-
-

Various Optimisation Techniques and their Impact on Generation of Word Embeddings
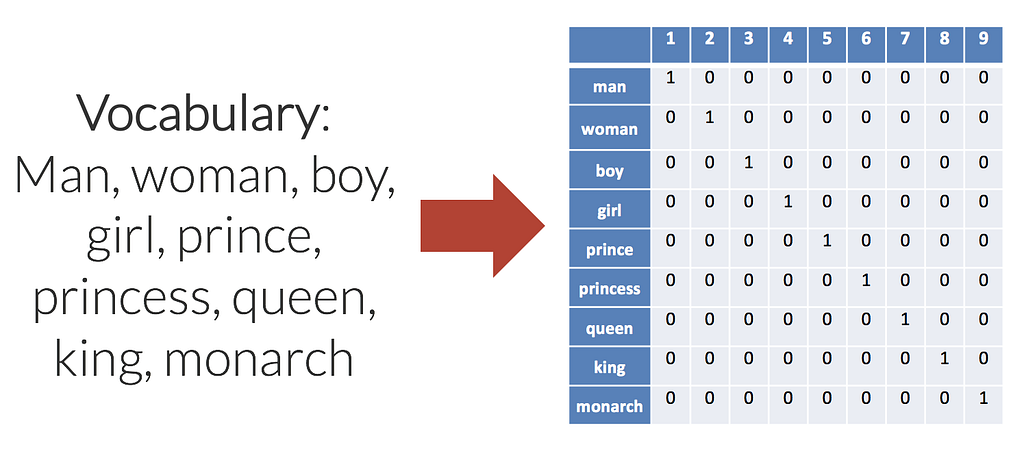
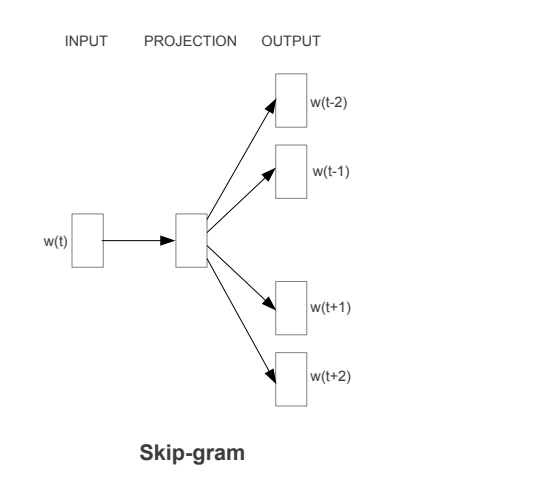
▻https://hackernoon.com/various-optimisation-techniques-and-their-impact-on-generation-of-word-eShameless plugin: We are a machine learning data annotation platform to make it super easy for you to build ML datasets. Just upload data, invite your team and build datasets super quick.Welcome to the third part of the five series tutorials on Machine Learning and its applications. Check out Dataturks, a data annotations tool to make your ML life simpler and smoother.Word embeddings are vectorial representations that are assigned to words, that have similar contextual usages. What is the use of word embeddings you might say? Well, if I am talking about Messi and immediately know that the context is football… How is it that happened? Our brains have associative memories and we associate Messi with football…To achieve the same, that is group similar words, we use embeddings. Embeddings, (...)
#word2vec #nlp #word-embeddings #text-mining #machine-learning
-
Understanding Word Embeddings
▻https://hackernoon.com/understanding-word-embeddings-a9ff830403ce?source=rss----3a8144eabfe3---Understanding how different words are related based on the context they are used is an easy task for us humans. If we take an example of articles then we read a lot of articles related to different topics. In almost all the articles where an author is trying to teach you a new concept then the author will try to use the examples which are already known to you, to teach you any new concept. In a similar way computer also needs a way where they can learn about a topic and where they can understand how different words are related.Let me begin with the concept of language, these amazing different languages we have. We use that to communicate with each other and share different ideas.But how do we explain a language in a better way? Some time back I was reading this book “Sapiens”, where the (...)
-

Sentiment analysis on Twitter using word2vec and keras - Ahmed Besbes
▻http://ahmedbesbes.com/sentiment-analysis-on-twitter-using-word2vec-and-keras.html -
Chris Harrison | WordAssociations
▻http://www.chrisharrison.net/index.php/Visualizations/WordAssociationsoù l’on voit que l’#intelligence_artificielle reproduit les #stéréotypes (dans le schéma dumb—smart, le mot blond est très en évidence)
▻http://p.migdal.pl/2017/01/06/king-man-woman-queen-why.html
-
transorthogonal-linguistics
▻https://transorthogonal-linguistics.herokuapp.comessayer avec “sociology” + “mathematics” puis comparer avec xkcd: #Purity
▻https://xkcd.com/435 -

Comment Google traduit les images en mots - Technology Review
▻http://alireailleurs.tumblr.com/post/104317135157Les ingénieurs de Google ont mis au point un algorithme auto-apprenant capable de décrire et légender des images, en utilisant les mêmes techniques que celles qu’ils utilisent pour #Google_translate, rapportent la Technology Review et Google Research. L’approche classique de la traduction est un processus itératif qui commence par traduire les mots individuellement puis les réorganise pour l’améliorer. L’approche de Google est différente. Ils comptent le nombre de fois ou les mots apparaissent les uns à côté des autres ou à proximité pour définir des espaces vectoriels et les représente par des combinaisons de vecteurs. Google fait là une hypothèse importante : les mots spécifiques ont une même relation indépendamment de la langue. Par exemple, le vecteur “roi-homme+femme=reine” devrait être vrai dans toutes (...)
-
This Grad Student Hacked Semantic Search To Be Better Than Google ⚙ Co.Labs ⚙ code + community
▻http://www.fastcolabs.com/3021763/this-grad-student-hacked-semantic-search-to-be-better-than-google?partneTHisPlusThat.me est-il un moteur de recherche qui permet de chercher des choses qu’on ne sait pas qu’elles existent ? ▻http://www.thisplusthat.me Tags : internetactu fing internetactu2net #web_semantique #moteurderecherche
-
ok alors j’allais juste dire que l’algo #word2vec est intégré dans #gensim (outil de #text_mining). Mais en cherchant une source, je m’aperçois que c’est beaucoup plus intéressant que ça : Radim (l’auteur de gensim) a complètement réécrit word2vec en python, et explique ici comment ça fonctionne et tout :
▻http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensimAvec des exemples frappants :
# which word doesn’t go with the others?
model.doesnt_match("breakfast cereal dinner lunch".split())
’cereal’This already beats the English of some of my friends :-)
-