#Time-series #forecasting is becoming a lost art.
It’s the engine behind the $5,000,000,000,000 retail industry in the US.
And yet, research progress is slow and the best tricks are locked away.
But why is it particularly tough even in the current AI breakthrough?
Here’s why 🧵
Forecasting is a seemingly straightforward task.
In fact, given all the success we’ve had with LLMs, it’s weird that we can’t use the exact same tricks with time-series data.
So why don’t 175B parameter models work, and why can’t we do the classic LM + transfer learning recipe?
Well, for starters, we kinda do the same thing.
Given a sequence of historical data points, we train the model to predict the next one (or maybe the next 10, or maybe the single value 7 observations from now).
So is it a data problem?
Well, probably not from a dataset size perspective.
While there’s no equivalent of “the entire internet’s worth of text” for time-series data, there are still enormous datasets.
Any large retailer will have datasets with potentially hundreds of billions of data points.
Despite that, there haven’t been any convincing papers on transfer learning.
It certainly could be that not enough of these datasets are publicly available.
But, from my experience, even the largest datasets don’t necessitate anything beyond a pretty shallow transformer.
On top of that, XGBoost is crazy effective in a way that it just isn’t for NLP problems.
(I have some great material on this. Link at the end.)
My best guess is that it has to do with the complexity of the underlying representation.
In simple english:
Words really difficult to represent.
Depending on the context, they can mean entirely different things. Wouldn’t it be nice if you really could represent things in a static way like in this image?
You just can’t. But, in time-series problems, you kinda can.
In fact, methods like STUMPY exist for this.
Unlike the deep, 768/1536-dimensional embedding representations you need in NLP, “matrix profile” methods like STUMPY are pretty low-dimensional.
In other words: simpler models for simpler representations.
Now, the practicalities:
XGBoost is amazing for this because it’s much more capable of learning these types of representations.
99% of the feature engineering you do in NLP nowadays is just tokenization.
In contrast, time-series models benefit a lot from feature engineering.
Here’s how:
Time series data has a couple types of patterns. I usually think of them in 3 buckets:
1. Seasonality
These are short-term, repeating patterns. Think of this like day of week effects, month of the year effects, etc.
2. Trends (cont)
Your data is either “trending” up, down, or not at all. Simple as that.
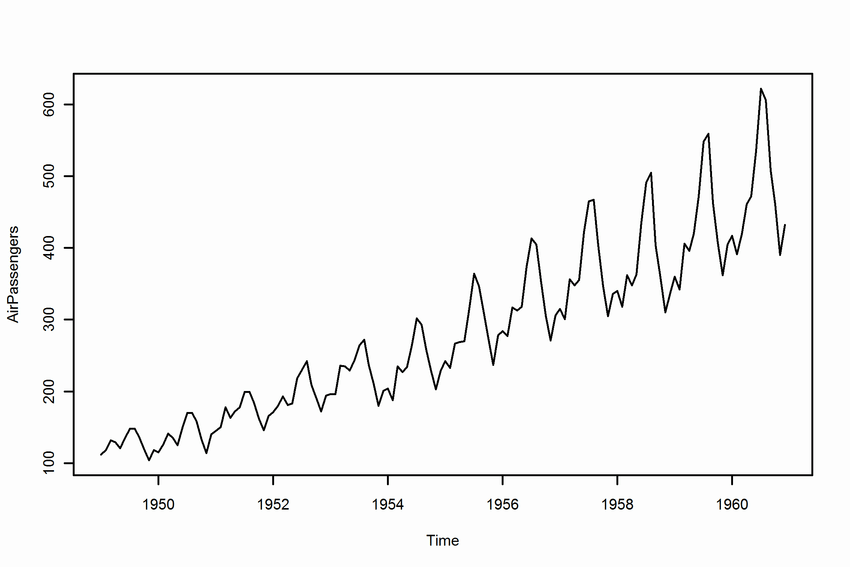
The below image is a commonly-used toy dataset of airline passengers over the years, and it exhibits both seasonality and an upward trend.
If you’ll notice, the peaks are consistently ~6 months apart.
And finally,
3. Cycles
Cycles are longer range seasons, e.g. years long.
Technically, you could lump cycles in with seasonality. But, IMO, it’s helpful to separate them.
My rule of thumb is that 2 year or greater length is a cycle.
So, how do we build models for this?
The short answer is, a lot of features. Most of these features will end up being “autoregressive” features, i.e. features based on the previous values in the time-series.
Then, you combine those features with external variables to your problem, like price.
If you’re curious what features end up looking like, I tweeted a bunch the other day.
These features are hard to implement w/o bugs, and it takes a lot of practice to figure out when to them.
Now, to takeaways:
Time-series feature engineering for XGBoost, 101:
• Lag features
• Rolling aggregations (usually std, var)
• Differences between lags/rolling features
• Group-level aggregations
• Rolling group-level aggregations
• Calendar features (dayofweek, month, etc)
• Rolling features by dayofweek, month, etc.
• Rolling features by group and calendar
• Expanding window features
• Expanding window by group and calendar
• Normalized features (i.e. % of greatest observed value)
• Predictions from stats models, like ETS
• Any external variables, like price
And many, many more (depending on your data)
There’s so much more to it. In addition to the above, mastery takes:
• Clever feature engineering
• Great EDA (e.g. Pandas) skills
• Great model evaluation skills, specific to time-series
Here’s a great resource I put together to learn it all:
CoRise - Forecasting with Machine Learning
Time-series forecasting is one of the longest-standing applications of machine learning, and is one of the most prevalent techniques used across all of industry (if not the most prevalent). And yet, d…
▻https://corise.com/go/forcasting-with-machine-learning-EBFH4