Le sous-préfet chargé de la lutte contre l’immigration clandestine à Mayotte vient de publier 11 demandes d’information réclamant aux industriels un arsenal impressionnant de technologies de #surveillance pour combattre le « défi migratoire » dans ce département de la #France d’outre-mer.
Le 10 février dernier, #Gérald_Darmanin a annoncé qu’ « avec le ministre des Armées, nous mettons en place un "#rideau_de_fer" dans l’eau, qui empêchera le passage des #kwassa-kwassa [des #pirogues légères, qui tanguent énormément, et sont utilisées par les passeurs pour convoyer des migrants d’#Anjouan aux #Comores à Mayotte, ndlr] et des #bateaux, beaucoup plus de moyens d’interception, des #radars, et vous verrez un changement radical ».
Concrètement, ce dispositif consiste en « une nouvelle vague d’#investissements dans des outils technologiques (radars, moyens maritimes…) permettant de déceler et d’interpeller les migrants en mer », précise le ministère de l’Intérieur à France Info.
Il s’agit du prolongement de l’#opération_Shikandra, du nom d’un redouté poisson baliste du lagon qui défend son territoire et se montre extrêmement agressif envers les poissons et tout animal (plongeurs et nageurs inclus) qui traverse sa zone de nidification en période de reproduction.
L’opération Shikandra est quant à elle qualifiée par le ministère d’ « approche globale, civilo-militaire, pour relever durablement le défi migratoire à Mayotte », « qui a permis une première vague d’investissements massifs dans ces outils » depuis son lancement (▻https://www.mayotte.gouv.fr/contenu/telechargement/15319/116719/file/26082019_+DP+Op%C3%A9ration+Shikandra+Mayotte.pdf) en 2019.
Il était alors question de déployer 35 fonctionnaires supplémentaires à la #Police_aux_frontières (#PAF), plus 26 gendarmes départementaux et sept effectifs supplémentaires pour le greffe du TGI de Mamoudzou, mais également d’affecter 22 personnels supplémentaires aux effectifs embarqués dans les unités maritimes, de remplacer les cinq vedettes d’interception vétustes par huit intercepteurs en parfaites conditions opérationnelles (quatre neufs et quatre rénovés).
En décembre dernier, Elisabeth Borne a annoncé le lancement, en 2024, du #plan_interministériel_Shikandra 2, contrat d’engagement financier entre l’État et le département doté de plusieurs centaines de millions d’euros jusqu’en 2027 : « Nous investirons massivement dans la protection des #frontières avec de nouveaux outils de #détection et d’#interception ».
À l’en croire, la mobilisation de « moyens considérables » via la première opération Shikandra aurait déjà porté ses fruits : « Depuis 5 ans, près de 112 000 personnes ont été éloignées du territoire, dont plus de 22 000 depuis le début de l’année ».
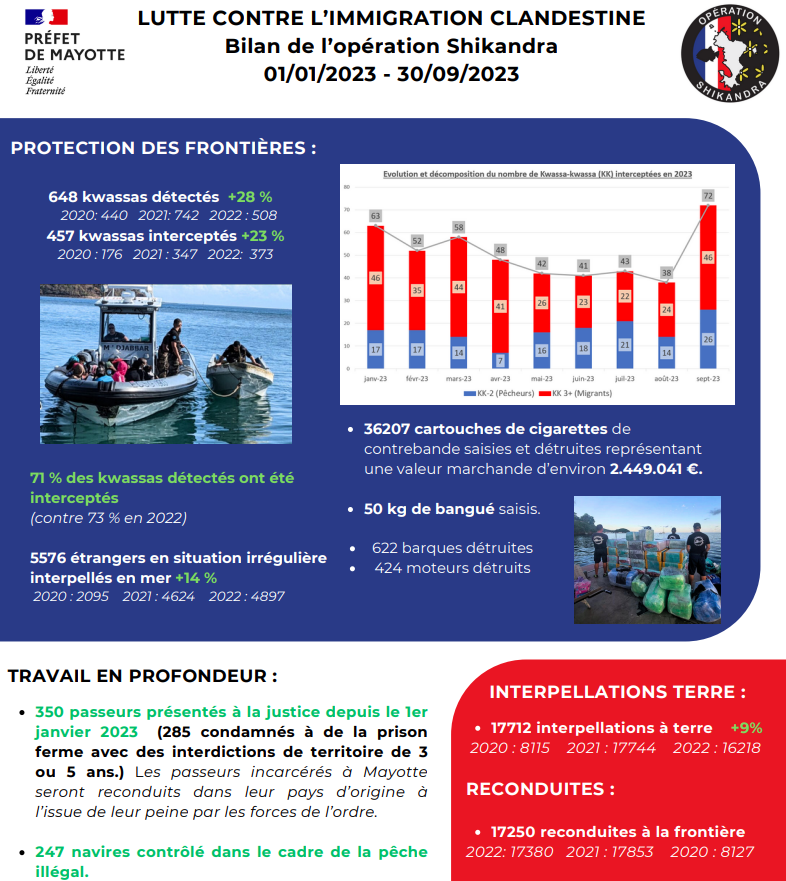
Les derniers chiffres fournis par la préfecture de Mayotte, en octobre 2023, évoquent de leur côté un total de 60 610 reconduites à la frontière (8 127 en 2020, 17 853 en 2021, 17 380 en 2022 et 17 250 en 2023, l’interception de 1 353 kwassa-kwassa, 17 192 étrangers en situation irrégulière interpellés en mer, et 59 789 à terre, la destruction de 622 barques et 424 moteurs, et la condamnation à de la prison ferme de 285 passeurs.