’t true just in computer science – this question has a long history of debate in philosophy, social science, and law. What’s different about computer science is that the concept of fairness has to be defined in mathematical terms, like balancing the false positive and false negative rates of a prediction system. But as researchers have discovered, there are many different mathematical definitions of fairness that are also mutually exclusive.”
“A very important aspect of ethical behavior is to avoid (intended, perceived, or accidental) bias,” which they said “occurs when the data distribution is not representative enough of the natural phenomenon one wants to model and reason about. The possibly biased behavior of a service is hard to detect and handle if the AI service is merely being used and not developed from scratch since the training data set is not available.”
#Machine_learning #Intelligence_artificielle #Société #Sciences_sociales
]]>Série d’articles : ces innovations qui permettent à l’IA de sortir des laboratoires
▻https://makina-corpus.com/blog/metier/2020/vers-une-integration-realiste-des-ias-au-sein-dapplications-metiers
L’article présente la démarche mise en place par Makina Corpus lorsqu’une application métier doit intégrer un composant d’intelligence artificielle
Can a Machine Learn to Write for The New Yorker? | John Seabrook
▻https://www.newyorker.com/magazine/2019/10/14/can-a-machine-learn-to-write-for-the-new-yorker
John Seabrook on how predictive-text technology could transform the future of the written word. Source: The New Yorker
Out in the jungle, looking for a cave? Machine learning and lasers can help
https://massivesci.com/notes/machine-learning-caves-archaeology-spelunking-geology
New techniques are helping field researchers locate hard-to-spot caves
Emergent Tool Use from Multi-Agent Interaction
▻https://openai.com/blog/emergent-tool-use
▻https://www.youtube.com/watch?time_continue=83&v=kopoLzvh5jY
Utilisation de la vision par ordinateur pour redresser des images
▻https://makina-corpus.com/blog/metier/2019/redressement-dimages
Dans un module de comparaison d’images, lorsque deux photographies ne sont pas cadrées de la même manière, non-superposable, c’est frustrant. On vous propose ici d’y remédier avec du redressement d’images par homographie.
Mapmaking in the Age of Artificial Intelligence – descarteslabs-team
▻https://medium.com/descarteslabs-team/mapmaking-in-the-age-of-artificial-intelligence-da9e71be21d3
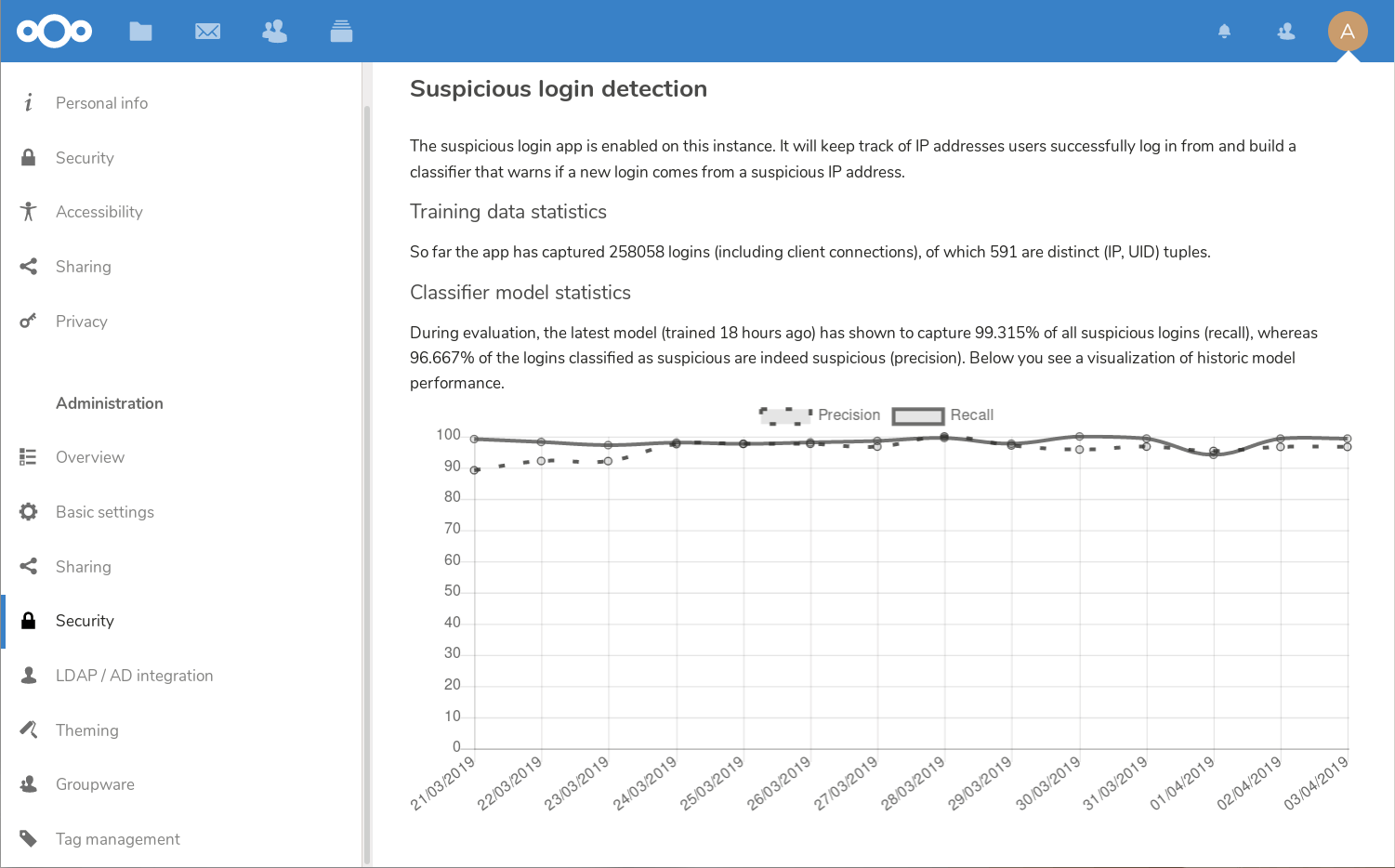
#Nextcloud 16 becomes smarter with #Machine_Learning for security and productivity – Nextcloud
▻https://nextcloud.com/blog/nextcloud-16-becomes-smarter-with-machine-learning-for-security-and-produ
The #Suspicious #Login Detection app tracks successful logins on the instance for a set period of time (default is 60 days) and then uses the generated data to train a neural network. As soon as the first model is trained, the app starts classifying logins. Should it detect a password login classified as suspicious by the trained model, it will add an entry to the suspicious_login table, including the timestamp, request id and URL. The user will get a notification and the system administrator will be able to find this information in the logs.
Plus de détail sur le blog de la personne qui a développé le bouzin :
▻https://blog.wuc.me/2019/04/25/nextcloud-suspicious-login-detection
Qui utilise ▻https://php-ml.org
Il y a peut-être des trucs à pomper pour #SPIP là dedans...
]]>Vers l’automatisation de la #Censure politique
▻https://www.laquadrature.net/2019/02/22/vers-lautomatisation-de-la-censure-politique
Une tribune de Félix Tréguer. Nous sommes à un tournant de la longue histoire de la censure. Ce tournant, c’est celui de la censure privée et automatisée. Il acte une rupture radicale avec les garanties associées…
OpenAI’s GPT-2: the model, the hype, and the controversy
▻https://medium.com/@lowe.ryan.t/openais-gpt-2-the-model-the-hype-and-the-controversy-1109f4bfd5e8
if we had an open-source model that could generate unlimited human-quality text with a specific message or theme, could that be bad?
I think the answer is yes. It’s true that humans can already write fake news articles, and that governments already recruit thousands of people to write biased comments tailored towards their agenda. But an automated system could: (1) enable bad actors, who don’t have the resources to hire thousands of people, to wage large-scale disinformation campaigns; and (2) drastically increase the scale of the disinformation campaigns already being run by state actors. These campaigns work because humans are heavily influenced by the number of people around them who share a certain viewpoint, even if the viewpoint doesn’t make sense. Increasing the scale should correspondingly increase the influence that governments and companies have over what we believe.
To combat this, we’ll need to start to researching detection methods for AI-generated text.
#machine_learning #texte #nlp #éthique #AI
]]>Détecter des formes dans des photos de paysage
▻https://makina-corpus.com/blog/metier/2019/detecter-des-formes-dans-des-photos-satellites
Et parce que c’est la St-Valentin, on détecte des cœurs !
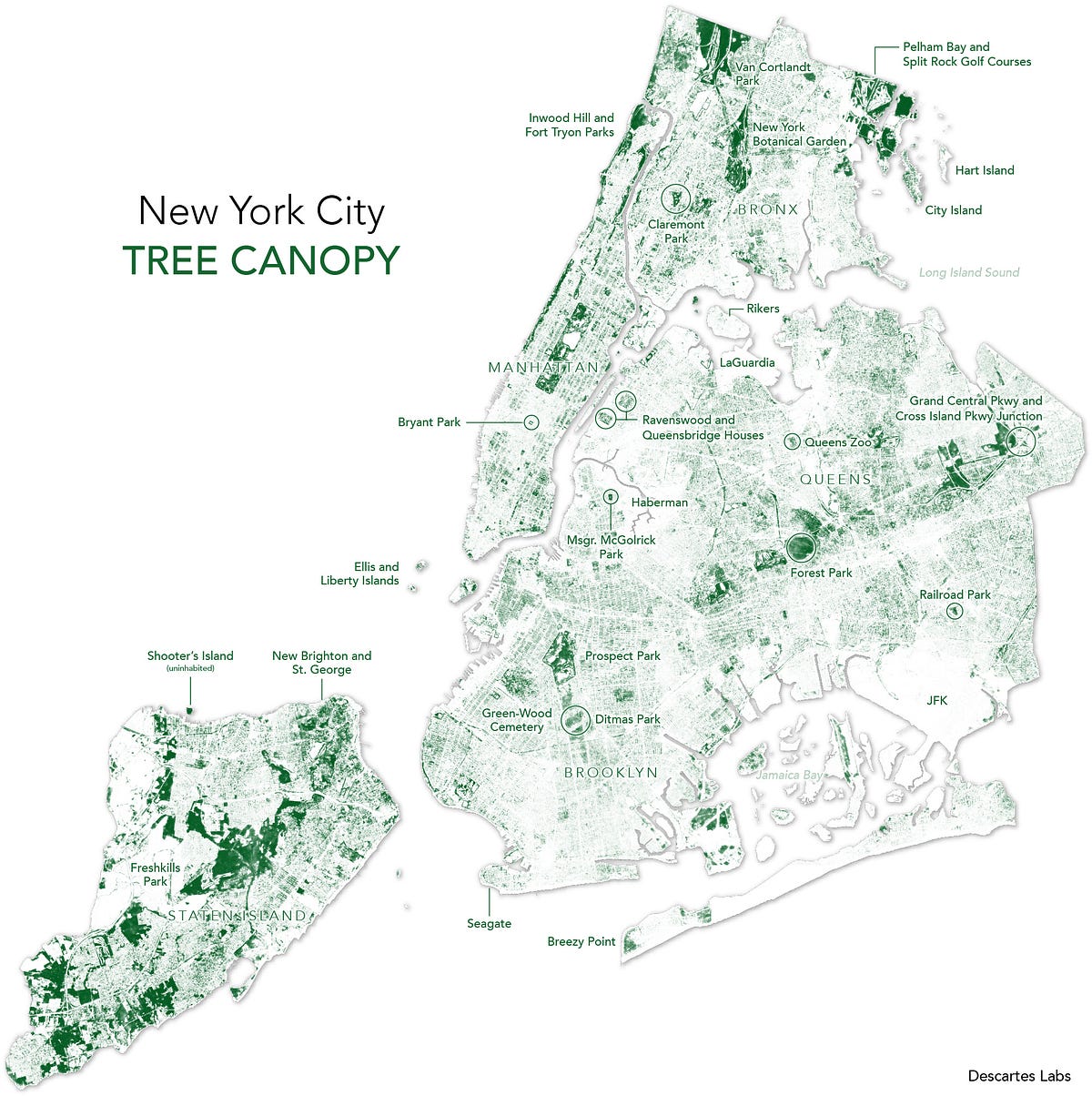
Mapping All of the Trees with Machine Learning – descarteslabs-team – Medium
▻https://medium.com/descarteslabs-team/descartes-labs-urban-trees-tree-canopy-mapping-3b6c85c5c9cc
All this fuss is not without good reason. Trees are great! They make oxygen for breathing, suck up CO₂, provide shade, reduce noise pollution, and just look at them — they’re beautiful!
8th Street in Park Slope, Brooklyn last May. Look at those beautiful trees!
The thing is, though, that trees are pretty hard to map. The 124,795 trees in the San Francisco Urban Forest Map shown below, for example, were cataloged over a year of survey work by a team of certified arborists. The database they created is thorough, with information on tree species and size as well as environmental factors like the presence of power lines or broken pavement.
But surveys like this are expensive to conduct, difficult to maintain, and provide an incomplete picture of the entire extent of the urban tree canopy. Both the San Francisco inventory below and the New York City TreesCount! do an impeccable job mapping the location, size and health of street trees, but exclude large chunks within the cities, like parks.
#Machine_Learning : détection d’anomalies
▻https://makina-corpus.com/blog/metier/2019/machine-learning-detection-anomalies
Comment détecter des anomalies dans vos datasets en utilisant des algorithmes de machine learning.
Prédiction du taux de monoxyde de carbone à Madrid - intérêt d’une approche #Deep_Learning
▻https://makina-corpus.com/blog/metier/2019/qualite-de-lair-a-madrid
Dans cet article nous montrons comme utiliser les bibliothèques stars de l’éco-système scientifique en Python pour analyser des données publiques sur la qualité de l’air à Madrid. Nous verrons comment identifier les problèmes liés à ces données. Puis nous comparerons deux approches en #Machine_Learning : AutoSklearn et les réseaux de neurones de type LSTM.
Prédiction du taux de monoxyde de carbone à Madrid - intérêt d’une approche #Deep_Learning
▻https://makina-corpus.com/blog/metier/2018/qualite-de-lair-a-madrid
Dans cet article nous montrons comme utiliser les bibliothèques stars de l’éco-système scientifique en Python pour analyser des données publiques sur la qualité de l’air à Madrid. Nous verrons comment identifier les problèmes liés à ces données. Puis nous comparerons deux approches en #Machine_Learning : AutoSklearn et les réseaux de neurones de type LSTM.
Joel Simon - Dimensions of dialogue
▻http://joelsimon.net/dimensions-of-dialogue.html
Here, new writing systems are created by challenging two neural networks to communicate information via images. Using the magic of machine learning, the networks attempt to create their own emergent language isolate that is robust to noise.
Les vidéos de la conférence #Information+ 2018 sont en ligne
>> si vous voulez voir et écouter Sandra Rendgen (sur Minard), Sol Kawage (sur al couleur), Jessica Bellamy (sur l’utilisation de la visualisation de données pour le peuple), Fernanda Viégas (sur la visualisation du #machine_learning et de ses biais), Valentina D’Efilippo (sur les cartes du monde tracées de tête), Nadieh Bremer (sur le projet “Bussed Out”), ou encore Catherine D’Ignazio (#data_feminism) … et bien d’autres…
]]>Implant Files - ICIJ
▻https://www.icij.org/investigations/implant-files
Health authorities across the globe have failed to protect millions of patients from poorly tested implants, the first-ever global examination of the medical device industry reveals.
83 000 morts, 1,7 millions de victimes du manque de régulation des prothèses et implants. Méga enquête de l’ICIJ.
]]>Flow
▻https://flow-project.github.io/index.html
▻https://www.youtube.com/watch?v=SoA_7fPJEG8
Modèle de #machine_learning pour #voiture_autopilotée qui permet de montrer qu’un bon programme permet de fluidifier le trafic. Je pensais que ça fluidifiait en « calmant » les à-coups (freinage, accélération), mais quand on regarde la vidéo ça fout les jetons.
]]>La revanche des neurones
L’invention des machines inductives et la controverse de l’intelligence artificielle
Dominique CARDON, Jean-Philippe COINTET Antoine MAZIÈRES
dans la revue Réseaux, 2018/5
The Revenge of Neurons
▻https://neurovenge.antonomase.fr
Résumé
Depuis 2010, les techniques prédictives basées sur l’apprentissage artificiel (machine learning), et plus spécifiquement des réseaux de neurones (deep learning), réalisent des prouesses spectaculaires dans les domaines de la reconnaissance d’image ou de la traduction automatique, sous l’égide du terme d’“Intelligence artificielle”. Or l’appartenance de ces techniques à ce domaine de recherche n’a pas toujours été de soi. Dans l’histoire tumultueuse de l’IA, les techniques d’apprentissage utilisant des réseaux de neurones - que l’on qualifie de “connexionnistes” - ont même longtemps été moquées et ostracisées par le courant dit “symbolique”. Cet article propose de retracer l’histoire de l’Intelligence artificielle au prisme de la tension entre ces deux approches, symbolique et connexionniste. Dans une perspective d’histoire sociale des sciences et des techniques, il s’attache à mettre en évidence la manière dont les chercheurs, s’appuyant sur l’arrivée de données massives et la démultiplication des capacités de calcul, ont entrepris de reformuler le projet de l’IA symbolique en renouant avec l’esprit des machines adaptatives et inductives de l’époque de la #cybernétique.
Mots-clés
#Réseaux_de_neurones, #Intelligence_artificielle, #Connexionnisme, #Système_expert, #Deep_learning
le pdf en français est sur le site ci-dessus, qui met en ligne 2 graphiques et l’abstract
▻https://neurovenge.antonomase.fr/RevancheNeurones_Reseaux.pdf
What-If you could inspect a machine learning model, with no coding required?
▻https://pair-code.github.io/what-if-tool
Building effective machine learning systems means asking a lot of questions. It’s not enough to train a model and walk away. Instead, good practitioners act as detectives, probing to understand their model better.
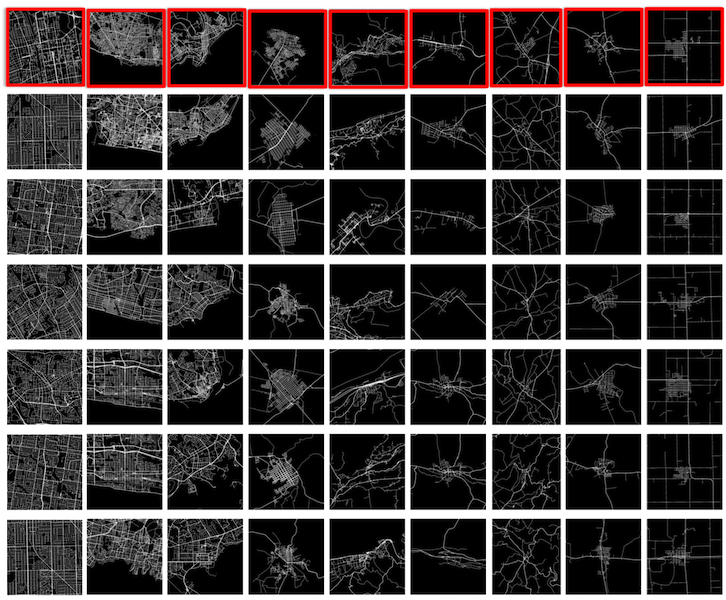
Urban Morphology Meets Deep Learning | cityastext
▻https://sevamoo.github.io/cityastext
Urban morphology is the study of “urban forms” and their underlying formation processes and forces over time. Here, by urban or city form, we mean the combination of street networks, building patterns and their overall layout. Classically, urban morphologist study cities based on few features (usually learned from few famous cities) such as medieval cities (with concentric patterns), industrial cities with grids or highways, ecological cities with polycentric patterns and so on.
How Netflix Reverse Engineered Hollywood
►https://www.theatlantic.com/technology/archive/2014/01/how-netflix-reverse-engineered-hollywood/282679
To understand how people look for movies, the video service created 76,897 micro-genres. We took the genre descriptions, broke them down to their key words, … and built our own new-genre generator. If you use Netflix, you’ve probably wondered about the specific genres that it suggests to you. Some of them just seem so specific that it’s absurd. Emotional Fight-the-System Documentaries ? Period Pieces About Royalty Based on Real Life ? Foreign Satanic Stories from the 1980s ? If Netflix can (...)
Seedbank
►https://tools.google.com/seedbank
We call them “seeds”. Each seed is a #machine_learning example you can start playing with. Explore, learn and grow them into whatever you like.
Capture the Flag: the emergence of complex cooperative agents | DeepMind
▻https://deepmind.com/blog/capture-the-flag
 https://storage.googleapis.com/deepmind-live-cms/images/CTF-BlogAsset-Thumb-180703-r01.width-600.png
https://storage.googleapis.com/deepmind-live-cms/images/CTF-BlogAsset-Thumb-180703-r01.width-600.png through new developments in reinforcement learning, our agents have achieved human-level performance in Quake III Arena Capture the Flag, a complex multi-agent environment and one of the canonical 3D first-person multiplayer games. These agents demonstrate the ability to team up with both artificial agents and human players.
Seedbank
►http://tools.google.com/seedbank
We call them “seeds”. Each seed is a machine learning example you can start playing with. Explore, learn and grow them into whatever you like.
#Deep_Learning et détection d’émotions
▻https://makina-corpus.com/blog/metier/2018/deep-learning-et-detection-demotions
Un premier pas dans le Deep Learning pour la détection d’émotions à partir de photographies.
Formation #Machine_Learning du 23 au 25 mai à Paris
▻https://makina-corpus.com/blog/formation/2018/formation-machine-learning-du-23-au-25-mai-a-paris
Profitez de cette session parisienne pour vous familiariser avec le Machine Learning !
Artificial Intelligence — The Revolution Hasn’t Happened Yet, by Michael Jordan
▻https://medium.com/@mijordan3/artificial-intelligence-the-revolution-hasnt-happened-yet-5e1d5812e1e7
cette anecdote sur les #statistiques :
We didn’t do the amniocentesis, and a healthy girl was born a few months later. But the episode troubled me, particularly after a back-of-the-envelope calculation convinced me that many thousands of people had gotten that diagnosis that same day worldwide, that many of them had opted for amniocentesis, and that a number of babies had died needlessly.
This Startup Is Training AI to Gobble Up the News and Rewrite It Free of Bias
▻https://singularityhub.com/2018/04/16/this-startup-is-training-ai-to-gobble-up-the-news-and-rewrite-it-fre
The company’s hope is that by taking a broad sample of news sources all biased to different extents, they can identify a middle way. They eventually plan to do away with the three versions and simply publish the impartial one.
si je dis que c’est l’idée la plus stupide du moment c’est biaisé ?
]]>