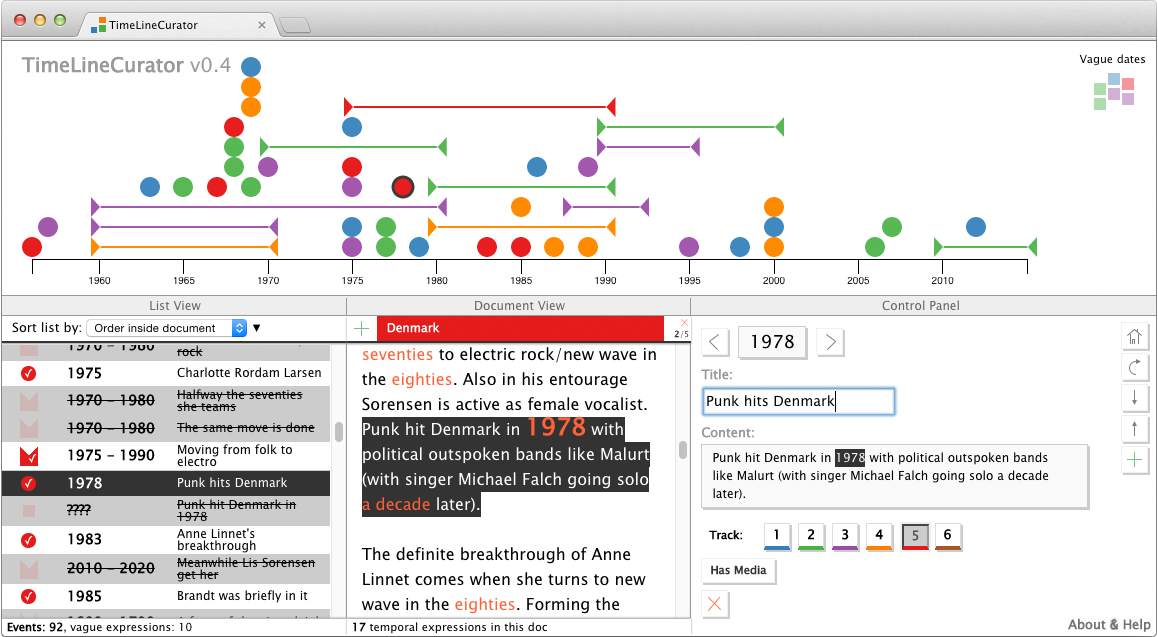
A tool that automatically extracts event data from temporal references in unstructured text documents and encodes them along a visual #timeline
▻http://www.cs.ubc.ca/labs/imager/tr/2015/TimeLineCurator #curation #indexation
A tool that automatically extracts event data from temporal references in unstructured text documents and encodes them along a visual #timeline
▻http://www.cs.ubc.ca/labs/imager/tr/2015/TimeLineCurator #curation #indexation

▻https://mtmx.github.io/blog/paroles_chansonfr
Grâce à l’implémentation de nouvelles méthodes et à leur vulgarisation notamment par le biais de #R et de sa communauté (on notera le beau travail de Julia Silge et David Robinson développeurs du package ‘tidytext’ utilisé pour ce papier), l’#analyse_textuelle est en vogue. On peut l’appliquer à des documents littéraires mais ici on va tester ce panel d’analyses sur des paroles de chansons, en l’occurrence celles des poids lourds de la #chanson_française.
youpi.

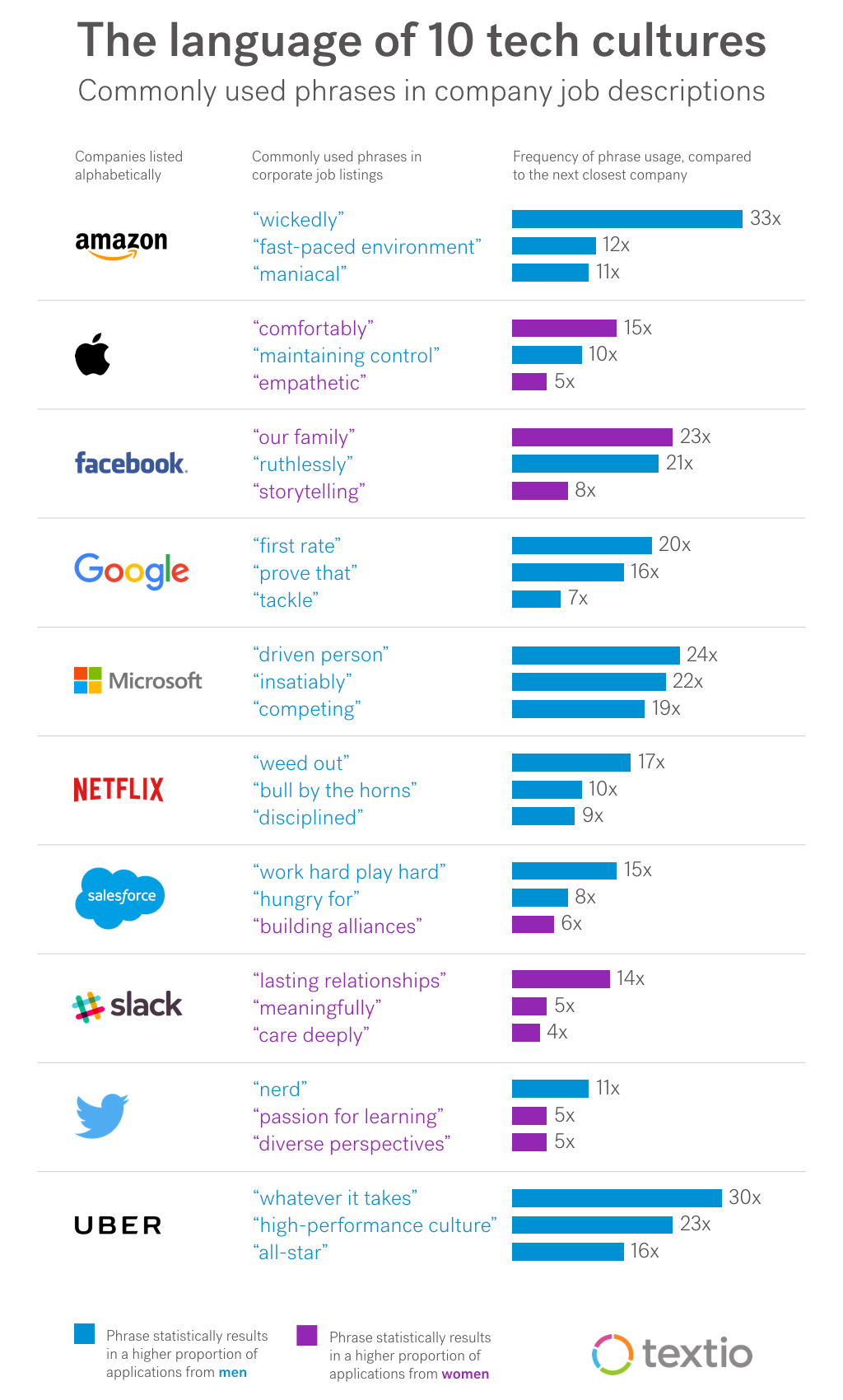
1000 different people, the same words – Textio Word Nerd
▻https://textio.ai/1000-different-people-the-same-words-6149b5a1f351
In this sample, Textio analyzed 25,060 jobs published over the last year by Amazon, Apple, Facebook, Google, Microsoft, Netflix, Salesforce, Slack, Twitter, and Uber.

On voie que chez Uber,Netflix, Amazone, Google et Microsoft il y a pas de femmes du tout et que pour Slack pas d’hommes.
#genre
Encartopedia
▻http://encartopedia.fastforwardlabs.com
▻http://blog.fastforwardlabs.com/2017/08/15/encartopedia.html
I used #machine_learning techniques and #visualization to explore new navigation possibilities for Wikipedia while preserving its hypertextual feel. With Encartopedia, you can map the path of any journey through Wikipedia, or use the visualization to jump to articles near and far.
#text_mining #proximité #cartographie_de_n'importe_quoi #hypertexte
(assez proche de ce que je fais avec #tSNE)
De-Jargonizer
▻http://scienceandpublic.com
How accessible is your work? Paste your article or upload a file to analyze the amount of jargon in your writing.
#jargon #text_mining (English and Hebrew only)

Bonne analyse quantitative de la radicalisation politique mesurée par une analyse automatique de tweets
▻https://medium.com/@jonathonmorgan/the-radical-right-and-the-threat-of-violence-f66288ac8c4
#textreuse: This #R package provides a set of functions for measuring #similarity among documents and detecting passages which have been reused. It implements shingled #n-gram, skip n-gram, and other tokenizers; similarity/dissimilarity functions; pairwise comparisons; and minhash and locality sensitive hashing algorithms.
▻https://github.com/lmullen/textreuse
#text_mining

History As Big Data: 500 Years Of Book Images And Mapping Millions Of Books - Forbes
▻http://www.forbes.com/sites/kalevleetaru/2015/09/16/history-as-big-data-500-years-of-book-images-and-mapping-millions-of-books
 http://blogs-images.forbes.com/kalevleetaru/files/2015/09/cover-image-telephonetelepho00kinguoft-22.jpg
http://blogs-images.forbes.com/kalevleetaru/files/2015/09/cover-image-telephonetelepho00kinguoft-22.jpg 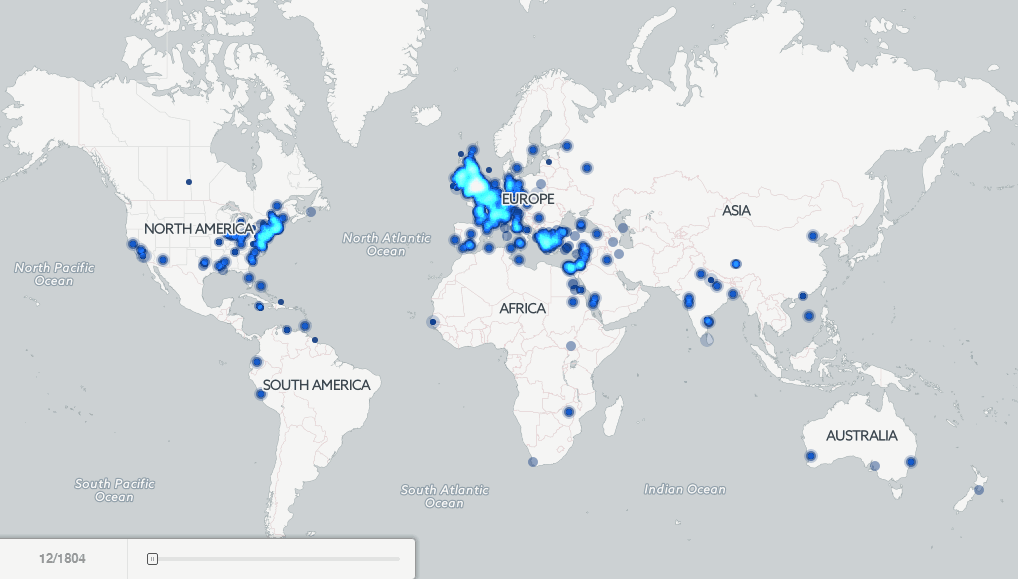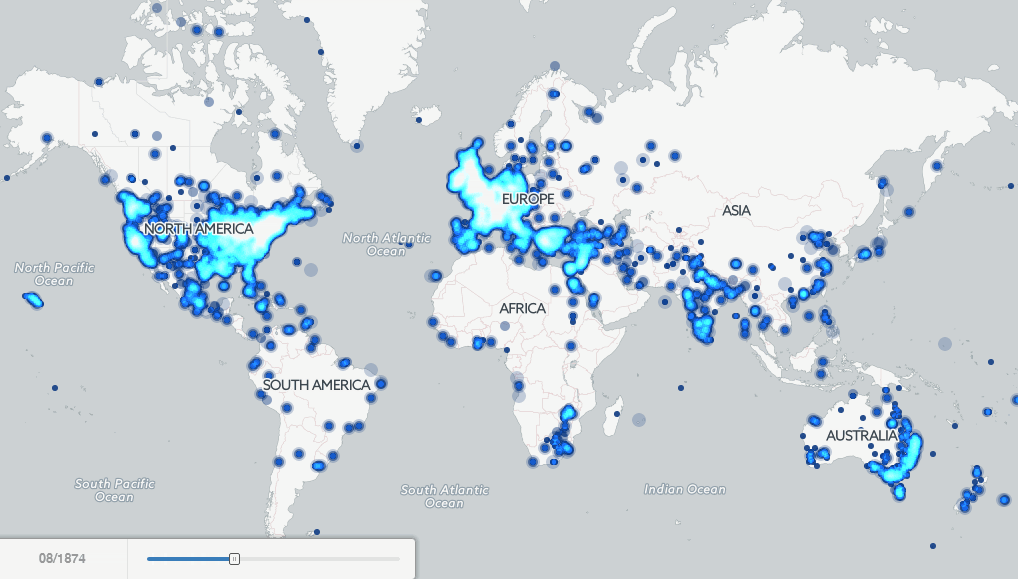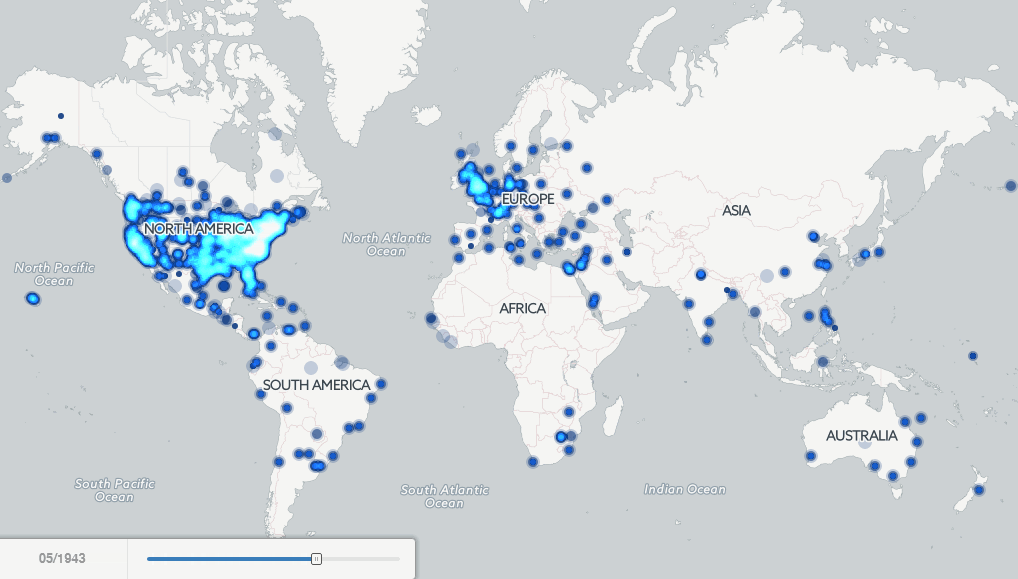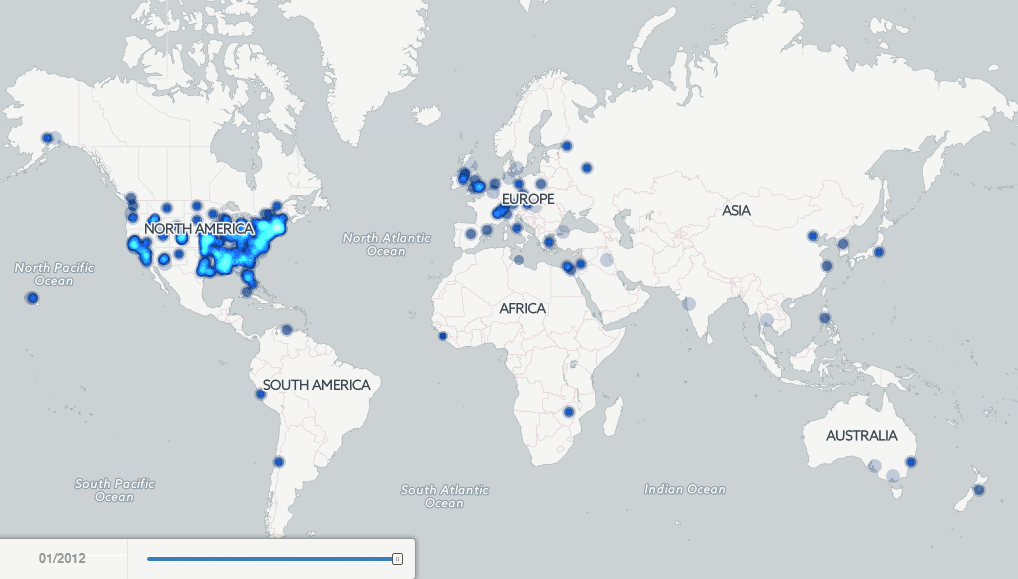 http://data.gdeltproject.org/blog/bookmaps-215years-ia-ht/InternetArchive1800-Present-FINAL.gif
http://data.gdeltproject.org/blog/bookmaps-215years-ia-ht/InternetArchive1800-Present-FINAL.gif The terms “big data” and “massive data analytics” likely conjure thoughts of the modern world, of hundreds of millions of tweets or billions of Facebook FB +2.17% posts streaming in real time into gleaming data centers filled with blinking lights. Libraries, on the other hand, filled with endless rows of dusty books, are likely not the first thing that comes to mind. Yet, what if we could use libraries to reimagine our past, creating a gallery of all the images from half a millennium of books or creating a 215-year animated map of human history as seen through millions of books?
je trouve ça absolument fascinant (par l’auteur de #GDELT)
#géolocalisation #histoire #text_mining #google_bigquery
à noter, l’impact du #copyright qui provoque une chute du nombre de livres analysés à partir de 1922
la base extraite est disponible en accès libre
▻http://blog.gdeltproject.org/3-5-million-books-1800-2015-gdelt-processes-internet-archive-and-
avec des exemples qui permettent de voir coment en quelques secondes faire une carte traitant d’une recherche particulière
▻http://blog.gdeltproject.org/google-bigquery-3-5m-books-sample-queries
#Google Acquires Artificial Intelligence Startup #DeepMind For More Than $500M | TechCrunch
▻http://techcrunch.com/2014/01/26/google-deepmind
DeepMind was founded by neuroscientist Demis Hassabis, a former child prodigy in chess, Skype and Kazaa developer Jaan Tallin, and researcher Shane Legg.
This is the latest move by Google to fill out its roster of artificial intelligence experts (...) Ray Kurzweil, who was hired in 2012 as a director of engineering focused on machine learning and language processing.
Kurzweil has said that he wants to build a search engine so advanced that it could act like a “cybernetic friend.”
voir aussi ▻http://recode.net/2014/01/26/exclusive-google-to-buy-artificial-intelligence-startup-deepmind-for-400m

How to tag all your audio files in the fastest possible way - TechRepublic
▻http://www.techrepublic.com/blog/linux-and-open-source/how-to-tag-all-your-audio-files-in-the-fastest-possible-way/3444
Marco Fioretti shows you his method for tagging MP3 files with as much automation as possible so that you can impose a little order on music or other audio collections.
1. À la souris, avec l’appli graphique MuzicBrains Picard, qui excelle à taguer massivement les morceaux populaires (#musique) aux formats #mp3, #ogg (autres ?)
- Voir les options pour renommer fichiers (et dossiers) dans une base « propre » par exemple, récupérer les covers...
- Pour compléter les indications de Marco : le principe est de ~tout avoir à droite. Donc une fois la colonne de droite remplie, « rechercher » et « analyser » les albums « regroupés » dans la colonne gauche pour les ajouter à droite.
Un 2è passage (réouvrir le même dossier où qlqs morceaux de musique restaient non reconnus) rend souvent service.
Avant d’enregistrer : passer en revue les titres en rouge et orange (possible missmatches !)
2. En mode console avec un petit script, qui va renommer N fichiers à partirs de leurs #tags #id3
Très utile pour taguer (après renommage) une collection de #podcasts et autres enregistrements #audio.
Sur certaines distributions Linux c’est id3lib (package) qui procure id3info.
Help ! vos conseils sont bienvenus pour les tags ici ; je n’ai trouvé que peu de références en matière de #SGI / #SGD (gestion des données).
#classement #fichiers #métadonnées #data_mining #text_mining #audio
#format_ouvert #portabilité_des_données sauvegarde #conservation_des_données #accès_aux_données
#tutoriel
Si vous taguez / renommez des fichiers en alphabets non latins, vérifiez que « Remplacer les caractères non ASCII » est décoché en option ;-) #i18n


Comment Netflix procède à une rétro-ingénierie d’Hollywood - The Atlantic
►http://www.theatlantic.com/technology/archive/2014/01/how-netflix-reverse-engineered-hollywood/282679
Pour comprendre comment ses 40 millions de clients regardent des films, Netflix a créé quelques 80 000 catégories pour décrire les genres de films qu’il propose. Netflix paye des gens pour cataloguer les films, évaluant jusqu’au statut moral des personnages. Combinés aux profils des clients, ces taxonomie devient l’avantage concurrentiel permettant de fidéliser les abonnés. C’est cette base de donnée sans précédent qui leur a permis de faire les choix président au succès de leur série House of Cards. Tags : internetactu internetactu2net fing #économie (...)


One day Facebook will adopt the same reductionist approach and classify us all, and then use these classifications to make educated suggestions “perhaps you (THX1138) would like to mate with Pamela (LUH3417) ?”.
Of course the NSA already has developed such a tool (called FLYPAPERPEELER) to identify terrorists who don’t know yet they are terrorists.
The vexing, remarkable conclusion is that when companies combine human intelligence and machine intelligence, some things happen that we cannot understand.
“Let me get philosophical for a minute. In a human world, life is made interesting by serendipity,” Yellin told me. “The more complexity you add to a machine world, you’re adding serendipity that you couldn’t imagine. Perry Mason is going to happen. These ghosts in the machine are always going to be a by-product of the complexity. And sometimes we call it a bug and sometimes we call it a feature.”
ohyes.
They capture dozens of different movie attributes. They even rate the moral status of characters. When these tags are combined with millions of users viewing habits, they become Netflix’s competitive advantage. The company’s main goal as a business is to gain and retain subscribers. And the genres that it displays to people are a key part of that strategy. “Members connect with these [genre] rows so well that we measure an increase in member retention by placing the most tailored rows higher on the page instead of lower,” the company revealed in a 2012 blog post. The better Netflix shows that it knows you, the likelier you are to stick around.
And now, they have a terrific advantage in their efforts to produce their own content: Netflix has created a database of American cinematic predilections. The data can’t tell them how to make a TV show, but it can tell them what they should be making. When they create a show like House of Cards, they aren’t guessing at what people want.
►https://www.theatlantic.com/technology/archive/2014/01/how-netflix-reverse-engineered-hollywood/282679
British headlines: 18% <del>less informative</del> shorter
▻http://languagelog.ldc.upenn.edu/nll/?p=8737
#presse #text_mining #R via @francoisbriatte
This Grad Student Hacked Semantic Search To Be Better Than Google ⚙ Co.Labs ⚙ code + community
▻http://www.fastcolabs.com/3021763/this-grad-student-hacked-semantic-search-to-be-better-than-google?partne
THisPlusThat.me est-il un moteur de recherche qui permet de chercher des choses qu’on ne sait pas qu’elles existent ? ▻http://www.thisplusthat.me Tags : internetactu fing internetactu2net #web_semantique #moteurderecherche
ok alors j’allais juste dire que l’algo #word2vec est intégré dans #gensim (outil de #text_mining). Mais en cherchant une source, je m’aperçois que c’est beaucoup plus intéressant que ça : Radim (l’auteur de gensim) a complètement réécrit word2vec en python, et explique ici comment ça fonctionne et tout :
▻http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim
Avec des exemples frappants :
# which word doesn’t go with the others?
model.doesnt_match("breakfast cereal dinner lunch".split())
’cereal’
This already beats the English of some of my friends :-)
Textteaser : Automatic Summarization
▻https://medium.com/look-what-i-made/8358da843383
TextTeaser is an automatic summarization API based on the algorithm I formulated in my MS CS degree. The algorithm does extraction which extracts the most important sentences on an article. I tried it on Medium to see if it really works well. It exceeds my expectations.
TextTeaser : An automatic summarization application and #API
▻http://www.textteaser.com
TextTeaser uses a special algorithm formulated through research to summarize articles.
code source
▻https://github.com/MojoJolo/textteaser
Exemple sur un article en français
▻http://www.textteaser.com/s/95VSVf
un autre ici, qui a la gentillesse de faire une liste de plein d’outils et d’algorithmes de résumé :
►https://github.com/miso-belica/sumy
A Rather Nosy Topic Model Analysis of the Enron Email Corpus | Data and Analysis with R, for Work and Fun
▻http://rforwork.info/2013/11/03/a-rather-nosy-topic-model-analysis-of-the-enron-email-corpus
Having only ever played with Latent Dirichlet Allocation using gensim in python, I was very interested to see a nice example of this kind of topic modelling in R. Whenever I see a really cool analysis done, I get the urge to do it myself. What better corpus to do topic modelling on than the Enron email dataset?!?!? Let me tell you, this thing is a monster!
#text_mining en #R (pas très concluant) via @francoisbriatte

Offshore secrets: unravelling a complex package of data | UK news | The Guardian
▻http://www.guardian.co.uk/uk/2013/apr/04/offshore-secrets-data-emails-icij
Analysing the immense quantity of information required “free text retrieval” software, which can work with huge volumes of unsorted data. Such high-end systems have been sold for more than a decade to intelligence agencies, law firms and commercial corporations. Journalism is just catching up.

#Fraude fiscale : Les #banques ont de plus en plus recours au « #text_mining » - Économie - lematin.ch
▻http://www.lematin.ch/economie/Les-banques-ont-de-plus-en-plus-recours-au-text-mining/story/21724453
Pour détecter les fraudeurs, de nombreuses banques examinent les courriels de leurs collaborateurs au gré des mots et des termes suspects. L’intérêt de la pratique augmente, en particulier depuis les récents scandales mis au jour dans la finance.
« Nous le comptabilisons comme amortissement » ou « A mon avis, c’est déjà réglé », les employés de banque ayant déjà écrit de telles phrases dans leurs e-mails peuvent s’avérer suspects. Même en parlant discrètement de « commissions » ou d’« honoraires », un collaborateur peut entrer dans le viseur de contrôles internes et potentiellement être démasqué.
(…)
Mais les fripouilles ne se rabattent-elles tout simplement pas sur d’autres canaux, si elles savent que leurs e-mails sont passés au peigne fin ? C’est possible, concède Michael Faske, notant toutefois que le cas n’a pas été observé fréquemment jusqu’à présent. « D’après notre expérience, les fraudeurs sont relativement imprudents s’agissant de leurs e-mails. » Souvent, ils n’ont pas même connaissance des contrôles, ajoute l’expert.
De son avis, le « text mining » est utilisé avant tout dans les établissements anglo-saxons. Mais, en Suisse aussi, nombre de banques y ont recours, selon des initiés. Les instituts se gardent, du reste, d’informations publiques.
Selon le Préposé fédéral à la protection des données et à la transparence (PFPDT), le « text mining » en Suisse est autorisé sous réserve de conditions précises. Les employés doivent être informés et avoir accepté que leurs données sont parcourues.
J’aime bien : "en Suisse (comme en France) pour être légales ces techniques doivent être déclarées aux salariés", mais "les fripouilles n’ont même pas connaissance des contrôles"…
Et pour les manipulations du Libor, je doute que le text mining aurait (a ?) apporté quelques choses, puisqu’a priori tout le monde savait…
#passager_clandestin qui s’était mis à twitter à tout va via IFTTT du fait d’un changement dans les flux rss des tags #seenthis n’est-ce pas (?)


C’est quoi ce tag @thibnton ?

Comment le gouvernement #écoute ce qui se dit sur #Twitter
►http://www.challenges.fr/internet/20121123.CHA3487/comment-le-gouvernement-ecoute-ce-qui-se-dit-sur-twitter-grace-la-technol #surveillance
L’analyse de l’évolution de l’opinion publique ne passe plus seulement par les sondages. Le SIG, qui est en charge de cette mission pour Matignon, scrute aussi ce qui se dit sur les réseaux sociaux.
Visibrain facilite la veille personnelle et concurrentielle sur Twitter | L’Atelier
►http://www.atelier.net/trends/articles/visibrain-facilite-veille-personnelle-concurrentielle-twitter
Depuis quelques années le ministère de la défense emploie aussi Spintank, la start-up de Nicolas Vanbremeersch (@versac), pour (entre autres) « écouter » ce que les internautes pensent de la guerre en Afghanistan, « conseiller » le ministère sur l’usage des réseaux sociaux dans l’armée, « accompagner » le ministère dans sa communication auprès des jeunes, etc.
►http://www.spintank.fr/category/1
Researchers mine 2.5M news articles to prove what we already know — Data | GigaOM
►http://gigaom.com/data/researchers-mine-2-5m-news-articles-to-prove-what-we-already-know
A group of British researchers recently analyzed 2.5 million newspaper articles in order to prove that new data analysis techniques, such as machine learning and natural-language processing, can accurately classify media content.

Hollande au mot près | Sylvain Lapoix
►http://owni.fr/2012/01/23/hollande-au-mot-pres
Ses outils d’analyse sémantique ouverts en onglet, OWNI a scruté le discours du Bourget de François Hollande pour y déchiffrer le nouvel ego du candidat socialiste, ses inspirations jospiniennes et sarkozystes... et le vrai objectif d’un discours faussement programmatique.
#Data #Politique #Pouvoirs #françois_hollande #meeting_du_Bourget #Nicolas_Sarkozy #présidentielle_2012 #text_mining #verbe_en_campagne
Le verbe en campagne | Claire Berthelemy et Dominique Sorbier
►http://owni.fr/2011/12/15/le-verbe-en-campagne
Avec la course à la présidence entamée, chacun des politiques engagés y va de son #discours. OWNI découpe et analyse la prose des #candidats. Et si les mots avaient un sens. Premier épisode avec François Hollande.
#Cultures_numériques #Data #data #françois_hollande #présidentielle_2012 #text_mining