Ce que l’outil fait à la recherche, ou comment j’ai (re)pensé ma thèse avec Zotero
C’était un dimanche soir, un coup de téléphone avec un ami en fin de thèse, en plein dans les dernières étapes de la rédaction.
Je lui demandai combien de chapitres il lui restait encore à rédiger, et il me répondit, le plus naturellement du monde : « Oh, j’ai presque fini en fait, il ne me reste plus que la bibliographie, qui me prendra quelques jours ». J’ai sursauté : « Comment ça, quelques jours ? Je ne comprends pas, ça prend 5 minutes… Tu n’utilises pas de logiciel de gestion bibliographique ? ».
Ben non… ça ne m’est pas vraiment utile en fait, je préfère perdre quelques jours en fin de thèse à mettre la bibliographie en forme plutôt que de m’approprier un nouvel outil qui va marcher une fois sur deux.
C’est alors que je me suis rendue compte que pour beaucoup, Zotero (et ses homologues EndNote et Citavi, mais je ne parlerai que de Zotero ici) n’est justement QUE cela : un outil, certes potentiellement utile, mais surtout compliqué, rébarbatif, bref appartenant à cet univers riche de promesses de gain de temps mais surtout de bugs : le numérique. Ayant découvert par hasard, au moment de la rédaction de cet article, un autre billet très intéressant sur les avantages liés à Zotero, je choisis à dessein de ne présenter que quelques unes des fonctionnalités souvent méconnues de Zotero au-delà de sa capacité première à créer des bibliographies dans tous les styles et toutes les langues en quelques secondes.
Zotero m’a permis de réorganiser mes lectures
J’utilise Zotero depuis le début de ma thèse, mais j’ai longtemps restreint Zotero à n’être qu’un logiciel de gestion bibliographique. Ainsi, j’archivais auparavant mes références en deux sources distinctes : d’un côté Zotero, avec, parfois, le PDF attaché quand l’article était en accès libre au moment de la récupération des métadonnées, de l’autre, les dossiers (folders) sur mon ordinateur, où étaient archivés tous les articles et mes fiches correspondantes.
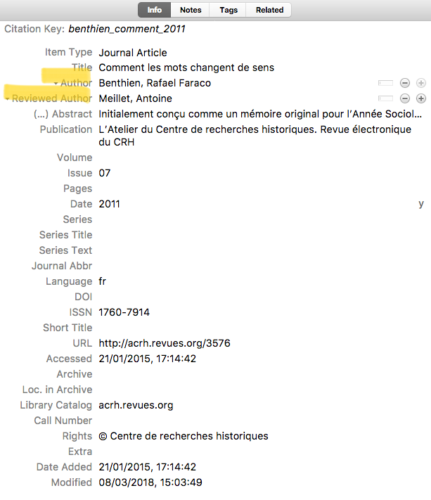
Mais avec ce système ce sont posées très tôt des questions liées aux noms à donner aux documents : certes, le format « auteur·e – date – titre » semble assez logique, mais que faire des recensions d’ouvrage, par exemple ? Faut-il les renommer en fonction de la personne qui fait la recension, quitte à ne jamais remettre la main dessus lorsque l’on recherche la référence, ou en fonction de la personne dont l’ouvrage est recensé ? Zotero répond par exemple très facilement à cette interrogation en permettant de combiner les variables auteur·e et auteur·e recensé·e dans les métadonnées (voir capture d’écran 1) ou encore en permettant de lier deux références connexes (voir capture d’écran 2).
Parallèlement, je me suis très vite rendue compte que mes besoins de classement évoluaient au fil de la thèse : alors que j’avais classé certains articles dans tel dossier A ou B au début de mes recherches, je n’étais plus en accord avec cette grille de lecture quelques mois plus tard. Réorganiser mes dossiers sur mon ordinateur à chaque fois, ou chercher en vain un article dans la mauvaise catégorie sont des problèmes que là aussi, Zotero résout aisément, à la fois grâce à un système de tags, qui permet d’affecter des mots clefs à chaque référence, mais aussi parce qu’une même référence peut se trouver dans plusieurs dossiers à la fois [1].
Ainsi, les références liées à un enseignement peuvent être regroupées dans un dossier spécial, lié à ce cours (en jaune sur la capture d’écran 3), mais être situées en même temps dans d’autres dossiers thématiques (en rouge).
Cela est beaucoup plus utile qu’il n’y paraît : lorsqu’il s’agit de dresser un rapide état de l’art d’un concept, aller directement dans tel ou tel dossier fait gagner un temps fou. Cela permet également de se remémorer des références oubliées, qui auront été archivées à plusieurs endroits stratégiques. Il est alors enfantin (un simple clic) de rajouter une référence à un dossier ou au contraire de la retirer d’un dossier s’il se trouve, après (re)lecture, que l’article en question ne traite en fait pas du domaine dans lequel il avait classé initialement (voir capture d’écran 4).
Zotero m’a permis d’annoter mes lectures
La véritable découverte a toutefois été Zotfile, un outil de gestion des PDF. Alors que, durant mes deux premières années de thèse, j’annotais mes lectures à la main et me suis ainsi retrouvée avec des classeurs entiers de notes, j’ai pris la décision, en janvier 2016, de passer au numérique. Cela faisait certes partie de mes bonnes résolutions, mais s’était surtout révélé une nécessité quand, lors de mon séjour de recherche à Oxford à l’hiver 2015, j’avais cruellement manqué de mes articles minutieusement annotés laissés à Berlin. J’ai alors commencé à lire les PDF de mes articles sur ma tablette, et bien que fervente du papier au début, j’ai vite été conquise : les annotations étaient plus propres, plus rapides, et je pouvais facilement retrouver un mot-clef ou un passage en parcourant plusieurs textes à la fois. Comme le dit très justement Caroline Muller dans le billet que je citais en introduction :
En sus de ce côté pratique, j’ai pris conscience en écrivant ma thèse que Zotero m’aidait à mieux explorer mon corpus : le moteur de recherche fouille à la fois les titres des références mais aussi toutes les notes et PDF intégrés. Cela fait « ressortir » des références auxquelles je ne pensais plus, ou encore crée des associations d’idées inattendues.
J’ai donc très vite été convaincue que le passage au numérique, loin de simplement alléger mes valises et mes craintes de ne pas avoir avec moi les références dont j’avais besoin à un moment précis, allait modifier mon rapport à la lecture. Mais les usages de Zotero vont au-delà de l’association de la prise de notes avec le fichier source.
Au lieu des fiches que je constituais jusqu’alors, souvent en copiant-collant les citations essentielles d’un article, je me suis rendue compte qu’une simple annotation au cours de la lecture (donc surligner directement dans le texte) permettait d’extraire les citations, directement suivies de la référence. Oui oui, vous avez bien lu : Zotfile vous crée automatiquement vos fiches de lecture personnalisées. Cela ressemble à ça :
A partir des passages surlignés, Zotfile compose une note associée à la référence. Quels avantages ? Ils sont multiples :
Zotfile archive deux versions de votre fichier – une version non annotée, que vous pourrez ensuite diffuser (par exemple pour vos cours), et une version annotée (voir capture d’écran 6).
– Zotfile indique la date à laquelle ont été prises les notes, ce qui permet de se souvenir ensuite de la période dans ses recherches à laquelle on a découvert une référence et donc, si nécessaire, de réévaluer a posteriori si la référence doit être relue, réinterprétée au regard de nouvelles données ou lectures, etc.
– Zotfile indique déjà la page de la référence et met en forme auteur·e, date et page. En cliquant sur les liens en bleus (voir capture d’écran 5), on arrive ainsi directement au passage du texte correspondant [2].
– Zotfile distingue les annotations issues des passages surlignés lors de la lecture et les notes ajoutées sous forme de bulles dans le logiciel d’annotation PDF (je suis pour ma part très satisfaite de Xodo). Ainsi les annotations issues du surlignage dans le texte seront comme sur la capture d’écran 5 tandis que mes propres notes seront en italique, à l’endroit du texte où la bulle de texte a été insérée.
– Zotfile permet de renommer automatiquement les documents à partir d’une règle que l’on a soi-même créée (voir capture d’écran 7). Ainsi, si on se rend compte en cours de route que l’on veut souhaite modifier son système d’archivage, on peut modifier tous les titres des documents associés aux références d’un simple clic (voir capture d’écran 8). Cela permet également, lorsque l’on « ressort » une référence de Zotero (par exemple, pour la partager pour un cours), que tous les titres des fichiers suivent strictement la même logique.
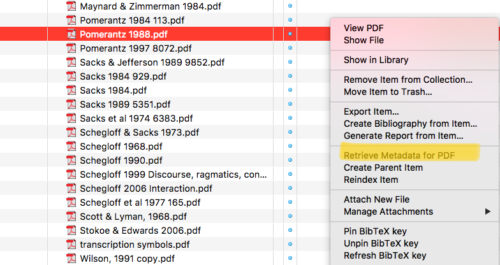
Zotfile permet de retrouver automatiquement les données associées à un PDF (à condition qu’il ne s’agisse pas d’un scan non océrisé). Il suffit ainsi de « jeter » (drag and drop) un PDF dans Zotero, puis, par un simple clic-droit, la fiche correspondante à la référence est créée (voir capture d’écran 9). Bien utile quand on a téléchargé d’un coup une dizaine d’articles, par exemple.
Zotfile extrait automatiquement la table des matières des articles ou ouvrages ajoutés en PDF ; ainsi, il est possible d’avoir un aperçu rapide d’un ouvrage puis d’accéder directement à la bonne page en cliquant sur le lien (en bleu sur la capture d’écran 10).
Il ne s’agit pour le moment que d’un simple panorama. Mais les fonctionnalités que permettent d’expérimenter Zotero (en libre accès, faut-il le rappeler) sont vertigineuses. Loin de n’être qu’un support technique, Zotero a véritablement modifié en profondeur mon rapport à la bibliographie. Il m’a permis de m’approprier mes lectures différemment et m’aide considérablement lors de la rédaction ou de la préparation d’un nouveau cours. Ainsi, bien plus qu’un simple « outil », Zotero (et le plug-in associé Zotfile) s’est révélé au fur et à mesure de ma thèse un système d’archivage, de classement, de repérage de mots-clefs, et d’annotation de mes documents.
J’espère vous avoir convaincu·e que la demi-journée passée à rentrer toutes vos références dans Zotero est une demi-journée bien utilisée. Je me réjouis de lire vos commentaires, suggestions et questions, et peut-être de découvrir de nouvelles fonctionnalités de Zotero insoupçonnées !
[1] Cela permet également de gagner de la place sur son disque dur. Avant de stocker mes références et mes fichiers dans Zotero, j’avais pris la mauvaise habitude copier-coller les articles en PDF dans plusieurs dossiers pour pouvoir les retrouver quel que soit mon point d’entrée. J’avais donc plusieurs versions du même fichier.
[2] Attention, il peut arriver (mais c’est rare) que les pages indiquées soient celles du PDF (par exemple pages 1 à 22) et non celles de l’article en question (par exemple page 210 à 232). Cela se produit normalement seulement si l’on a extrait un chapitre d’un ouvrage en PDF, par exemple.
Références :
– Cinq ans d’usage de Zotero, un bilan, par Caroline Muller : ►https://consciences.hypotheses.org/1184
– 12 must know Zotero tips and techniques, par Mark Dingemanse : ▻http://ideophone.org/12-zotero-tips-and-techniques
▻https://icietla.hypotheses.org/70